LabVIEWでプログラムを書くときの強みの一つは、ユーザーインタフェースであるフロントパネルをドラッグアンドドロップの操作だけで簡単に構築することができることだと思います。
本ブログのまずこれのシリーズでは主にプログラムのアルゴリズムの部分の書き方について解説してきましたが、アルゴリズムを知っているだけではプログラムは書けず、どのような選択肢があるかということも知っておく必要があります。
使い方集は、まずこれのシリーズでステートマシンまでの知識はある程度知っている前提で、アルゴリズム以外に関わるプログラムの書き方について紹介するシリーズです。
本記事ではデータタイプの中の一つである文字列データタイプについて紹介しています。
文字列データタイプの表示スタイル
文字列データタイプはまさに「文字」通り、文字を扱うデータタイプです。ファイル保存するという文脈では「テキスト」と表現されることも多いと思います。
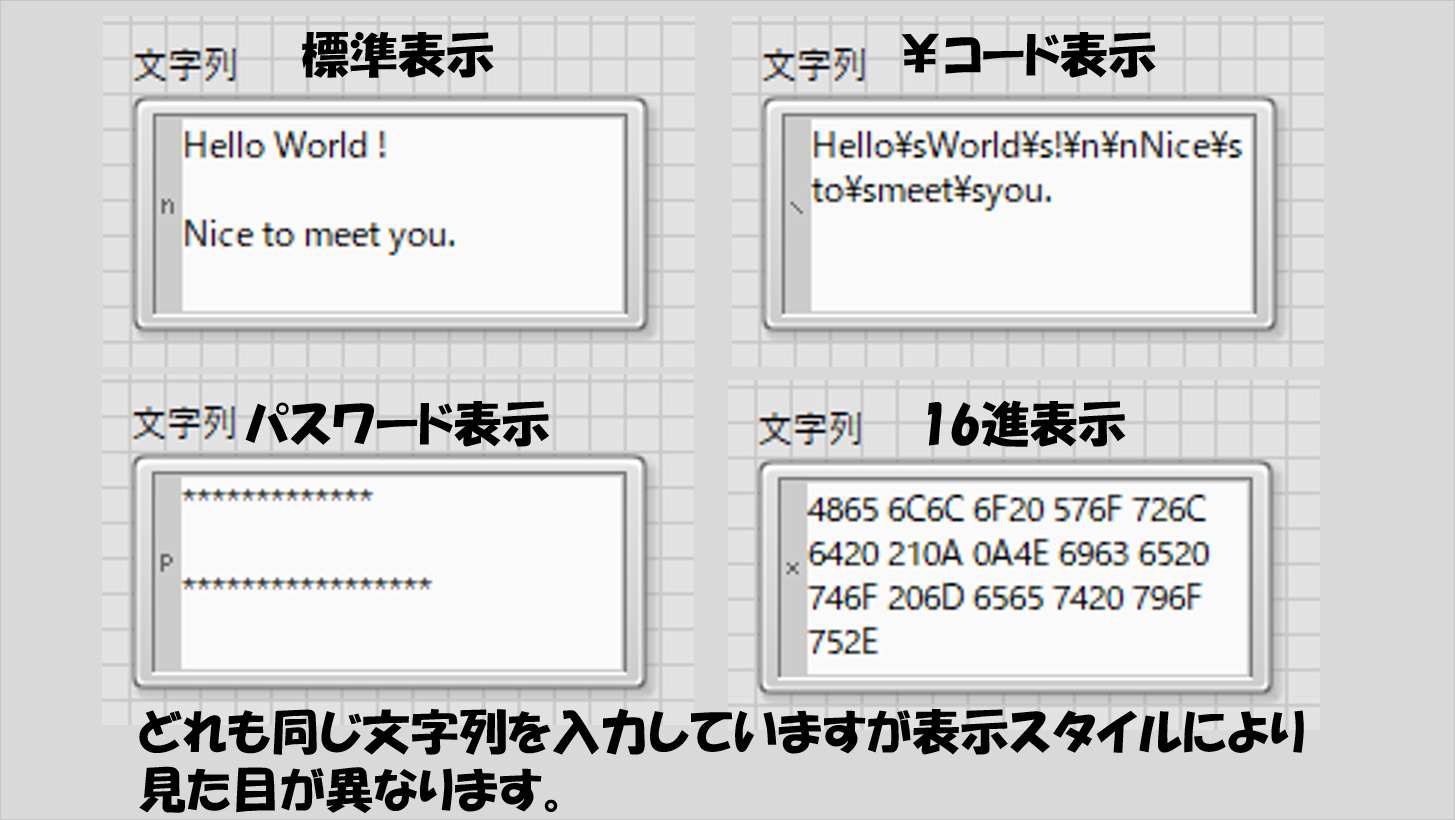
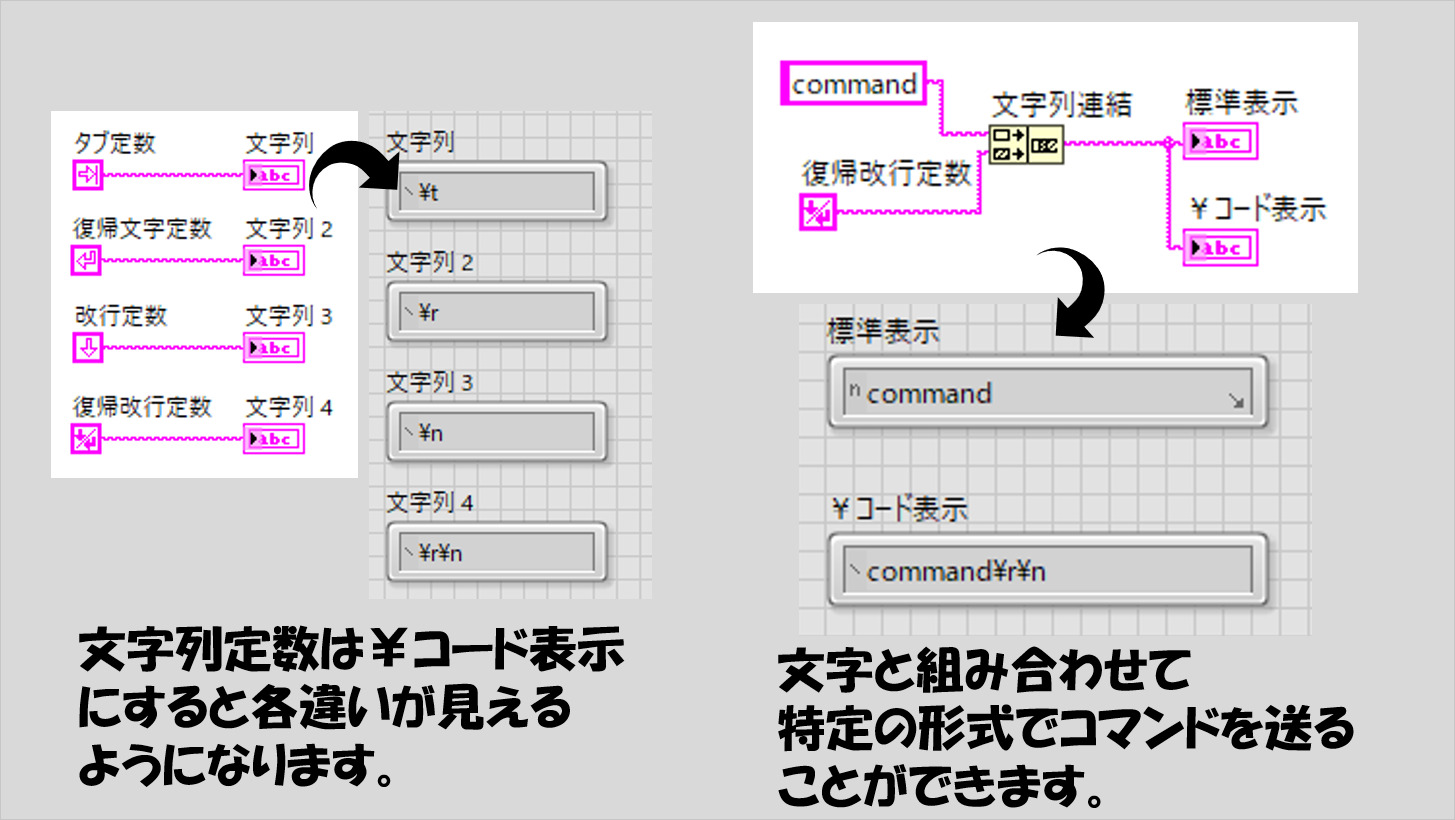
文字列には表示スタイルというものがあり、デフォルトの「標準スタイル」以外に¥コード表示やパスワード表示、16進数表示があります。
これらは、制御器や表示器を右クリックして表示スタイルの項目を表示できるようにすると選択でき、文字列が入力されている枠の左側に表れるボタンを使用して選びます。
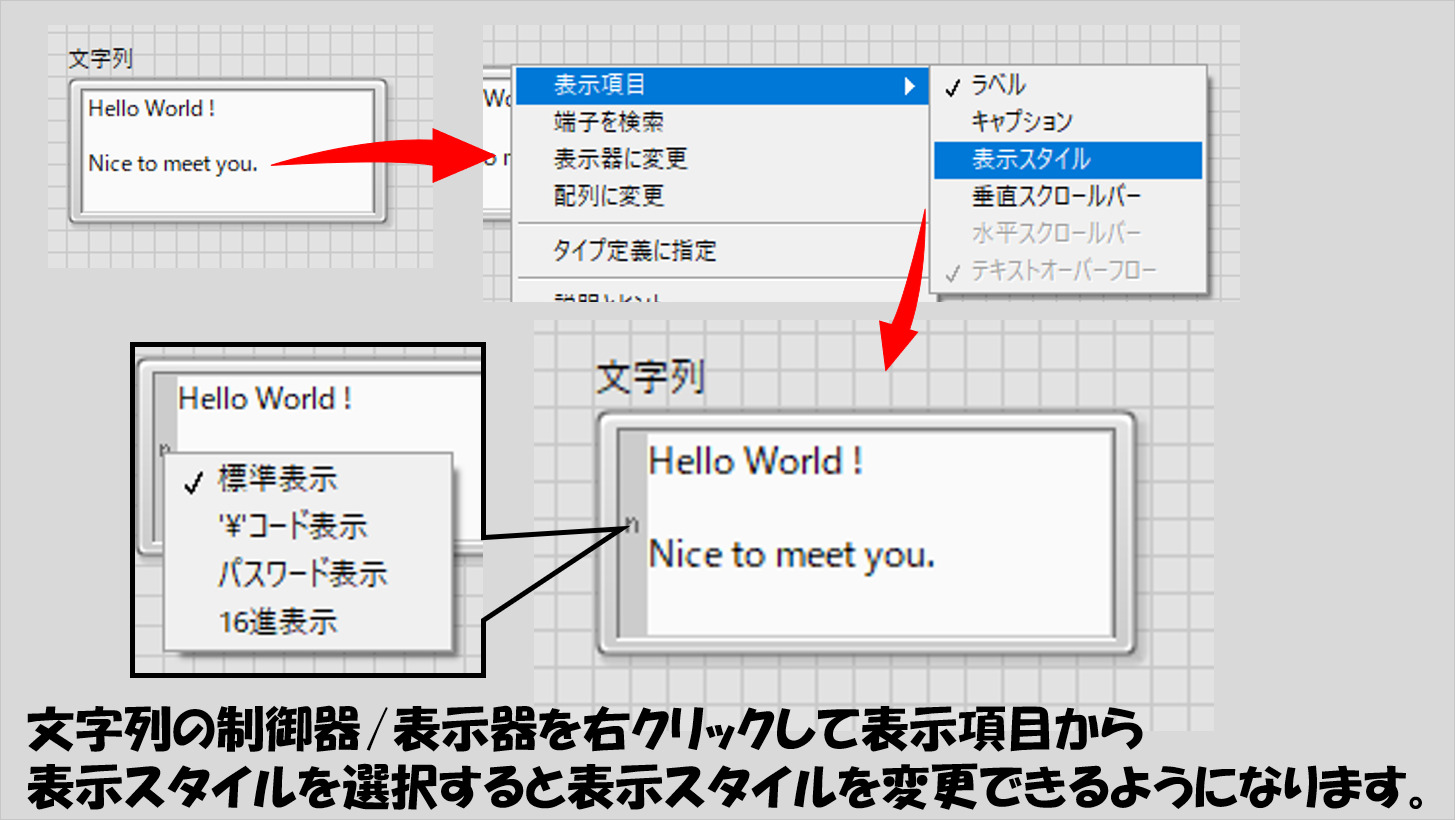
同じ文字列でも表示スタイルが異なると全然違う見た目となります。
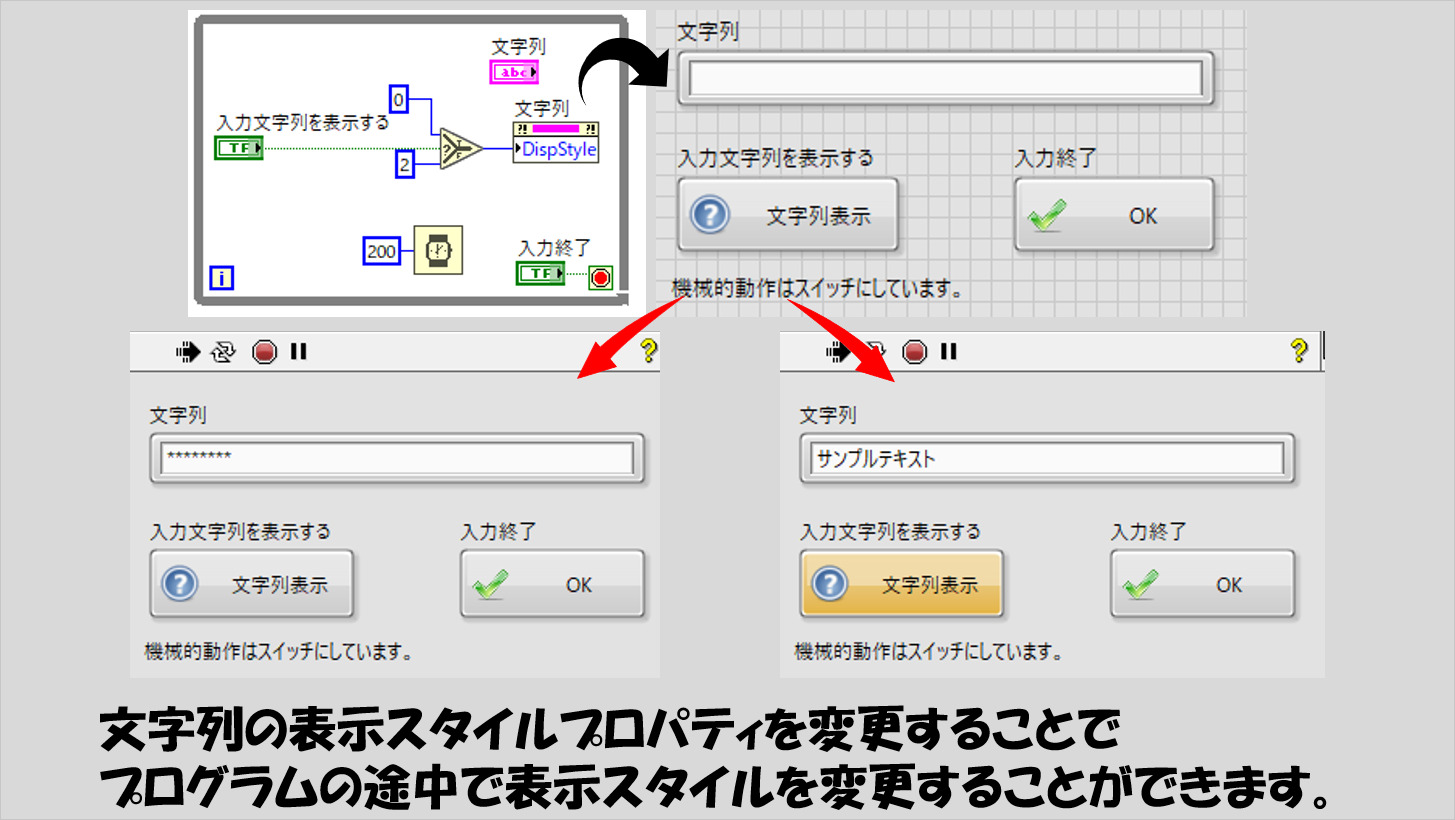
プロパティノードでプログラム実行中に変えられるので、例えば以下のように組むことでパスワード表示のON、OFFの切替といったことができます。
なお、¥コード表示については、計測器へのコマンド、特にシリアル通信における終端文字を扱う際に適しています。
文字列のパレットの中にいくつか文字列の定数がありますが、これらも¥コード表示で見ると違いが分かると思います。
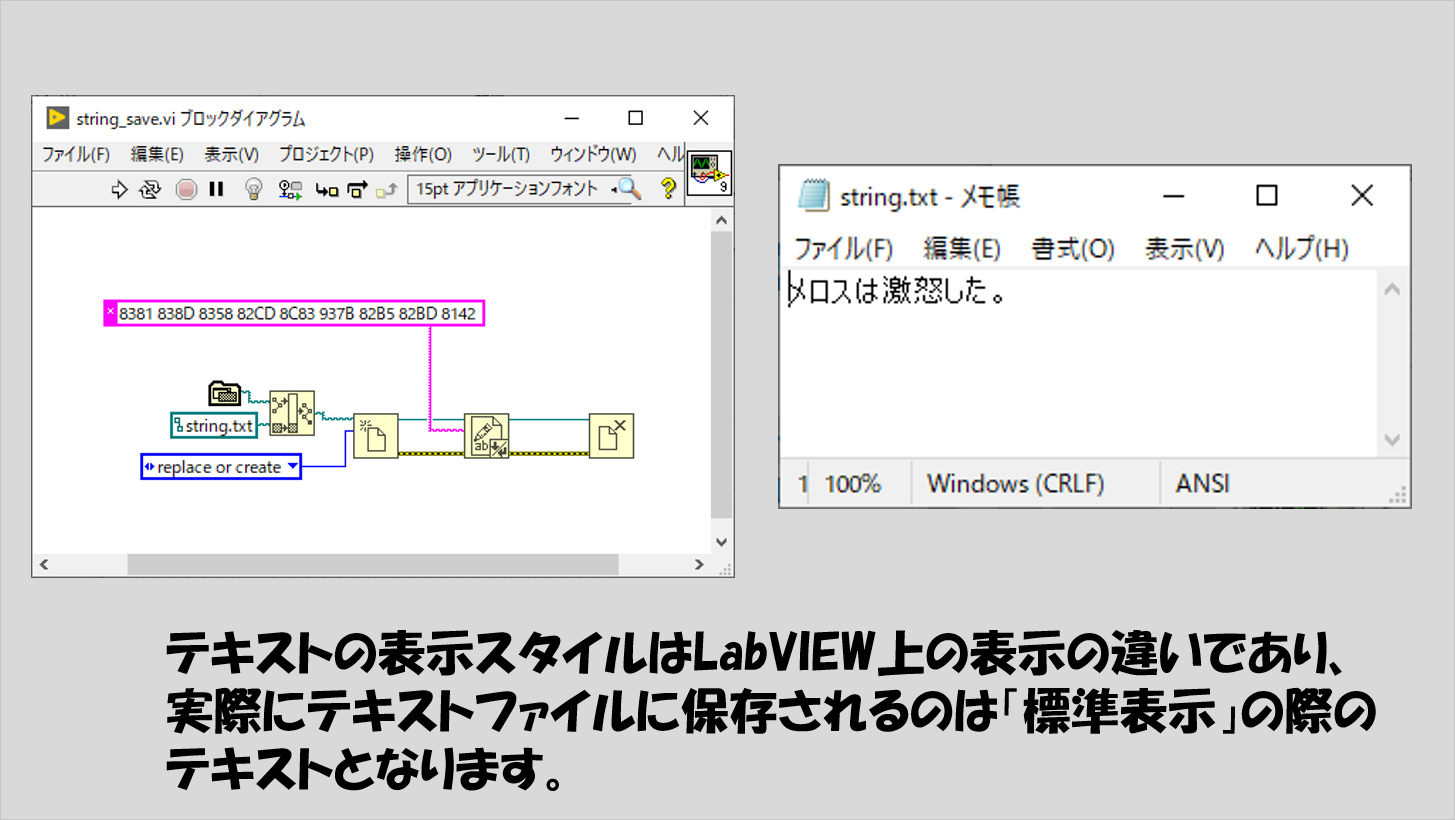
ちなみに、テキストとして保存する際には、これらの表示スタイルで表示した文字がそのまま保存されるわけではないです。
例えば、以下は「メロスは激怒した。」という文字をわざと16進表示した定数をテキストファイルに書き込むの関数に入力していますが、保存されるのは元々の文字で、16進表示したときの文字が保存されるわけではありません。
文字列操作あれこれ
プログラムの中で扱う数あるデータタイプの中で、文字列は数値の次くらいによく扱うと思います。
数値に対する操作は、関数パレットの中身を見ても結構直感的に分かりやすいものが多いと思いますが、文字列操作についてはぱっと見よくわからないものもあると思います。
全部の操作に一度に慣れる必要はないと思いますが、いくつか文字列操作の例として紹介していきます。
他のデータタイプを文字列にしたい
他のデータタイプをテキストデータとすることは、特にファイルにデータを書き込む際に頻繁に行う操作になると思います。
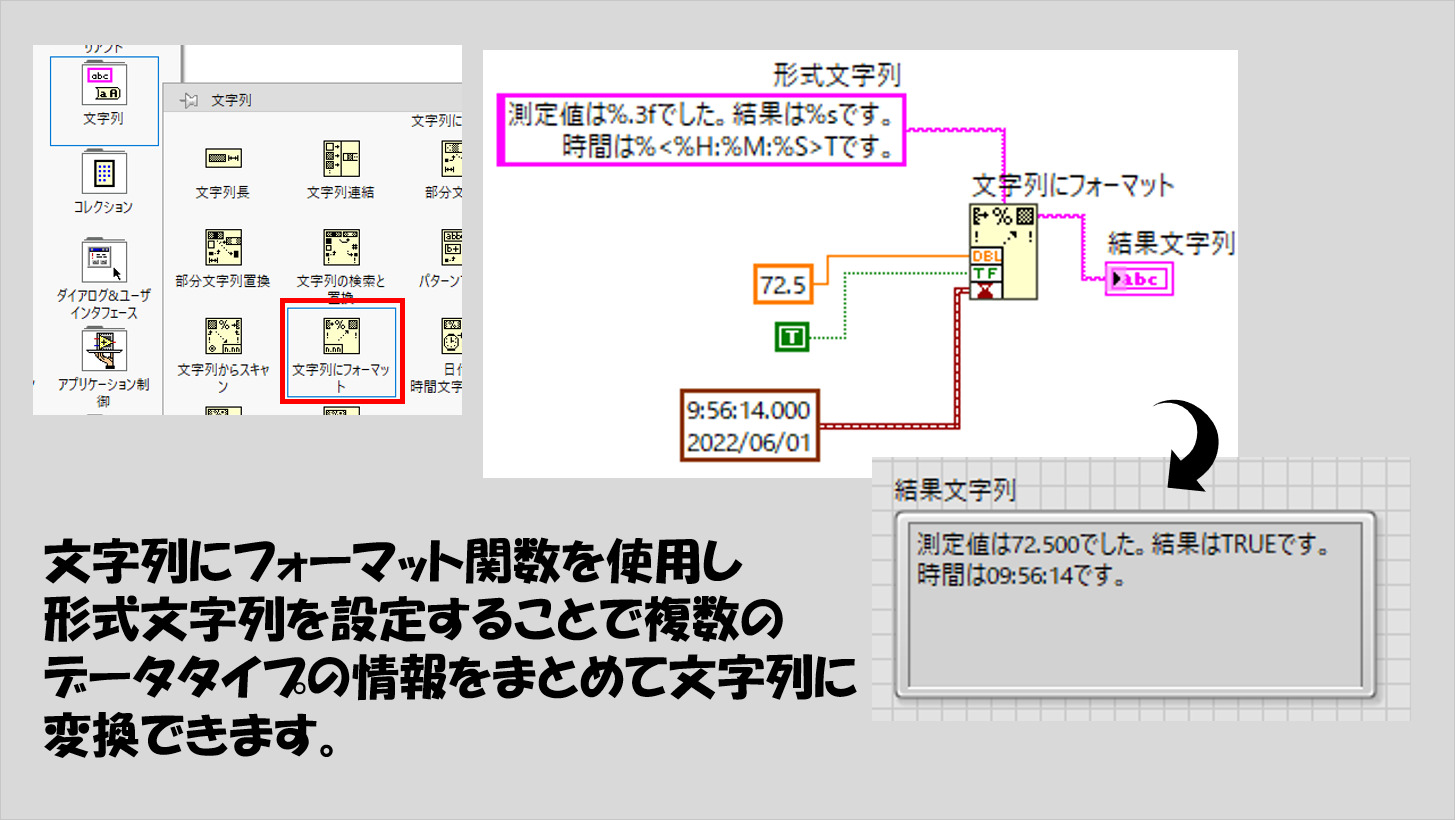
テキストにしたいデータは数値のこともあればブール、あるいはタイムスタンプの場合もあると思いますが、これらをそれぞれの「文字列へ変換」の関数を使って実装するより便利なのが文字列にフォーマット関数です。
形式文字列、という「どんなデータをどのように文字列へ変えるのか」を指定するお作法があり、「%」で示します。
例えば下の図の例の場合、形式文字列にある「測定値は%.3fでした。」の「%.3f」は「入力された数値データを小数点以下3桁まで表示する浮動小数点として文字列に変換」することを表わしています。
その後の「結果は%sです。」の「%s」は入力を文字列に変換するための指定で、文字列にフォーマットの上から二番目の入力がブールなので、このブールの値を文字列に変換しています。
%で指定した形式文字列の順番と、入力の上からの順番を一致させてそれぞれの変換形式の指定を行います。
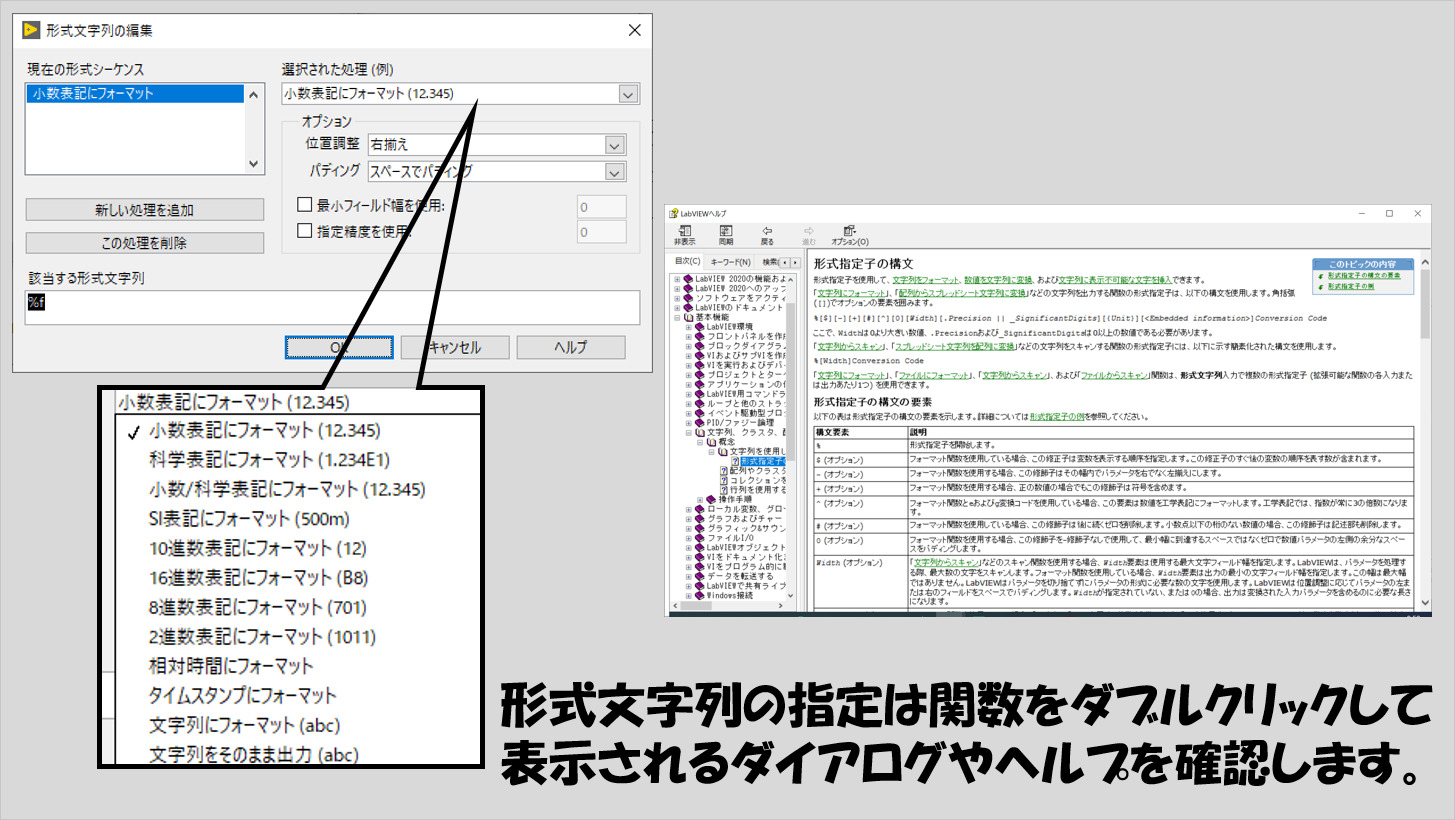
形式文字列の書式はヘルプを確認して書いていくこともできますし、ダブルクリックして構成することもできます。慣れればヘルプを見なくてもよく使う形式文字列は用意できるようになると思います。
似た関数で文字列からスキャンという関数がありますが、こちらはテキストデータを他のデータタイプに変換することのできる関数になっています。
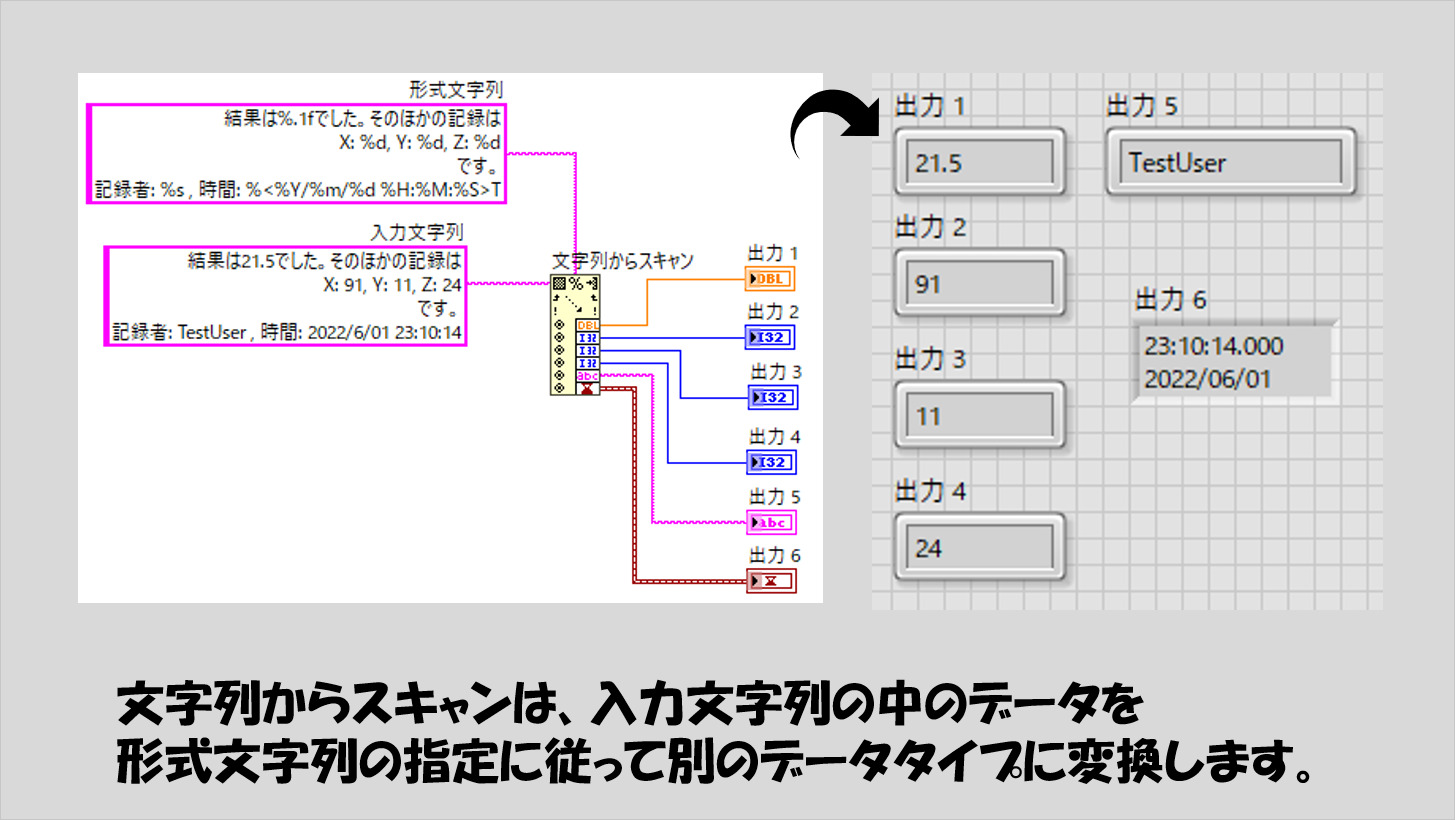
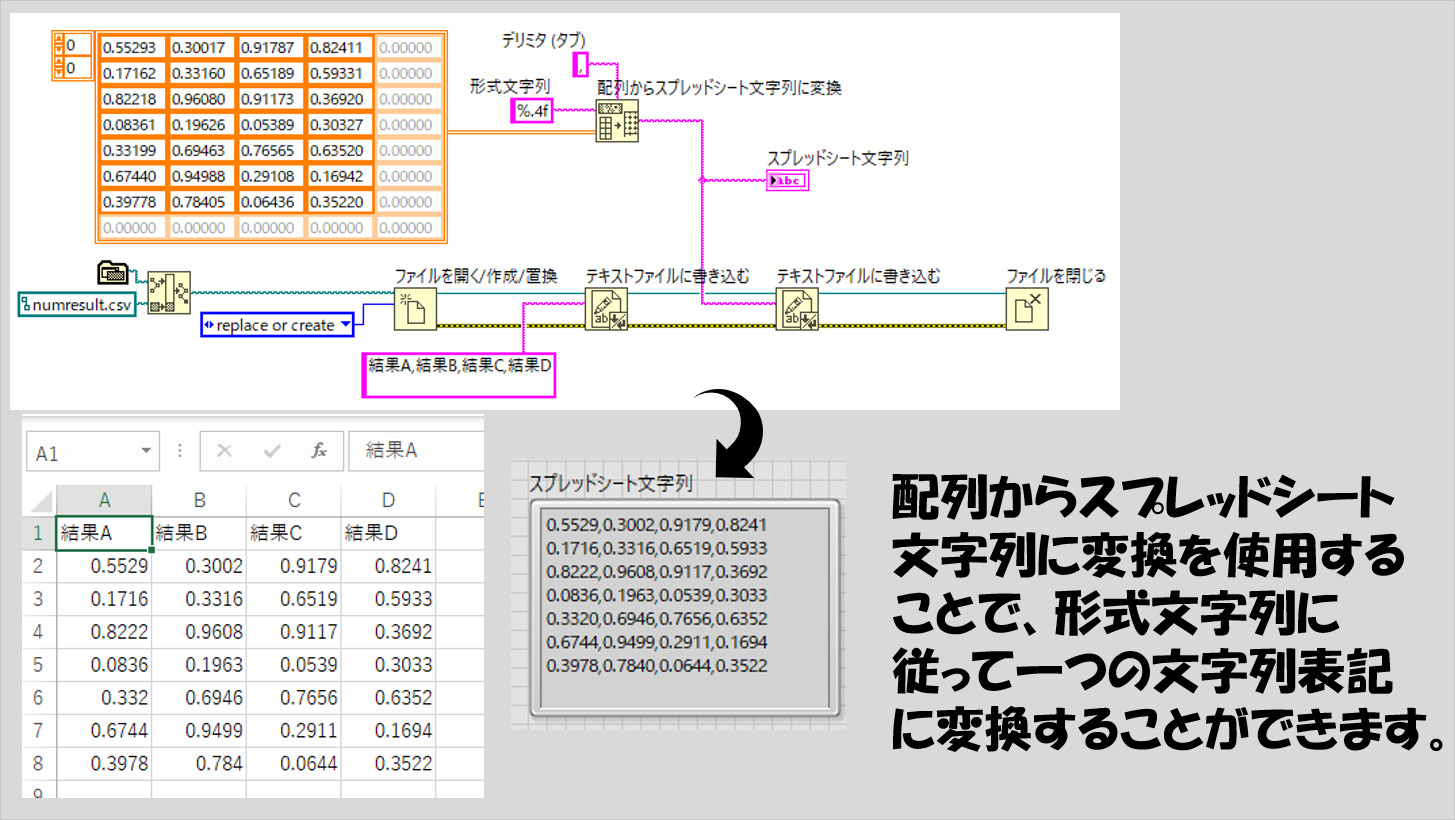
配列データをテキスト化したい
この関数もまた、ファイルにデータを書き込む際に役立ちます。
入力した配列(数値の配列か文字列の配列)を、指定したデリミタで区切った一つの文字列表現で出力してくれ、これをテキストファイルに書き込むの関数に渡すことができます。
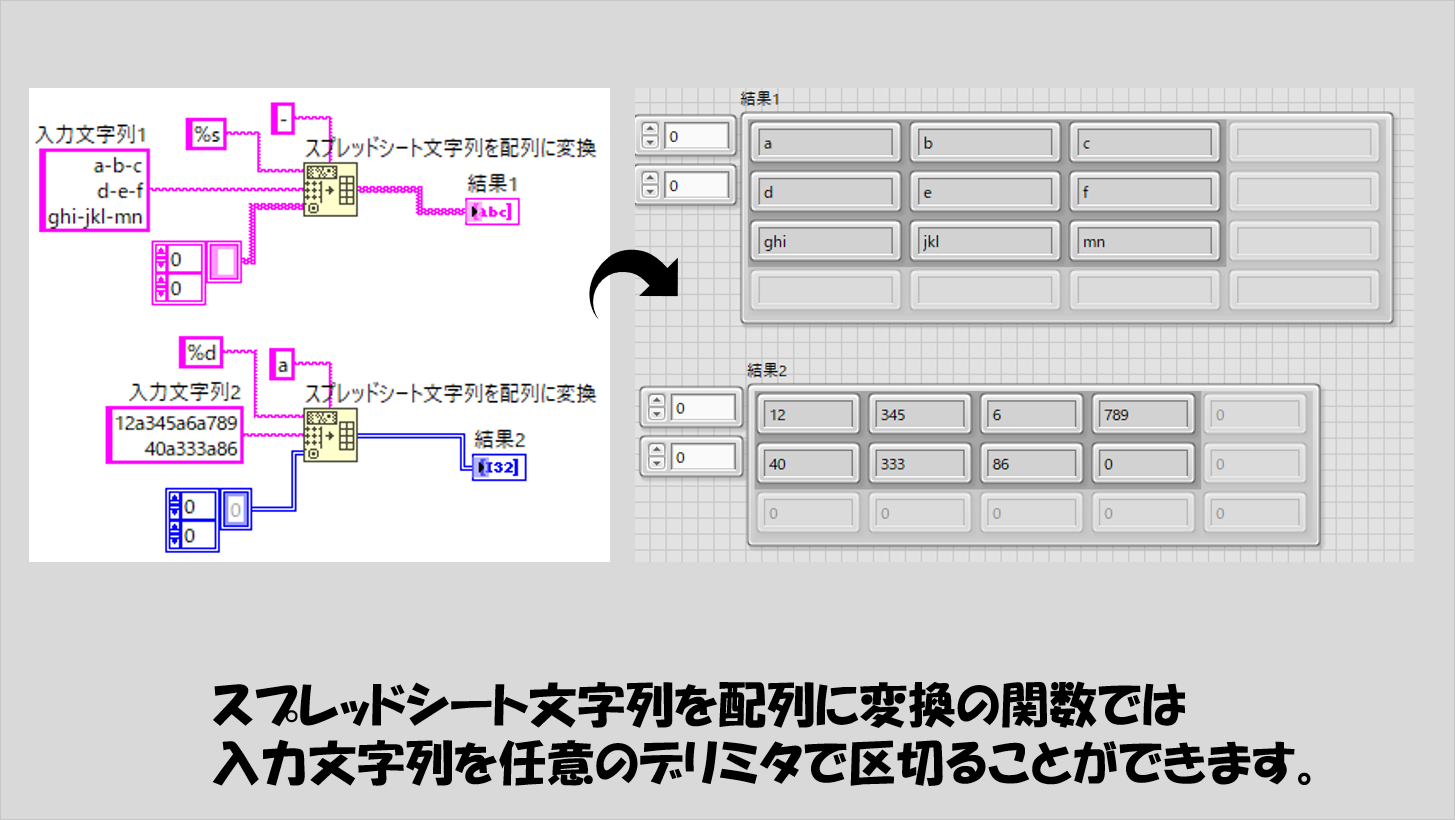
こちらもまた似た関数でスプレッドシート文字列を配列に変換という関数があり、特定のデリミタで区切られた文字列を、そのデリミタごとに要素として分解し配列として出力する関数になっています。
デリミタはデフォルトが「タブ」ですが、別に「,(カンマ)」でもよく、何なら「a」などの文字でも構いません。
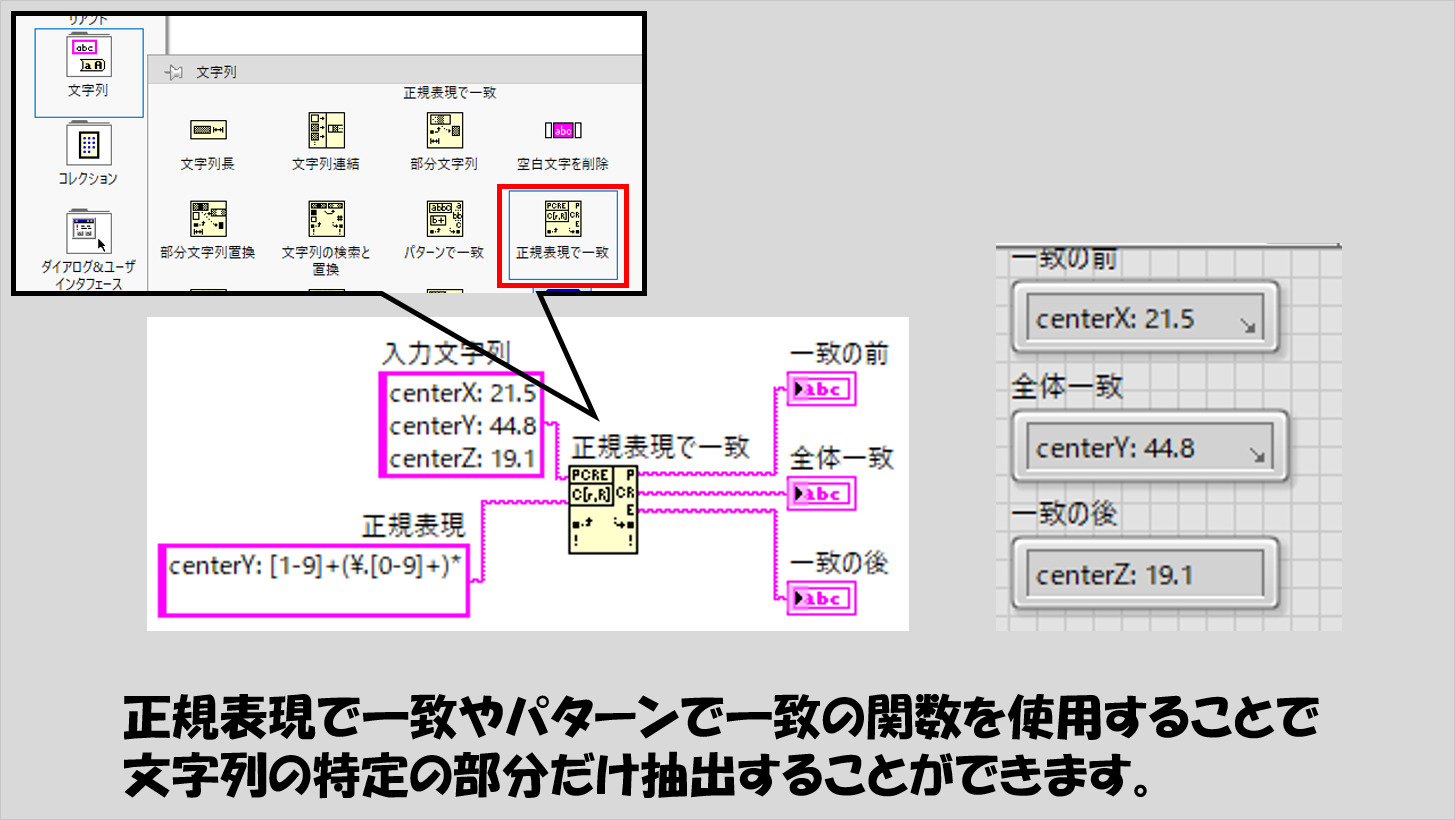
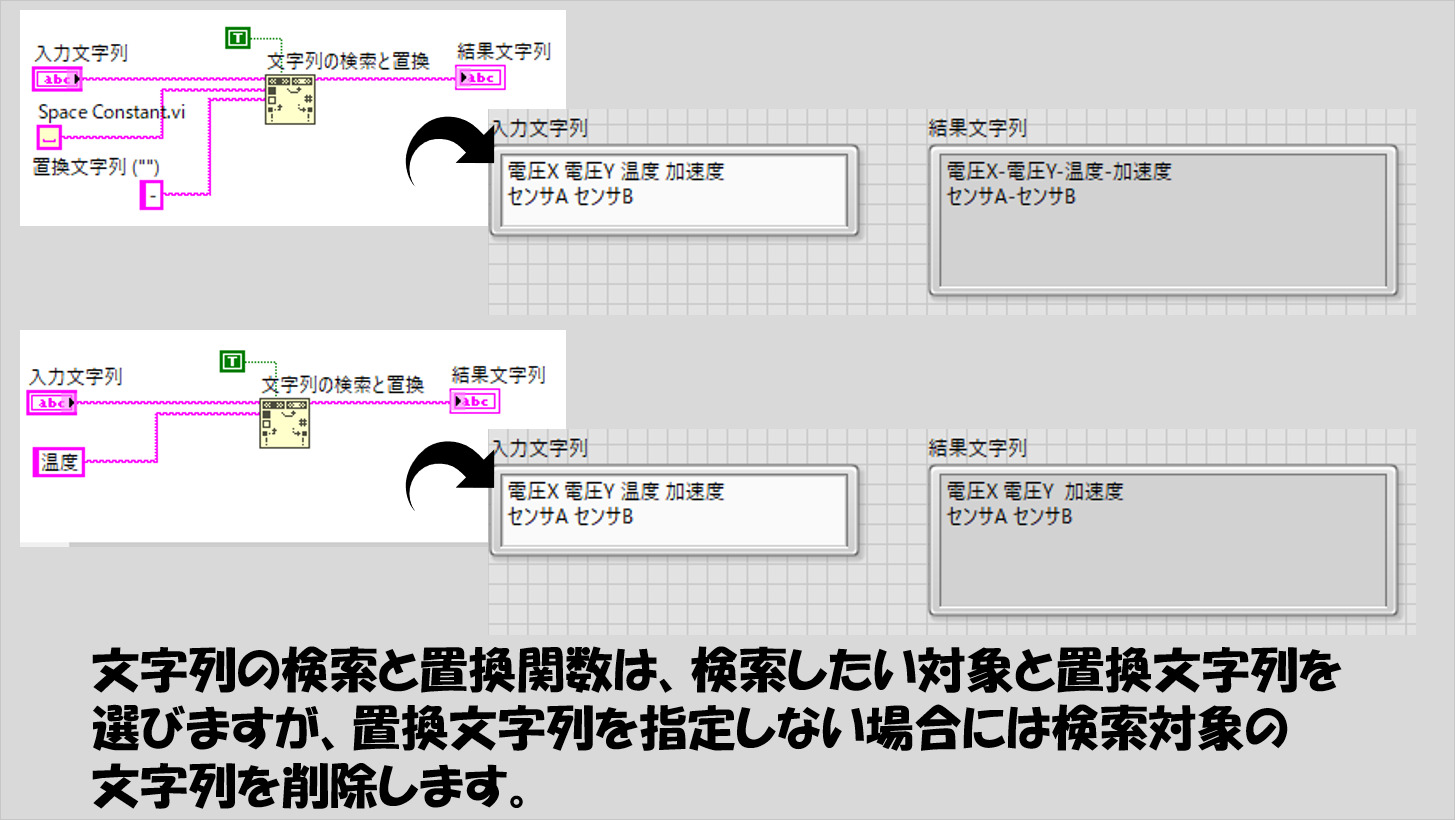
文字列の検索、置換や削除をしたい
文字の検索は、何かファイルを読み込んだ時の特定の部分を読み取りたい場合に使用できます。
正規表現やパターンで一致の関数を使うことで文字の中から欲しい情報だけを抜き取ることができます。
こちらも、正規表現という「どういう文字を検索したいのか」を指定するためのお作法があり、上記の「形式文字列」と比べるとややこしさが増します。
また、文字列の検索と置換の関数を使用することで、特定の文字を探してその文字を指定した文字と置換、あるいは探した文字を削除するといった操作ができるようになります。
こちらは正規表現で指定することもなく使用できるのですが、完全に一致したものしか検索にヒットしません。(その分、正規表現で一致やパターンで一致の方が汎用性は高いです)
文字を一文字ずつ配列要素にする
文字が羅列されているときにその文字一つずつを配列要素に変換したい場合には関数一つでできますよ、というものではなく処理が必要です。
おそらくもっと適切な実装があると思いますが、以下のプログラムのようにすると、ひらがな、カタカナ、そしてアルファベットが入っている文字列であれば一つずつを配列要素に入れることができます(漢字には対応していません)。
文字を区別するのに、「文字列をバイト配列に変換」関数を使用し、一つ一つの文字に戻す際には「バイト配列を文字列に変換」関数を使用しています。
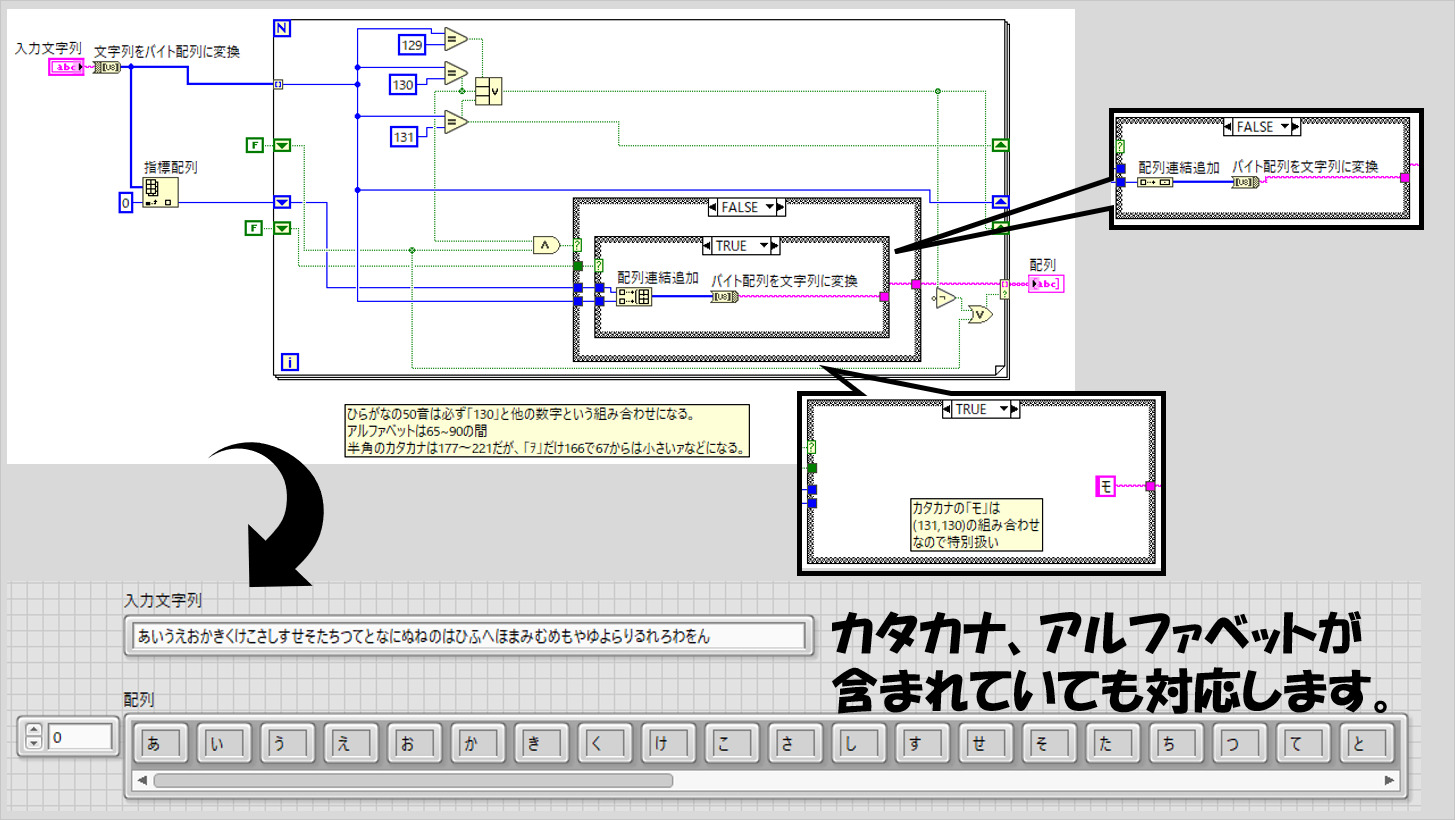
ひらがなであれば「130」と他の数字、カタカナであれば「131」と他の数字、というバイト配列が得られることから、例えば「131がきたらそれは一旦保留して次の要素と一緒によんで判断する、という仕組みにしています。
ただ、例外があり、カタカナの「モ」は(131、130)の組み合わせになっているのでこれだけ特別扱いしています。
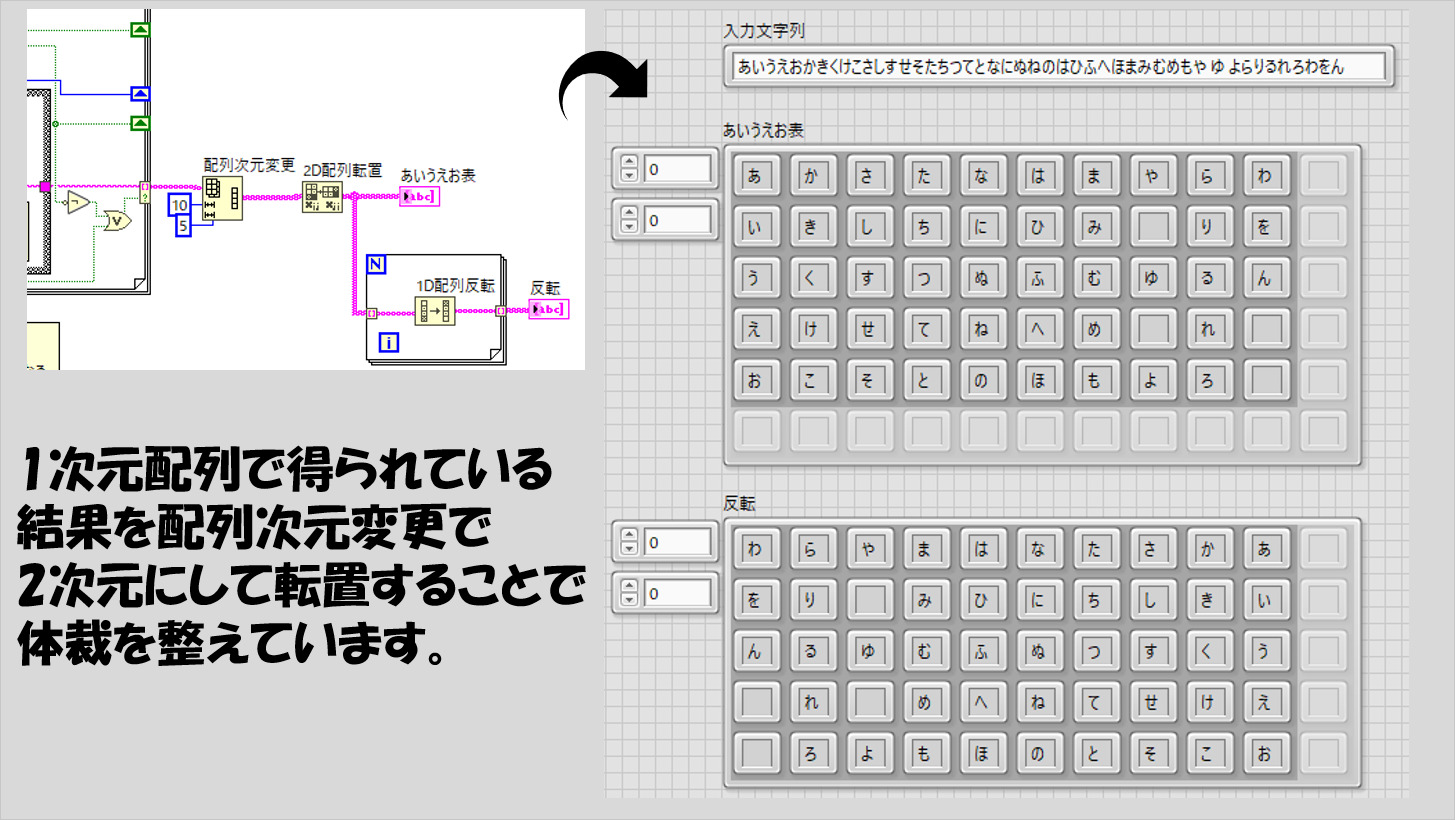
50音表を表わすとしたら以下のような感じになります。
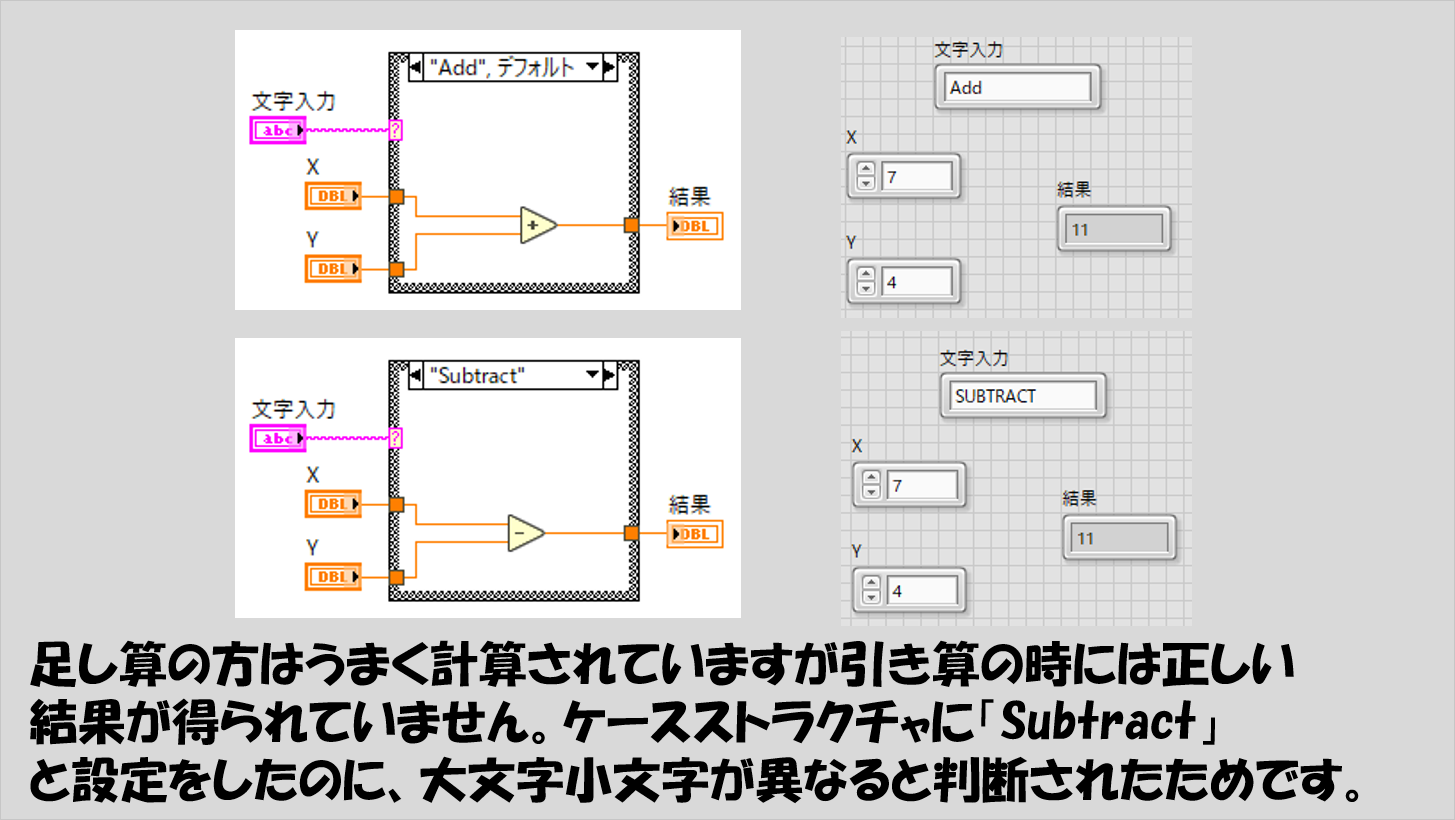
ケースストラクチャの扱いに注意する
プログラムで、いわゆる条件分岐を記述するためにLabVIEWではケースストラクチャを使用します。
ケースストラクチャのケースセレクタには数値やブールなど他のデータタイプも入りますが、文字列も配線することができ、入力された文字列と同じケースラベルの中にある処理が実行されます。
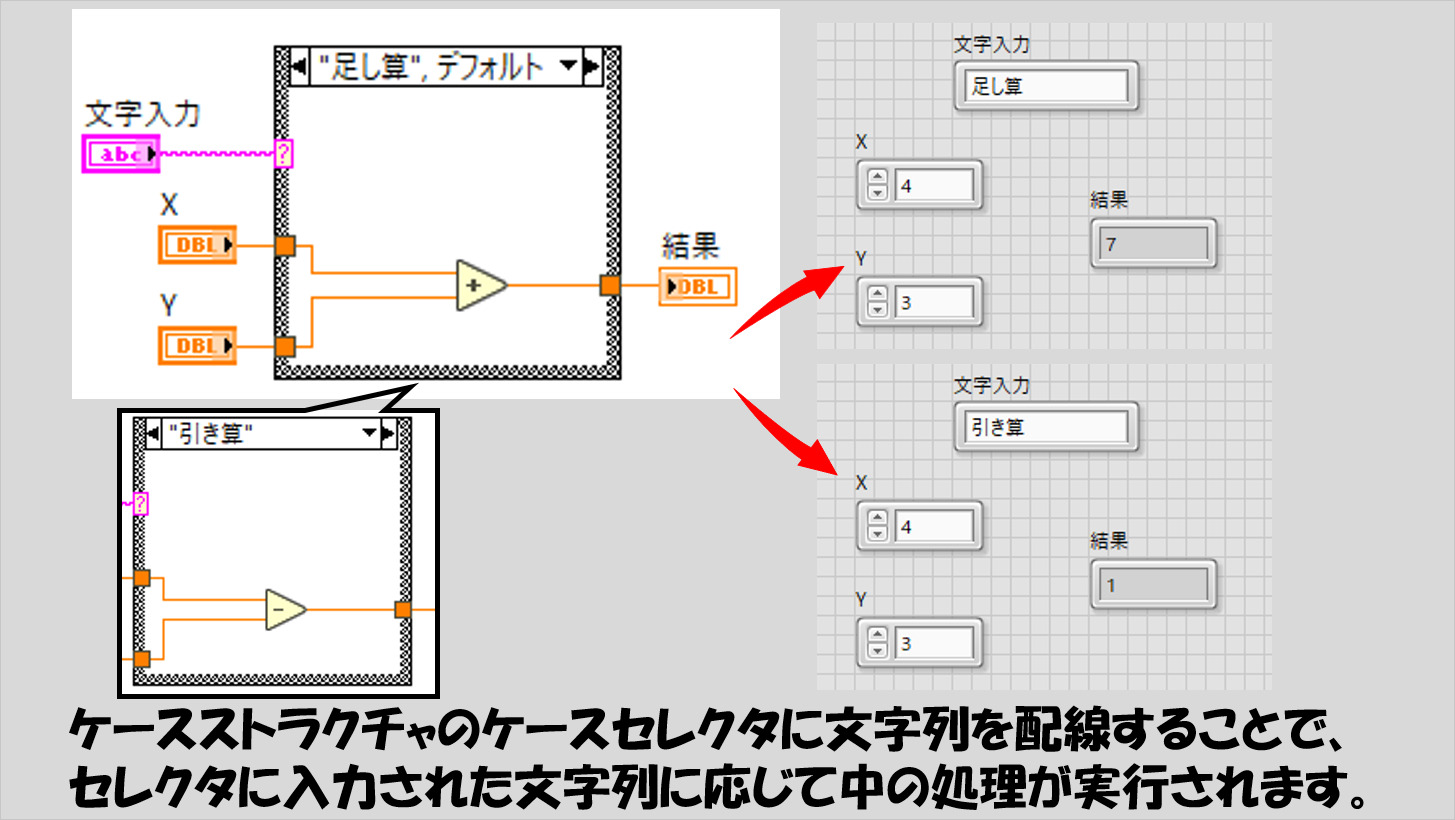
このとき、日本語であれば関係はないのですが、アルファベットで記述する際には、デフォルトでは大文字小文字が区別されます。
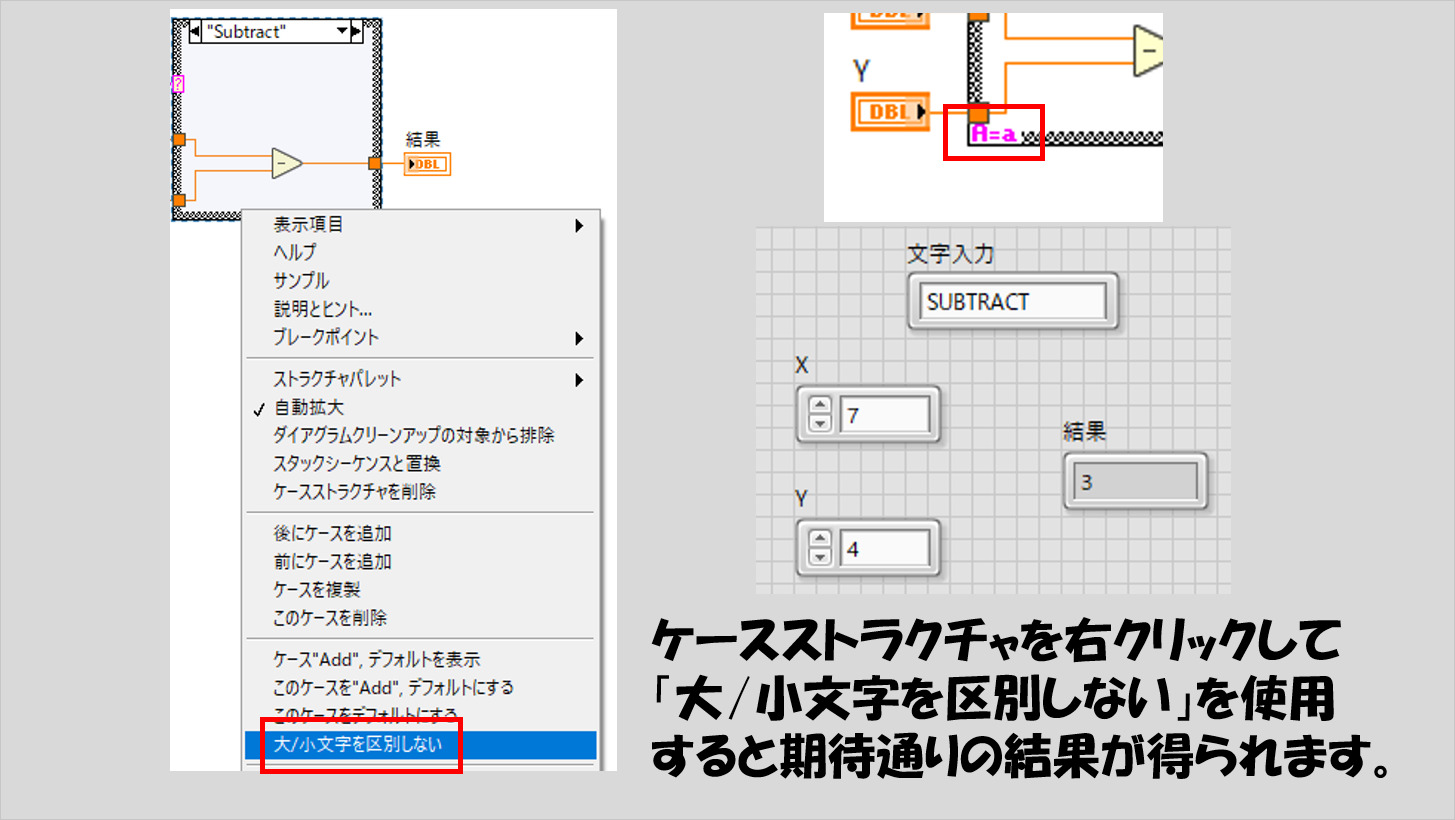
もし区別したくない場合には、ケースストラクチャを右クリックして「大文字/小文字を区別しない」を使用します。なお、この選択肢はケースセレクタに文字列が配線されているときのみ表れます。
この区別しないという設定にすると、ケースストラクチャの左下に特別なマーク(下の図の赤枠)が表れます。
あるいは、プログラム作成時にはケースラベルは全て大文字か小文字で書くようにルールを決めておき、文字列の関数で大文字あるいは小文字に変換する方が便利な場合があるかもしれません。

本記事では、LabVIEWにおける文字列データタイプの扱い方について紹介しました。文字列データ自体は単純ですが、文字情報はファイル保存やユーザーへの表示など使われる場面が多くブロックダイアグラム上でこの文字情報をどう扱うかについては慣れが必要な部分があると思います。この記事で紹介した内容が少しでも役に立てばうれしいです。
ここまで読んでいただきありがとうございました。
コメント