この記事では、LabVIEWでハードウェア操作を行う際に「効率の良い」プログラムを書く上で知っておくと便利な、キューを使用したプログラムの組み方とその例を紹介しています。
例としてNational Instruments社が提供しているハードウェアであるDAQを挙げていますが、同じ考え方は他のハードウェア操作にも適用できると思います。
なお、本記事では基本的なDAQのプログラムをExpress VIあるいはDAQmx API(関数)で書くことは扱っていません。別記事で扱っているのでよければそちらを確認してみてください。

LabVIEWのデータの流れとループの仕組み
まず、本記事で紹介する内容がどういった場面で役立つかをよりイメージしてもらえやすいように、LabVIEWのプログラムにおける
- データの流れ
- ループの仕組み
について紹介していきます。
データの流れ
これは、ハードウェアを操作するプログラムに限らず、LabVIEWでプログラムを書く上で必ず押さえておかなければならない超基本的なお話です。
例えば、テキスト言語であれば、基本的にプログラムは上から順に実行されていきます。実行される順番がある、ということですね。
これはグラフィカルプログラミング言語とされるLabVIEWでももちろん同じく、実行の順番という考え方が存在します。しかし、LabVIEWはアイコンで表された関数を並べてプログラムを作るため、「上」がありません。
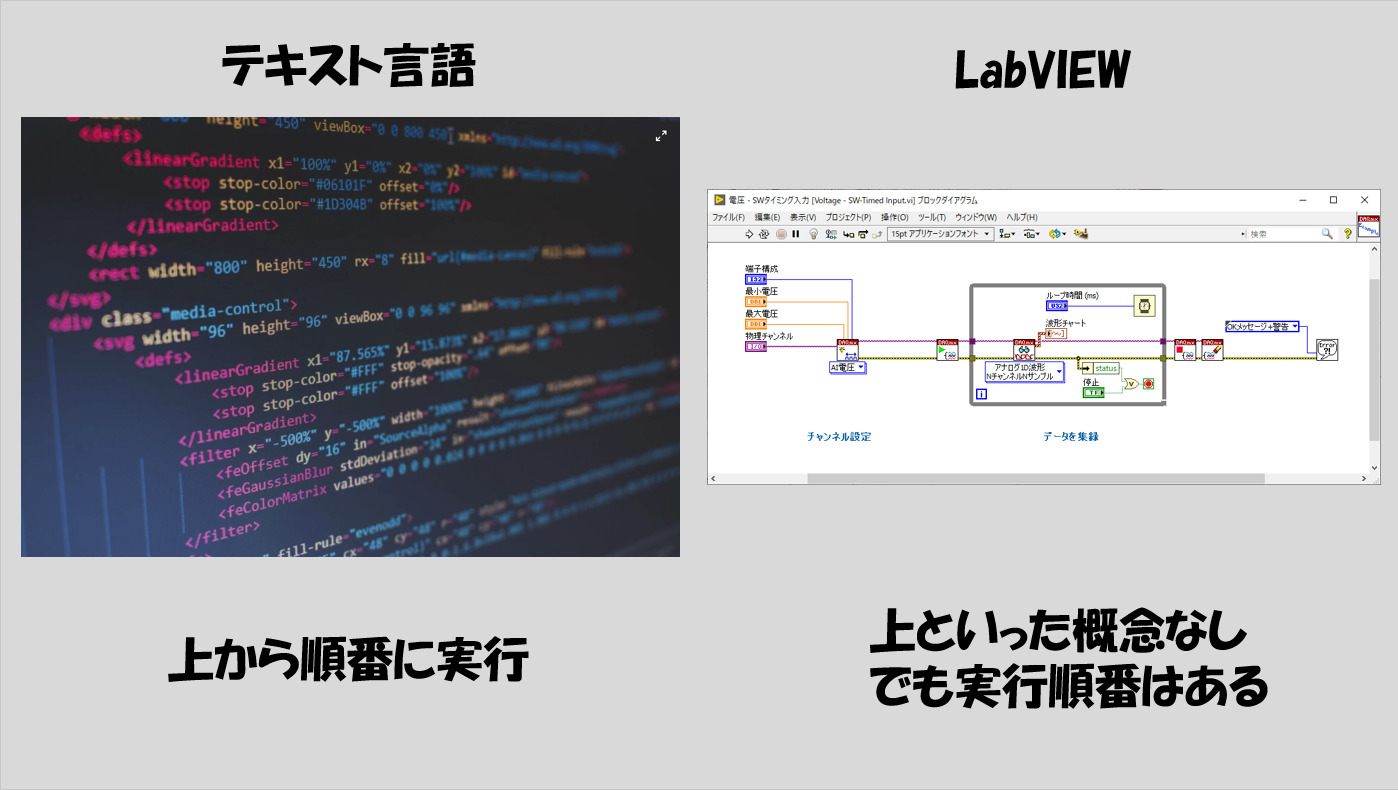
ではどうやって順番が決まっているかというと、ある絶対的なルールがあり、これに従って順番が決まります。
「ある処理は、その処理に配線された入力データがそろってから初めて実行され、処理が終わってから結果を出力する」
順番を決めるのはこれだけです。全てこれで決まります。
以下に具体的なプログラムで例を示しています。シンプルなものとしては四則演算です。
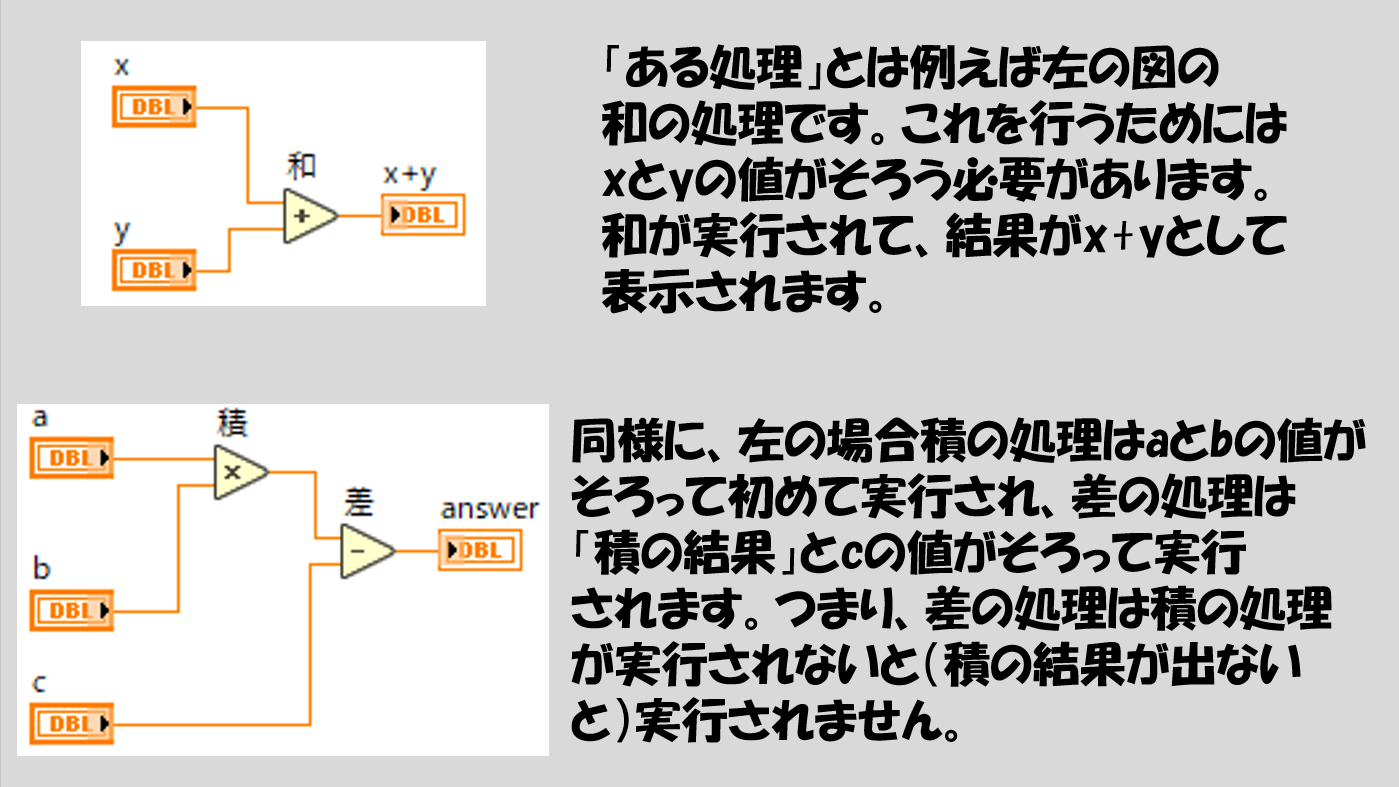
実際は四則演算に限らず、LabVIEWで書くありとあらゆるプログラムが同じルールに従います。
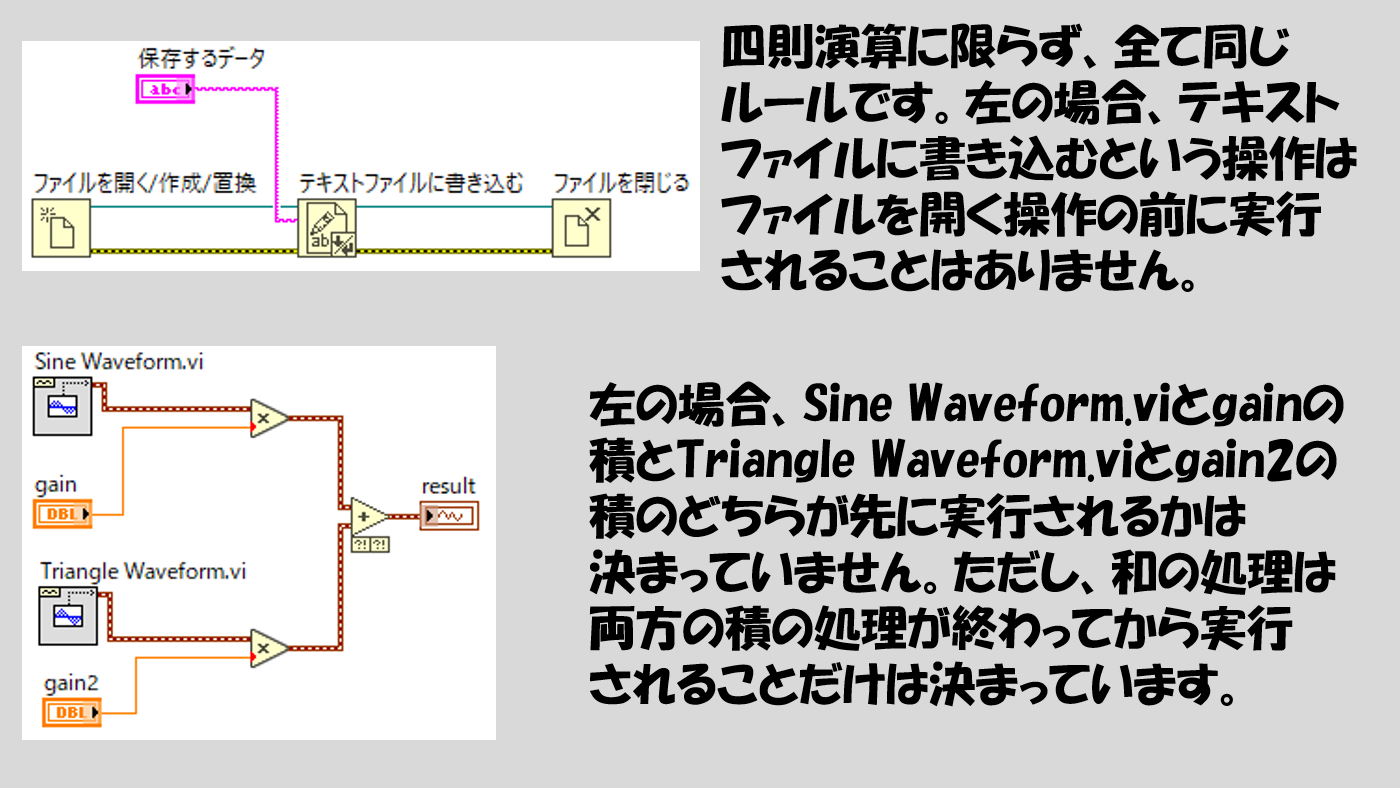
では例えばこんな場合はどうでしょうか?
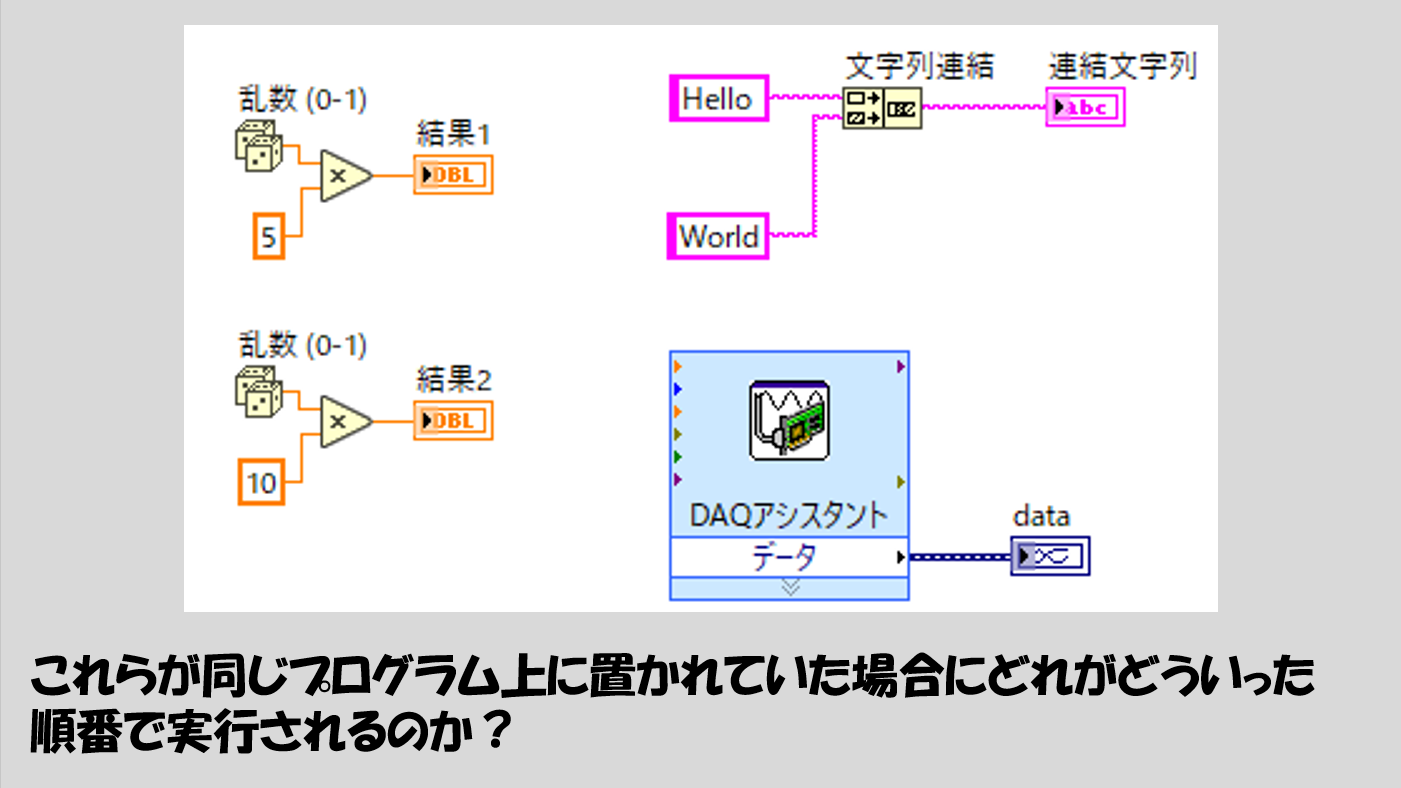
上のルールに当てはまらない状態になっています。よって答えは「どちらが先に実行されるかわからない」です。
もちろん、とても厳密なことを言えばどれかが先に実行されてはいて、デバッグのツールを使用すればあるタイミングでどのような順番で実行されるか確かめることはできます。
が、仮に確認したとしても、毎回確実にその順番が保証されるわけでもなく、実際、同時並行的に実行されると思ってもいいと思います。
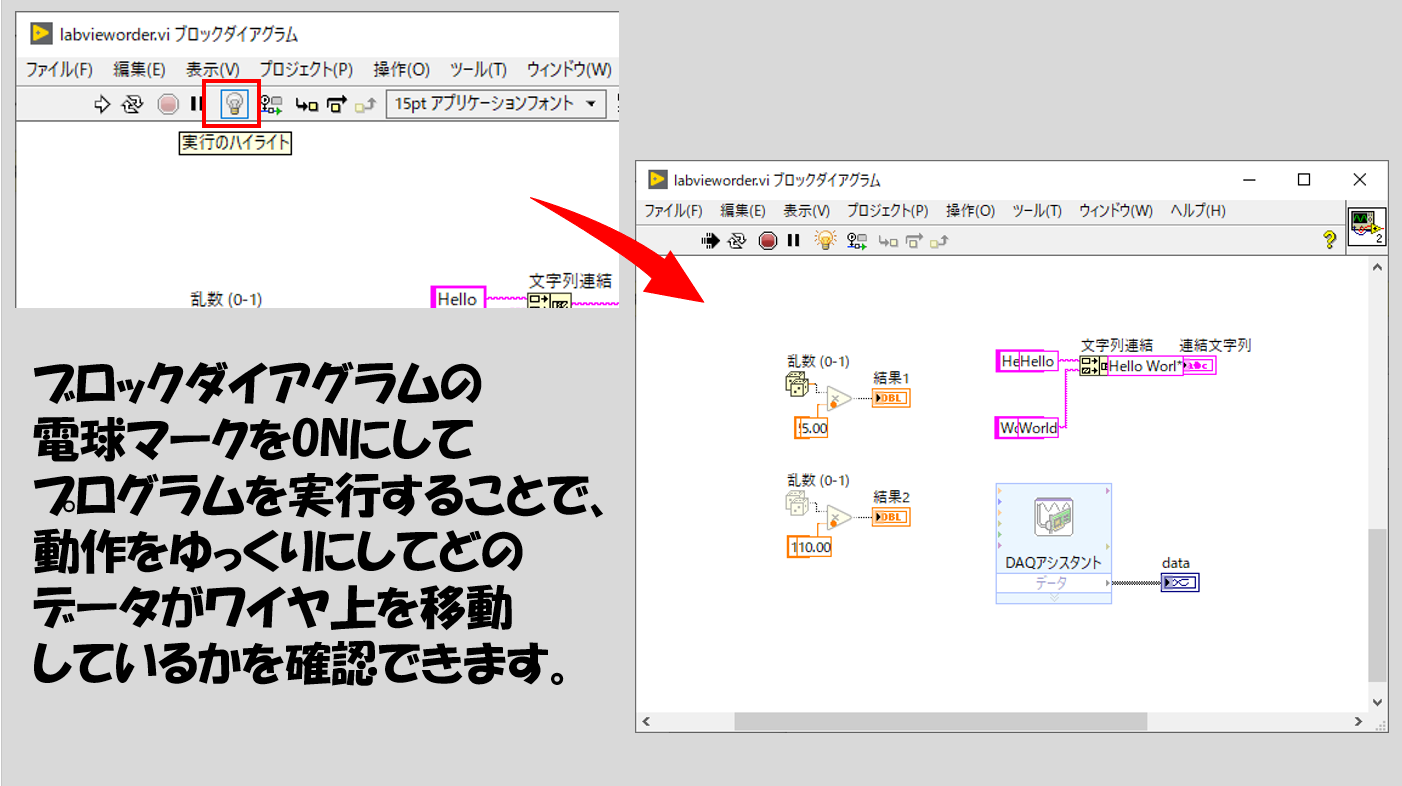
別の言い方もできて、「ワイヤが配線されていたら順番が決定されてしまう」「順番を決めたかったら、しっかりとルールに沿ってワイヤ配線をする」ということです。
後の内容とも絡めて説明すると、この構造は何も関数に限りません。繰り返しの構造、いわゆるループについても適用されます。
例えば、ある条件が満たされるまでずっと処理を繰り返すWhileループが複数ある場合の実行の順番も全く同じ考え方で決まります。
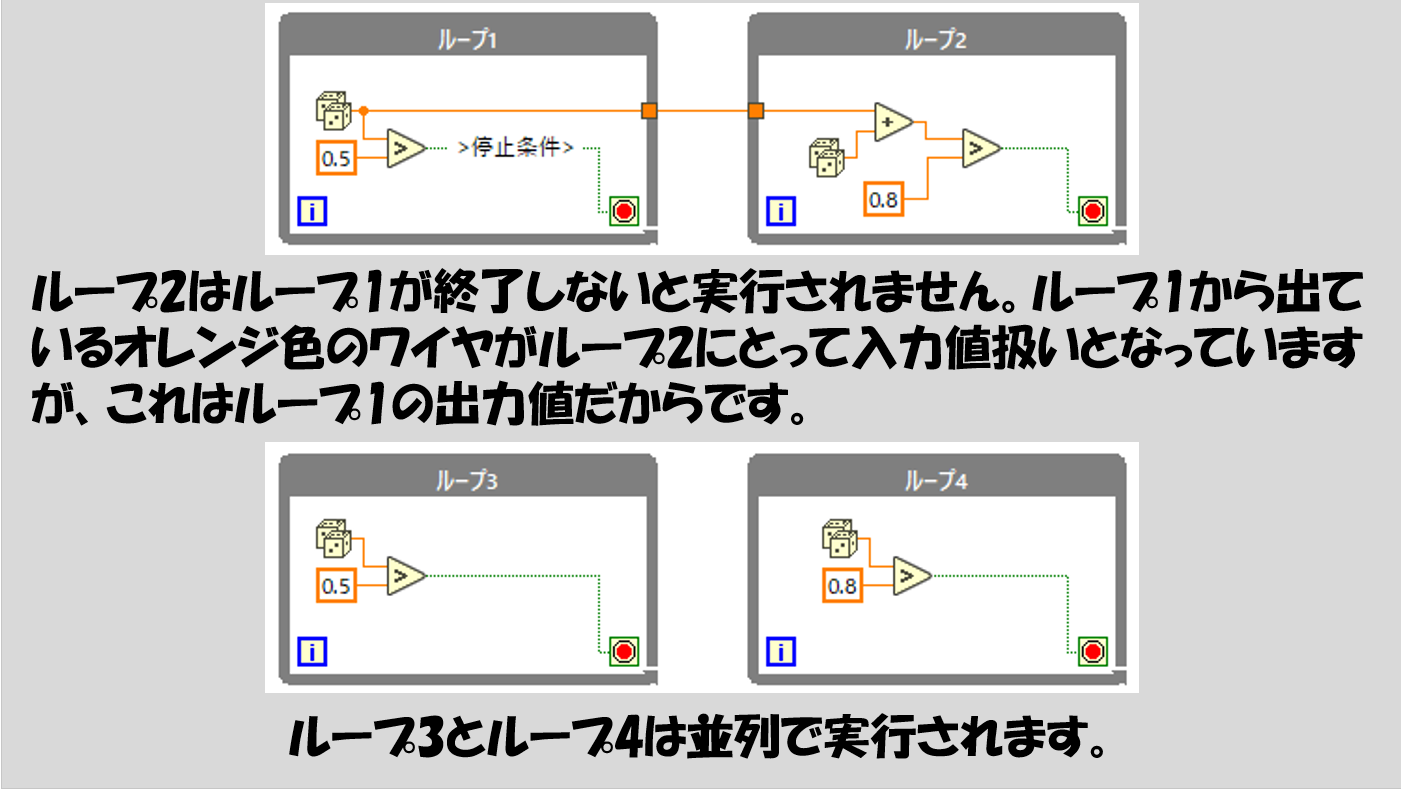
ワイヤ配線によって順番が決まっているわけではないWhileループは、LabVIEW上で並列で実行されます。(並列実行が簡単に書けるのがLabVIEWの強みとも言えます)
このことが効率のいいプログラム作りに大きく関係します。
ループの仕組み
データの流れを踏まえたところで、もう一つ、知っておく必要があるのはループの仕組みです。ループ、つまり何かを繰り返すという動作を行うことになりますが、考える必要があるのは
「ループの中に入っているすべての処理が終わらないと次のループに進まない」
という原則です。
そもそもループ自体を知らないよ、という方はこの先の話は少し難しいかもしれません。グレーの線でぐるっと囲まれているものがWhileループと呼ばれ、この中に書かれた処理を何度も繰り返すと覚えてください。
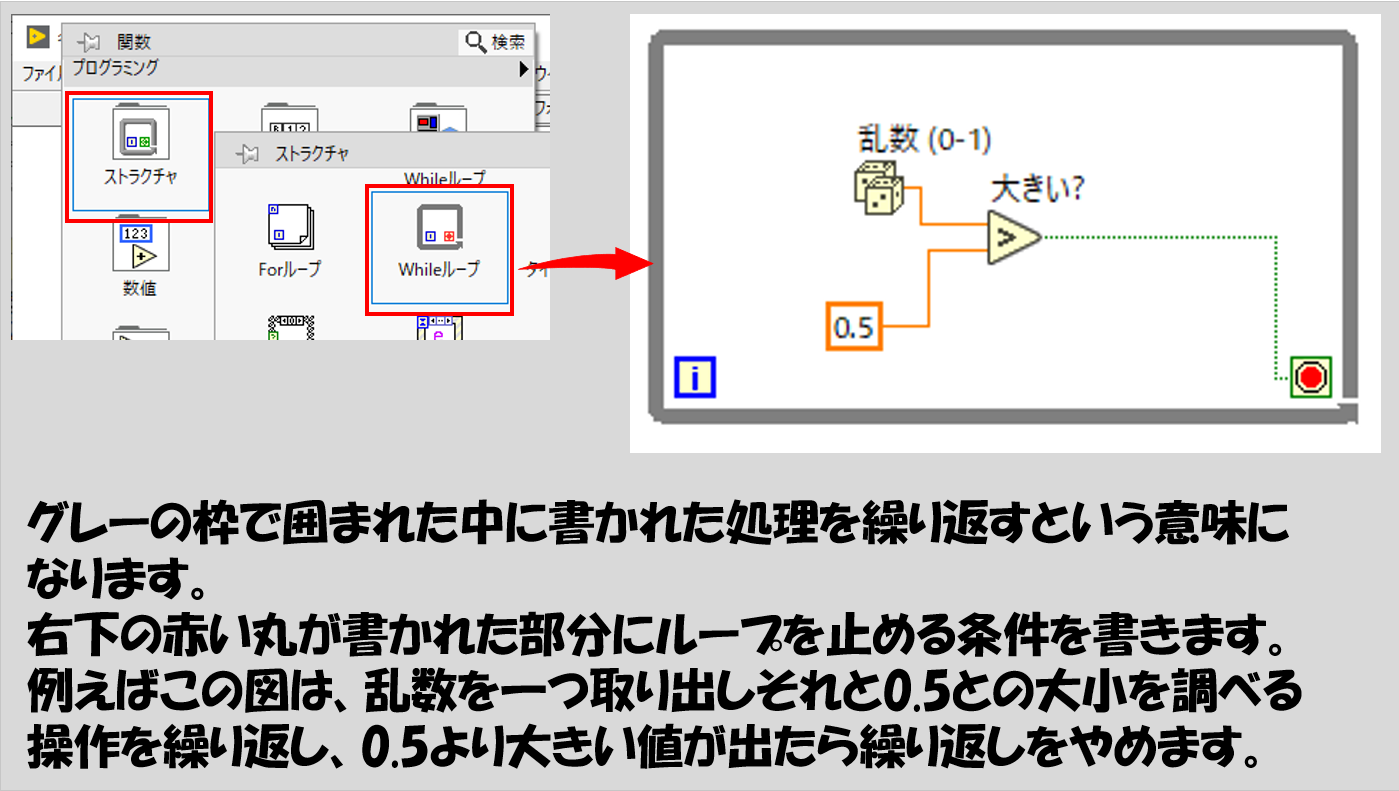
考えてみたら当たり前で、ループの中に入れている以上繰り返したいと思っている処理があるのにその一部をやらない状態で次のループに進むわけないんです。
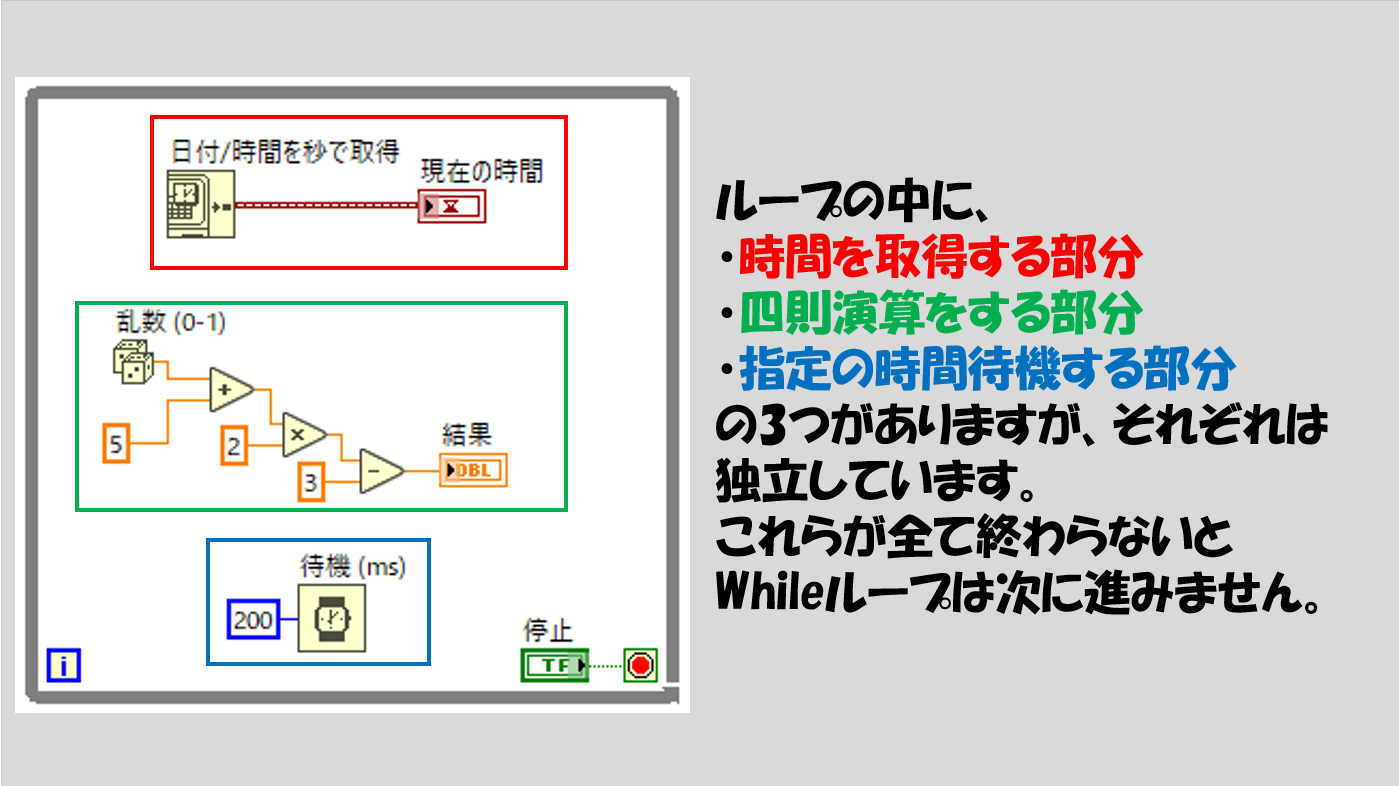
そんなことを考えると、こんな場面に遭遇する可能性があります。
「例えば1秒間に1000点取得する測定があって、データに対する処理全体に1秒の時間がかかる場合にどうすればいいか」です。
データに対する処理、は例えばFFTをかけるとか保存するとかそういったことですが、それらの処理は当然データを取る前にはできないため、データを取った後に実行される必要があります。そしてこれを繰り返すという場面を想像します。
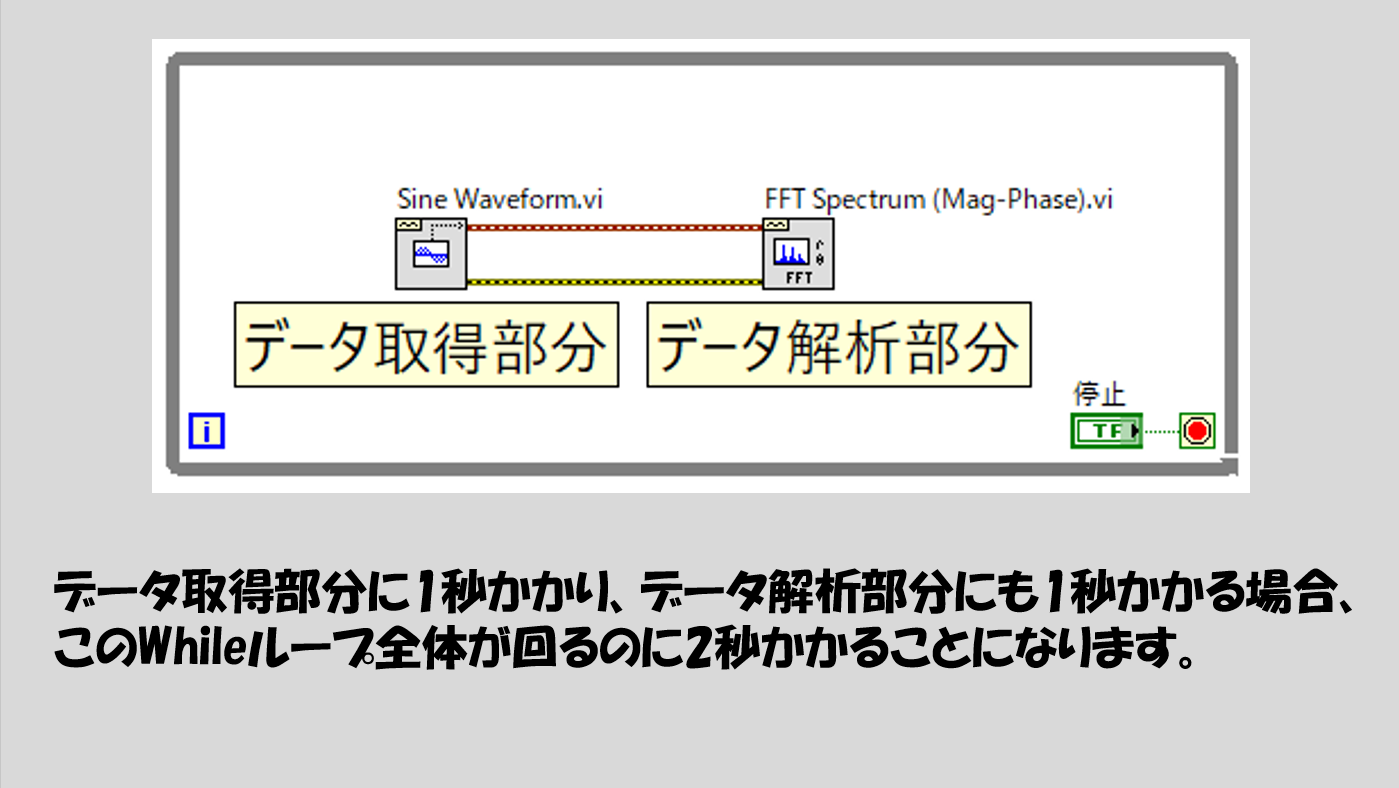
そのため、この繰り返し処理の中のプログラムの構造は
- データを取得する→データを解析する
を繰り返していることになります。
で、この処理に時間がかかる場合、実機としてハードウェアを使用しているとエラーの元になりえます。
ハードウェア側ではデータをひっきりなしにとっているのにソフト側でそれの処理が追い付かず「ハードウェア側でデータをとっているのと比べてソフトウェア側が遅すぎますよ」というエラーが出る、そんな状況に遭遇することがありえます。
実際のDAQのプログラムでもう少し具体的にシナリオを考えると以下のような状態です。
例えばハードウェアは1秒に1000データ集録していて、ソフトウェア側ではその1000このデータを読み取って解析するのに合計2秒かかるとすると、その間にハードウェアは2000個のデータを新たに取得していることになります。
次のループでソフトウェアはそのうちの1000このデータを読み取るので、余りの1000データは次の(3回目の)ループで読まれますが、そうこうしているうちにハードウェア側ではまた新たなデータを集録している・・・これが繰り返されていくと、どんどんハードウェア側のバッファにデータがたまっていずれパンクします。
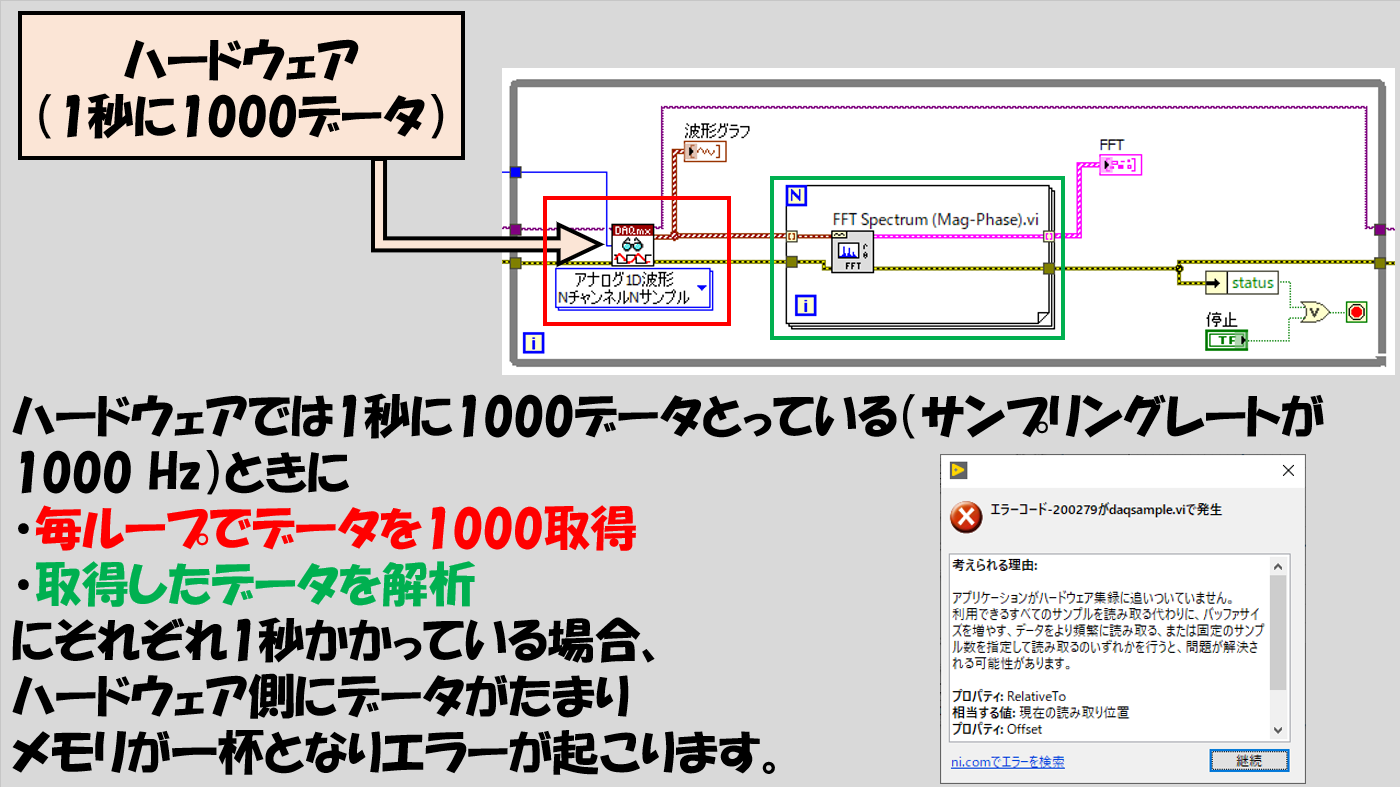
こんな場合にどのように対処すればいいか、パフォーマンス的に効率のいいプログラムを書くための方法が、これからご紹介する「キュー」を使ったプログラムの方法です。
処理を分けるとは
LabVIEWではこの問題を回避するための方法として、「それぞれの処理はそれぞれ別の繰り返し処理で対応する」という組み方を用意しています。
その組み方に使用するのがキューという関数です。キューはQueue、並ぶ、という意味です。
イメージとしてはこんな感じです。キューという入れ物があって、これを二つのループで共有する、という状態にします。
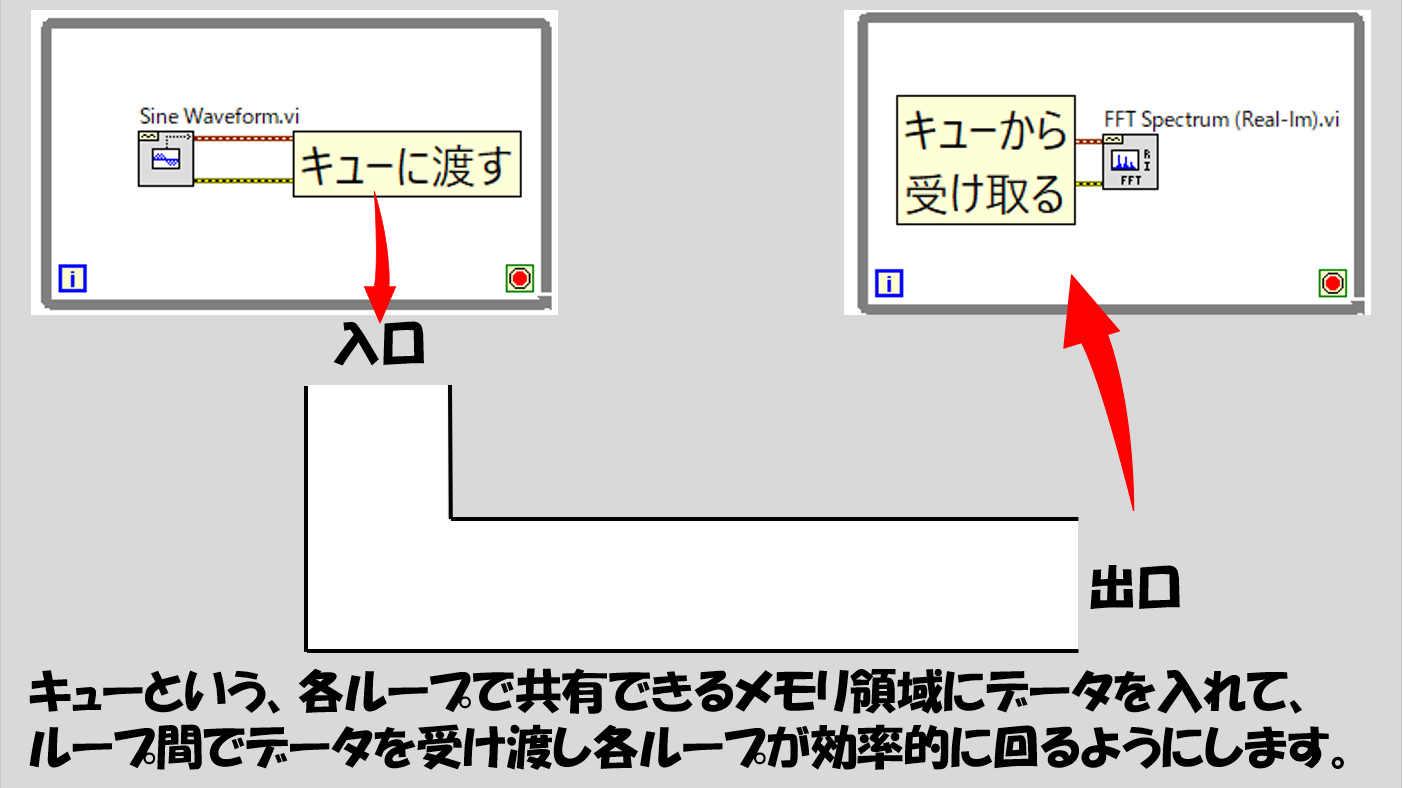
データを取得する処理と、データを解析する処理がそれぞれ別のWhileループに入っています。この二つは、お互いでデータを共有しながらプログラム全体が進んでいきます。
またキューは「データを入れた順番」が決まっており、「最初にキューに入れたデータは最初に出る」「2番目にキューに入れたデータは2番目に出る」という性質があります。(First In First Out =FIFO)
この点も、測定したデータを正しく取り扱うのに都合がいいポイントになります。
結局ループを分けることで、片方のループは
- データを取得する→もう片方のループにデータを渡す
のみで終わり、もう片方は
- データを受け取る→データを解析する
のみでループが終わります。
実際データの受け渡しは一瞬なので、データを取得するループはデータの解析に時間を取られることなく、データの取得という作業のみに専念できます。
一方のデータを解析するループはデータを受け取り次第すぐに解析、終了したらまた受け取って解析、を繰り返します。
LabVIEWの実行順番やループのルールを考えると、二つの処理を入れた場合にはそれらの処理にかかる時間の合計がループ一回あたりにかかる時間ですが、これを分けることでかかる時間も減ります。
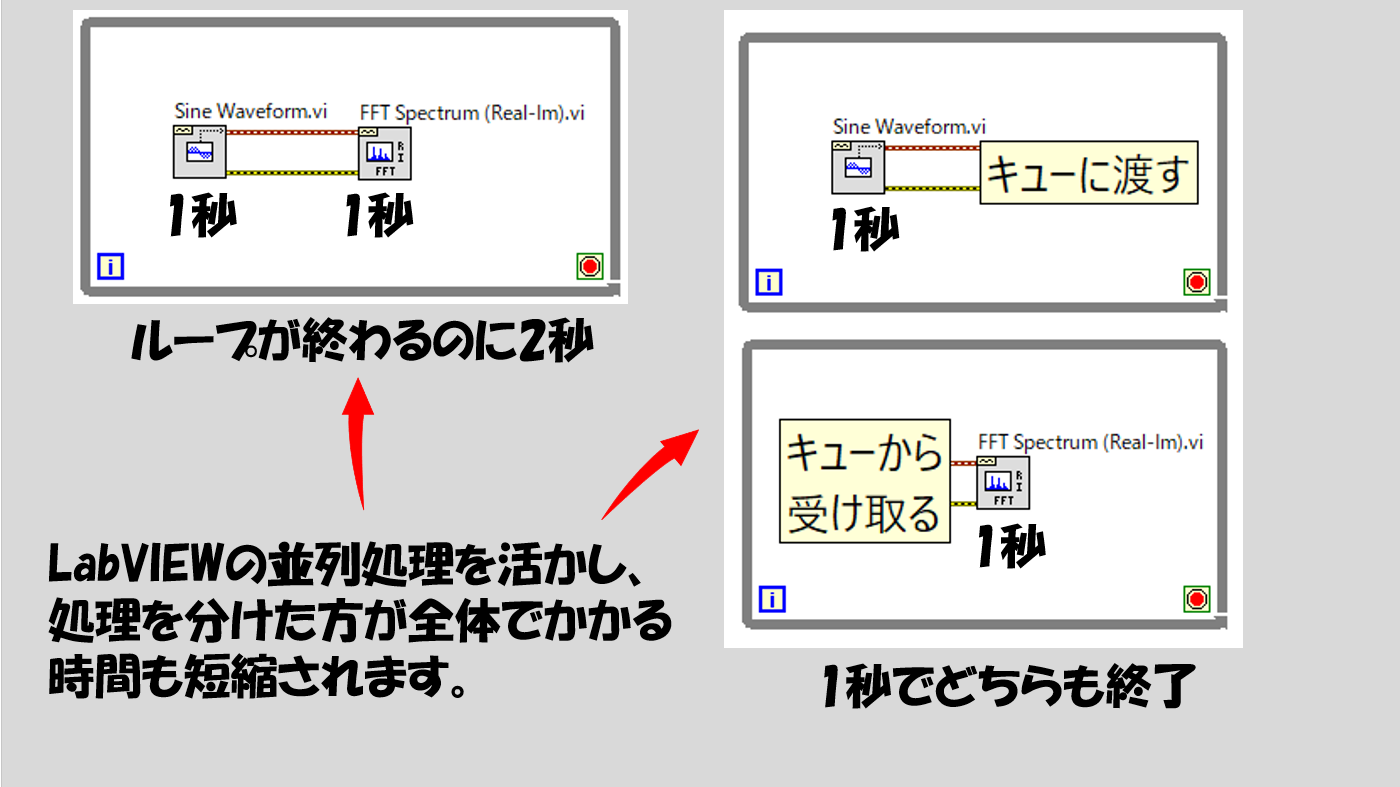
(実際に上の図の関数それぞれは1秒もかかりません、あくまでイメージです)
最終的に得られる結果はキューを使用しない場合と同じなのですが、それぞれのループがそれぞれの役割を分担して並行してループが実行されることによって全体の処理が早くなります。
キューを使った典型的なプログラム
では実際にキューを使用して二つのWhileループを使用し並列処理できるプログラムを書いていきます。
キューの考え方は
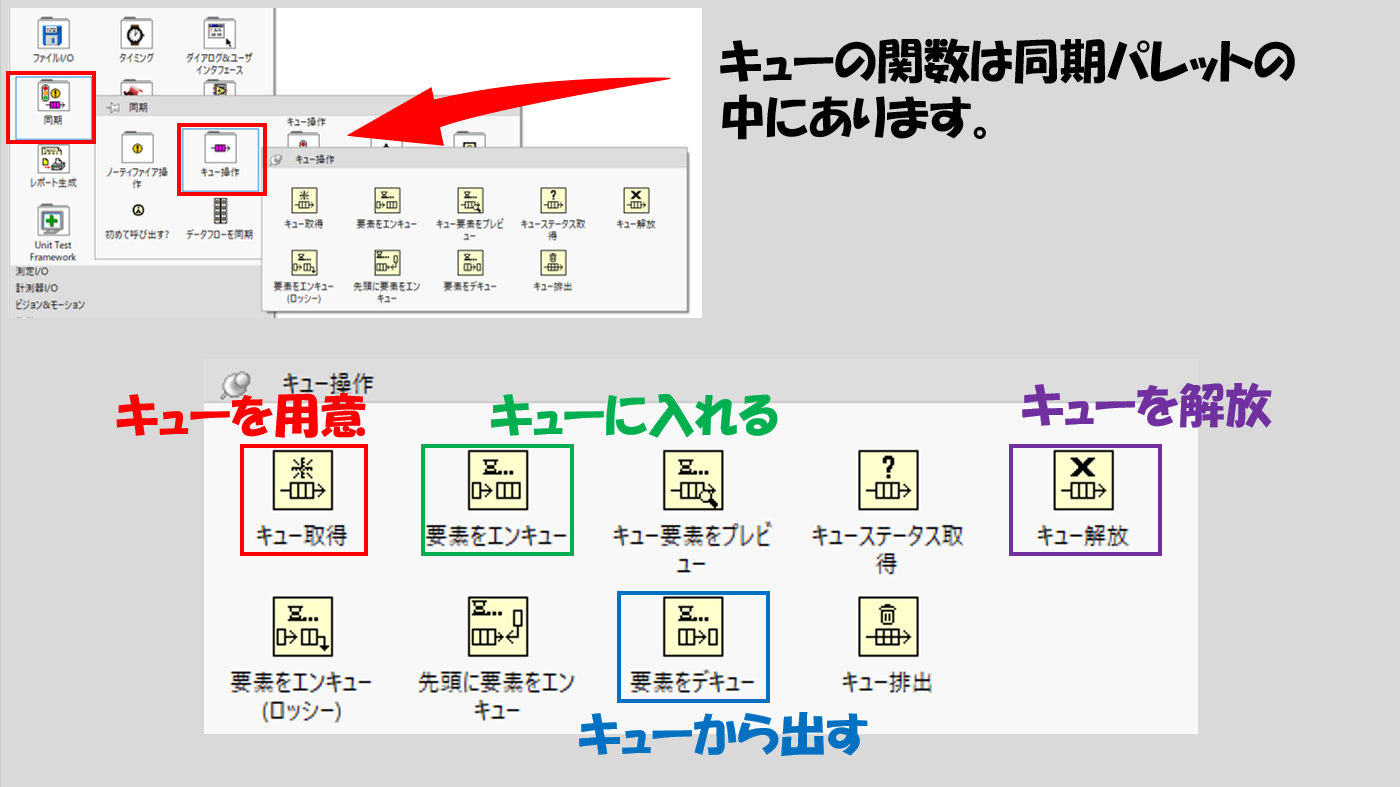
- キューを用意(受け渡すデータタイプを指定)
- エンキューでキューにデータを入れて、デキューでキューからデータを取り出す
- 使い終わったらキューを解放
という3ステップを覚えておけばとりあえずOKです。
これらはそれぞれに関数が用意されており、以下のように同期というパレットにあります。
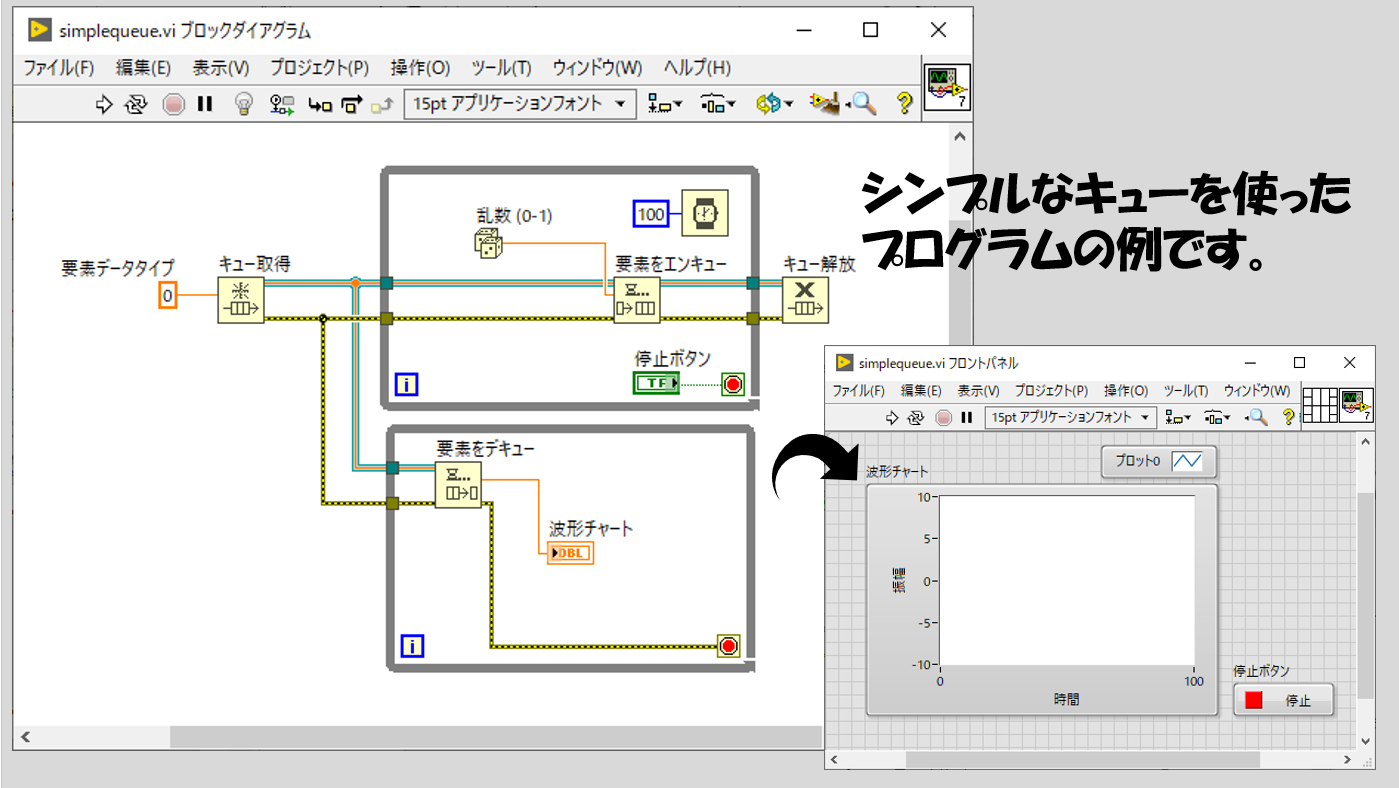
一番シンプルなキューの使用法は以下のようです。キューによって数値一つ(乱数の値)を上のループから下のループに渡す場合を想定しています。
より細かいポイントとしては
- Whileループに入る前にキュー取得関数を使用し、要素データタイプとして「キューでどのようなデータを受け渡しするか」を定義する(数値単体や数値の配列、など)
- 要素をエンキューが入ったWhileループが終わった後にキュー解放の関数をおいて要素をデキューのエラーワイヤをWhileループの条件端子に配線する
といったことが挙げられます。
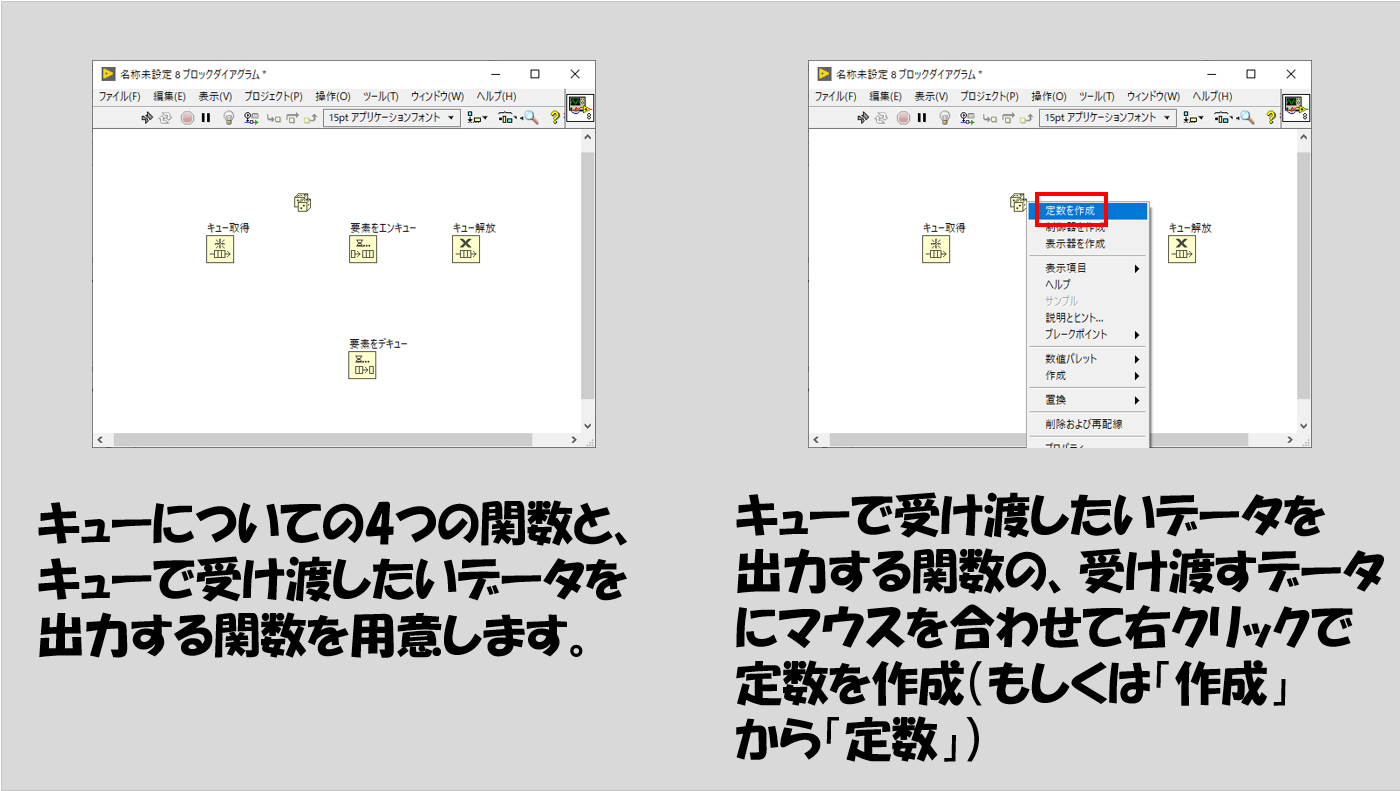
要素データタイプの定義の仕方については、以下の手順のようにやるとスムーズにプログラムを作れます。
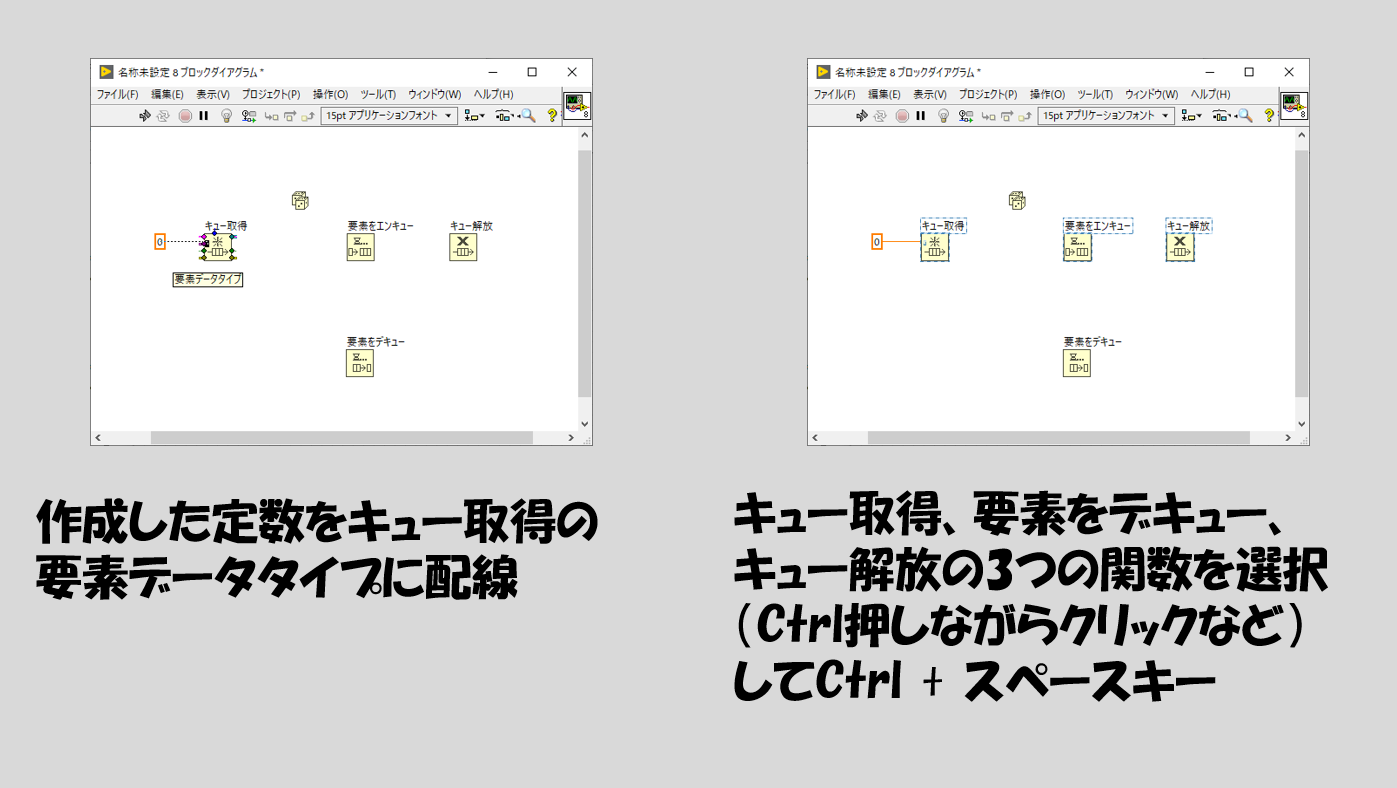
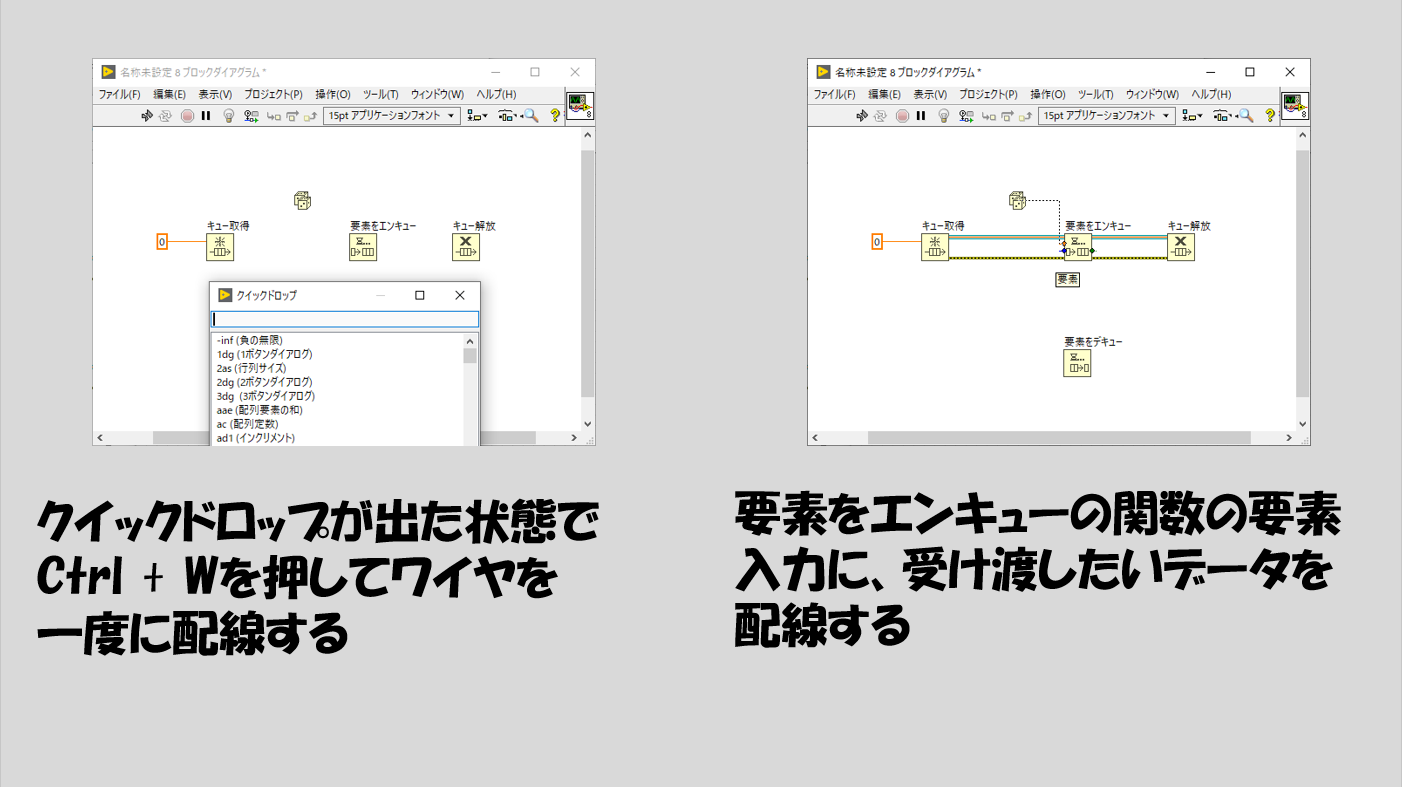
要素をデキューの関数がはいったWhileループが止まる条件は、エラーワイヤからエラーが出たときとしています。実際この部分のエラーは、キュー解放の関数が実行されたときに出ます。キューが解放(なくなった)という状態でデキュー(キューから要素を取り出す)ことができなくなるためですね。
ただ、この組み方の場合には一つ困ったことが起こります。例えば、上記のプログラムを実行し、適当なタイミングで停止ボタンを押します。すると、毎回チャートの表示は0で終わると思います。
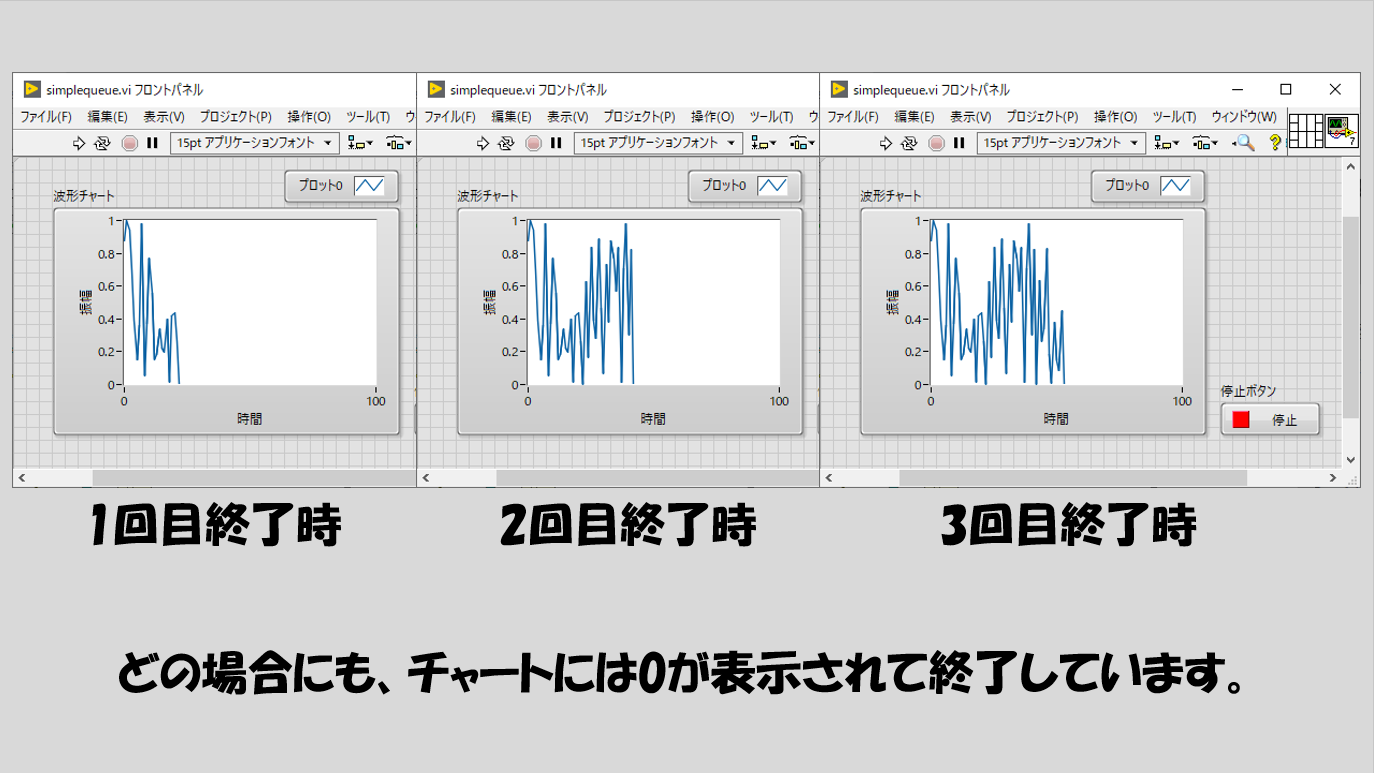
もちろん、乱数の値が最後にたまたま0が出力されて終わることもあり得ると思いますが、3回(実際は何度やっても)0で終わるのはさすがに偶然とはいいがたいということに気づくと思います。
これは、デキューの関数の仕組みで説明することができます。簡単に言えば、デキューの関数がエラーを出す際に「要素」も何かしら出さないといけず、エンキューが終わっている以上デフォルトの値を出すしかなくなっている状態となります。

もし上記の仕様の意味が分からなければ、とりあえず「上の組み方をすると一番最後は意味のないデフォルトの値がデキューの関数から取り出される」と思ってください。
これを防ぐには、以下のようにケースストラクチャというものを使用して、エラーが起きていない場合にのみ処理を行うようにし、エラーが起きた場合には何もしない、という組み方をします。
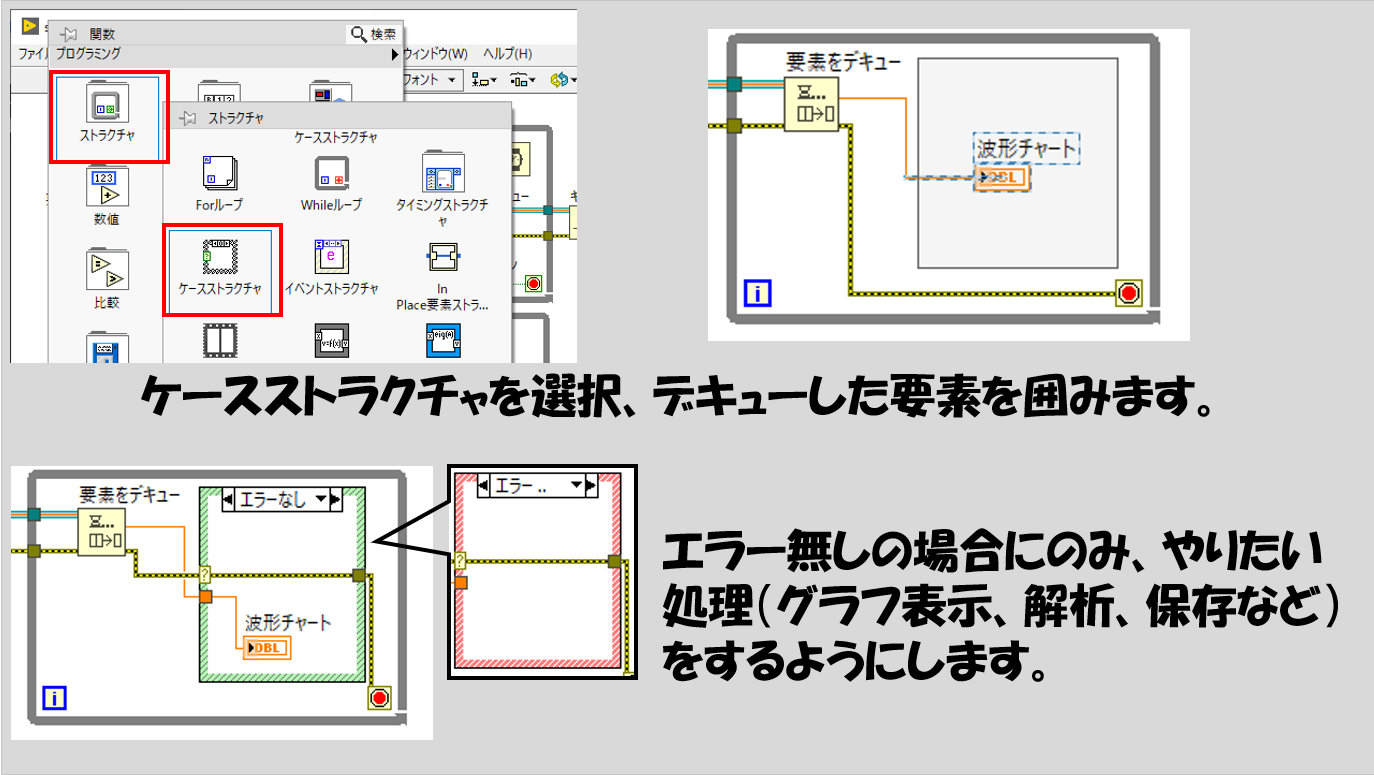
この組み方はハードウェア操作を行うプログラムに限らず、キューを使用するのであればどんな場合でも使用できます。
キューについてはもう一つ、気を付けるべき点があるのですが、それは本記事後半に改めて紹介します。
キューを使用したハードウェア操作プログラムの実例
キューの典型的なプログラムの作り方は何となくわかったでしょうか?理屈としてはわかってもなかなか自分で組むとなると難しい場合もあると思うので、実例をいくつか紹介していきます。
DAQmx APIを使用した場合
最も簡単なキューを使用したプログラムの例を紹介します。

組むときの考え方はいたってシンプルです。一つのWhileループに丸々入れていた処理を、他のループに分けて書くだけです。
データを保存するような場合ももちろん同じ考え方で組めます。
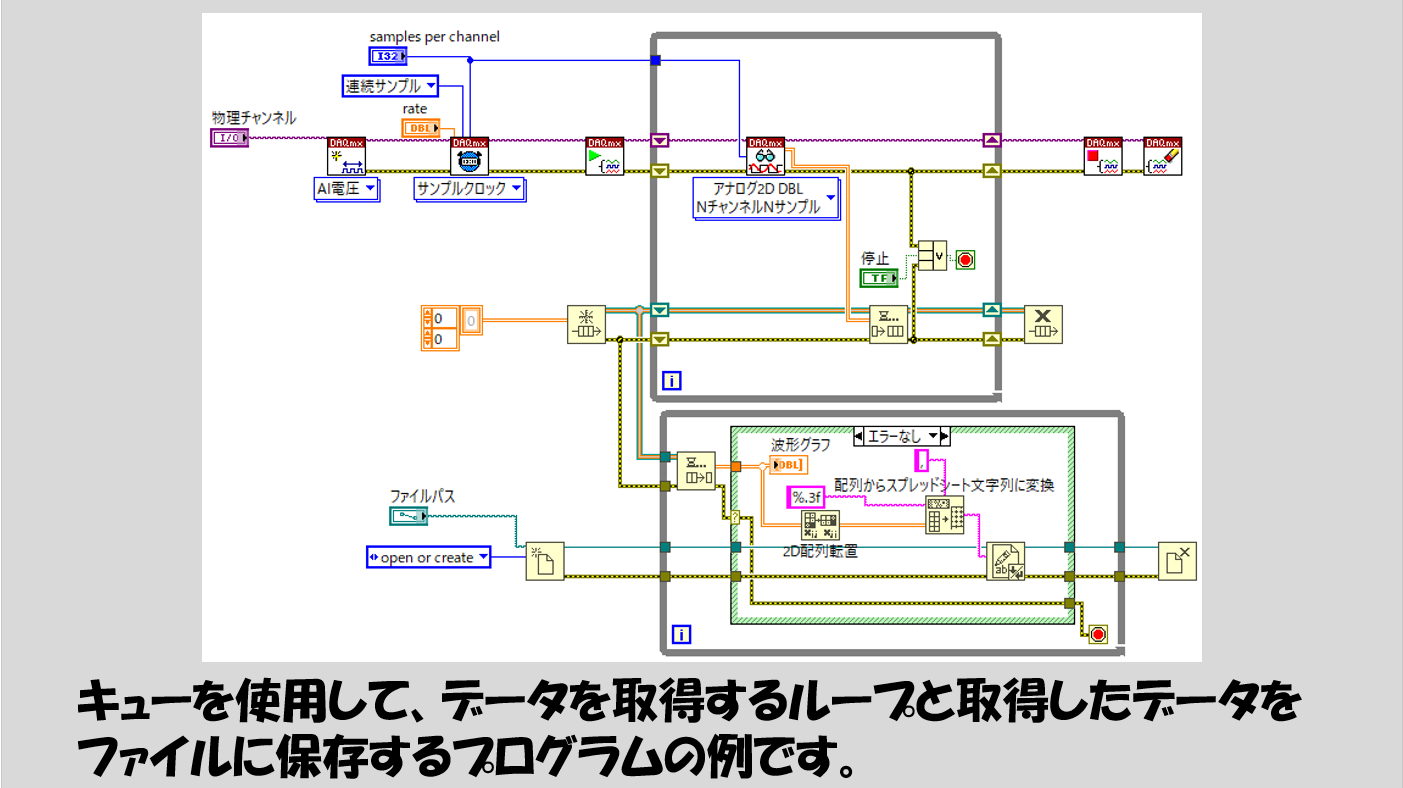
気を付けるところがあるとすれば、キューで受け渡しを行うデータタイプの設定くらいです。
上記はかなりシンプルに、トリガなどの構成もしていませんが、LabVIEWのヘルプメニューにあるサンプルを検索から開けるNIサンプルファインダの中のサンプルにももちろん応用できます。(サンプルを編集する際には別名保存しないとサンプルプログラムそのものを改変してしまうので注意します)
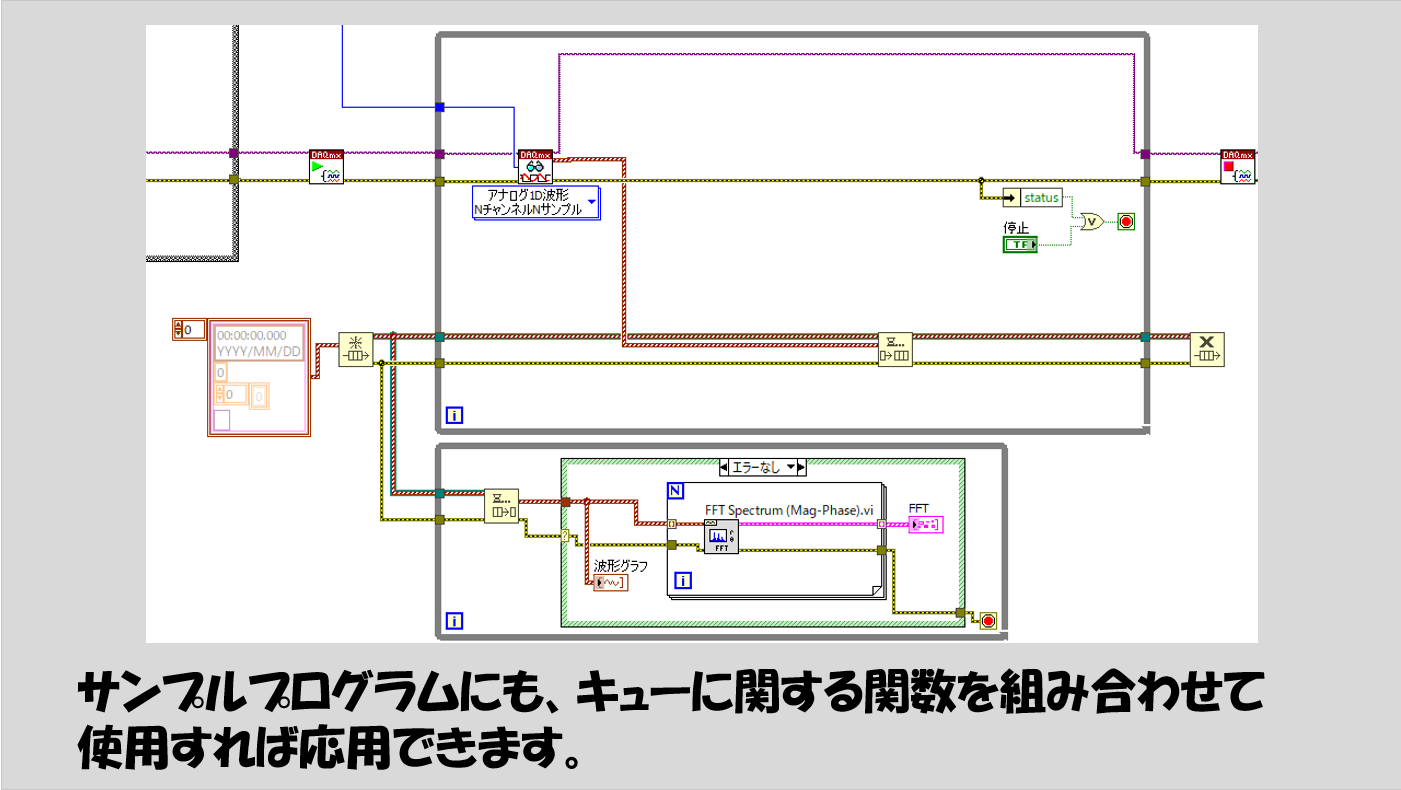
アナログ信号を扱うばかりではなく、デジタル信号を扱う場合も事情は変わりません。
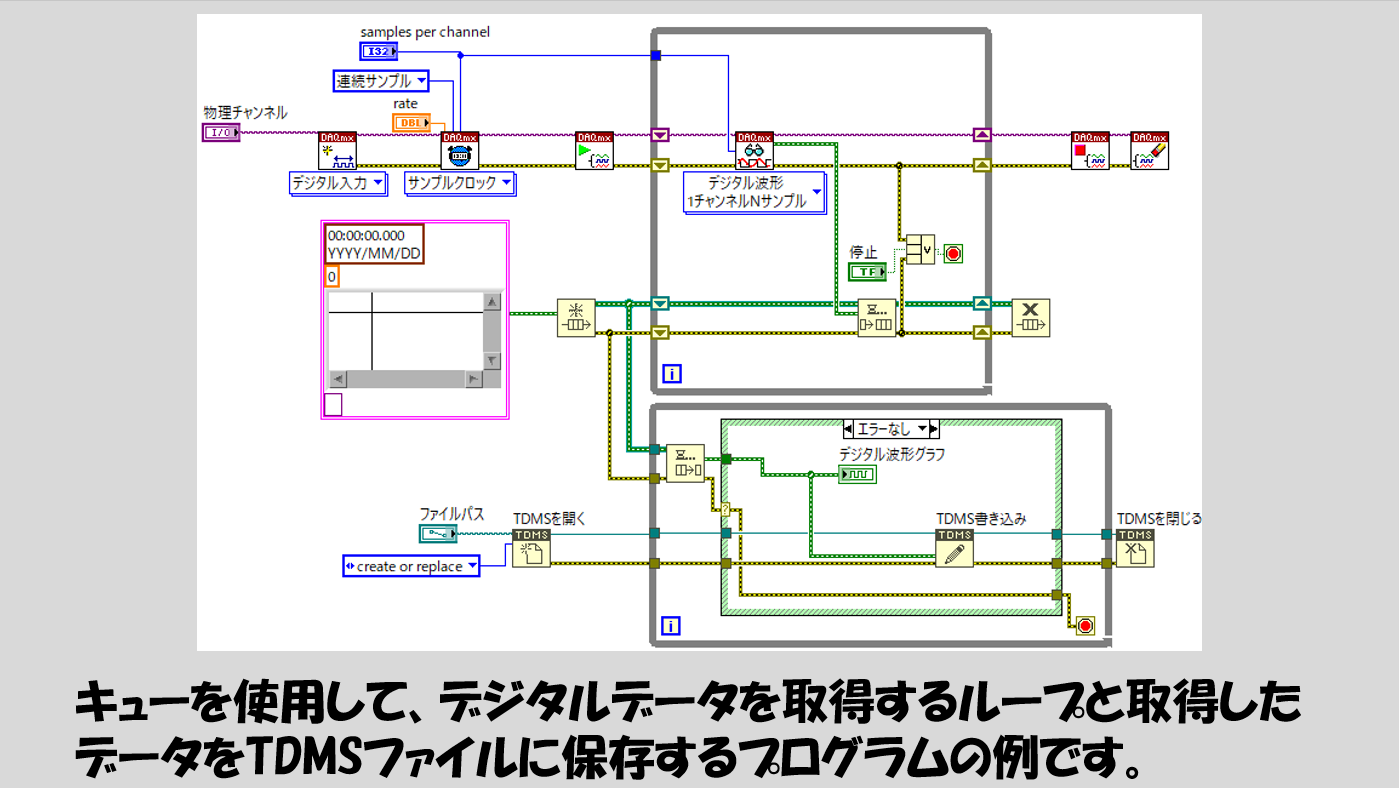
そしてもちろん、データを解析して保存もする、みたいな書き方もできます。

Express VIを使用した場合
キューを使用したプログラムはExpress VIを使用していても書くことはできます。が、ここで注意する必要があるのは、Express VIを使用した場合のデータタイプです。
DAQデバイスを使用する場合に使えるDAQアシスタントというExpress VIはダイナミックデータタイプという特殊なデータタイプ(Express VIでしかお目にかからない)もので、これをキューでそのまま扱うのではなく、いったんダイナミックデータタイプを別の「適した」データタイプに変換する必要があります。
そこで、ダイナミックデータから変換というExpress VIを使用します。このExpress VIはダイナミックデータを様々なデータタイプに変換できます。

変換する際にどれを選択するか迷う場合には、「時間の情報が必要なら波形データ、必要ないなら配列データ」と考えれば不自由はしないと思います。
波形配列はチャンネルが複数ある場合にそれぞれのチャンネルの波形データを扱う際に使用、1Dか2Dかは単一のチャンネル(1D)か複数のチャンネル(2D)かで区別します。
じゃあ時間の情報が必要ってどんな場合か、というと、基本的には解析処理の関数には必要と思ってください。FFTなどその代表ですが、これらは時間情報を持った波形データでないと正しい結果となりません。
もし解析の関数もExpress VIを使用している、ということであれば、ダイナミックデータへ変換というExpress VIも使用してダイナミックデータに戻してやることをオススメします。
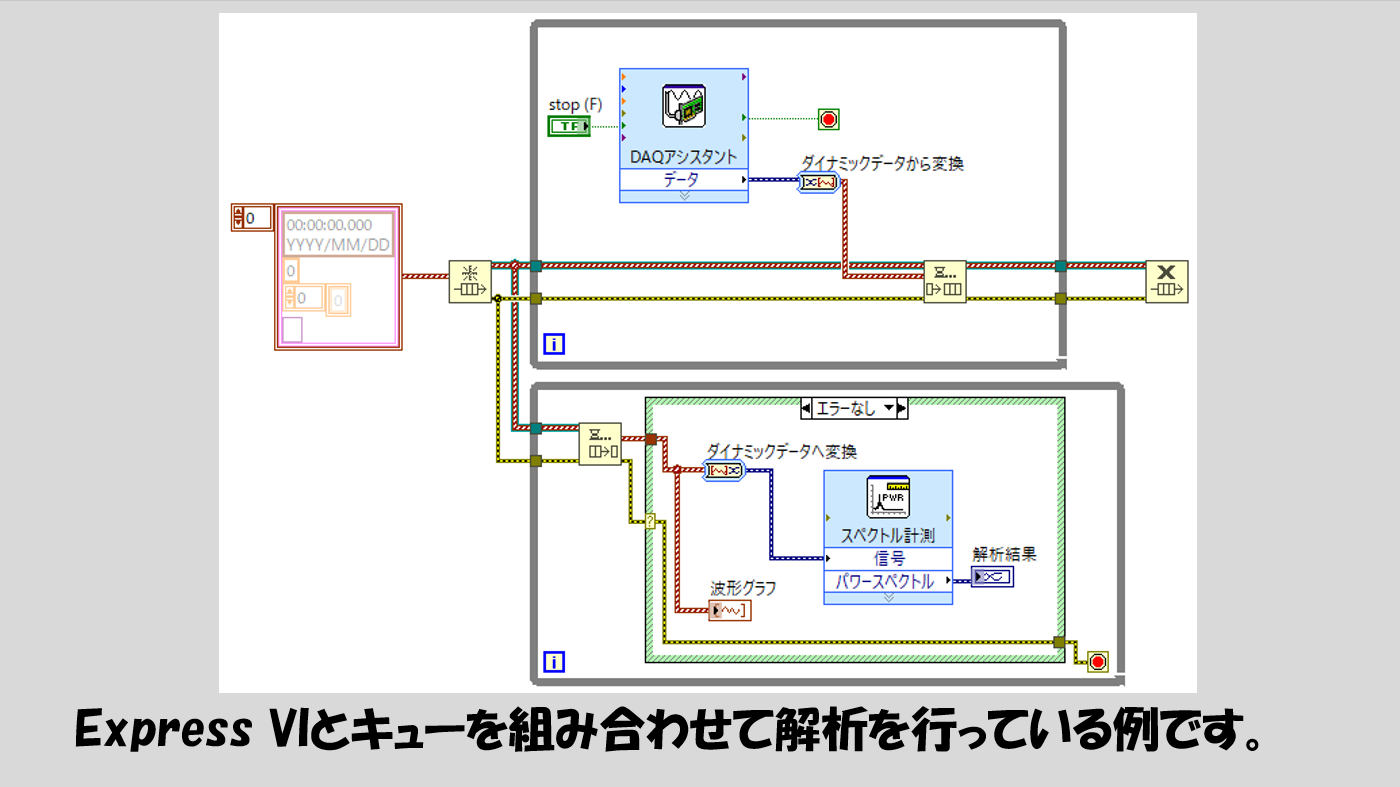
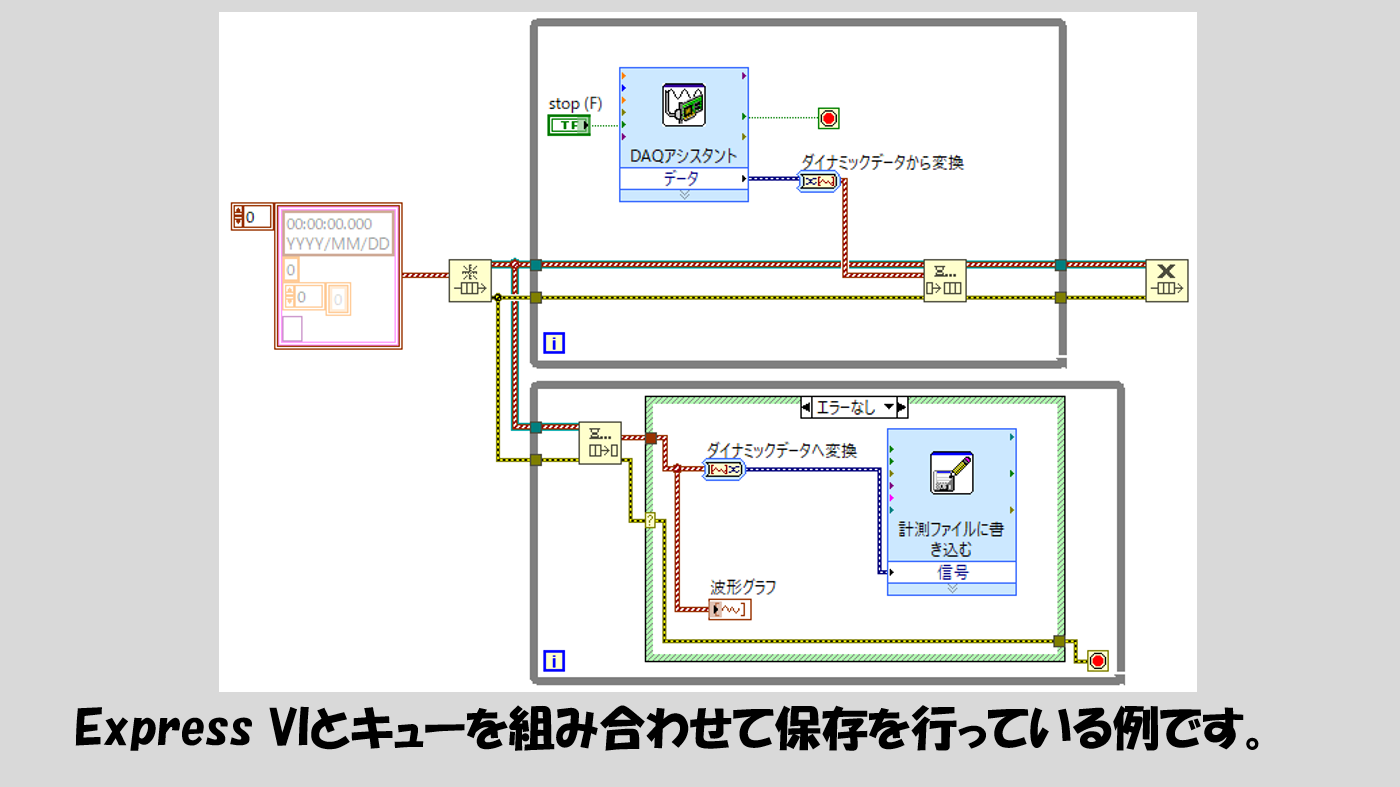
解析やデータ保存の部分はExpress VIを使用しない、という場合には、別にダイナミックデータへ変換せず、そのまま波形データや配列データを使用することもできます。
キューを使用した場合の注意点
ここまで処理を分けることで効率よくプログラムを書くことができることを紹介しましたが、使い方には注意点があります。
- 二つのループの速度があまりに違いすぎる場合
- キュー解放時のデータの損失
これらについて説明していきます。
二つのループの速度があまりに違いすぎる場合
例えばデータを取得するループが1回あたり100ミリ秒かかり、データを解析するループが1000ミリ秒かかるとします。
すると、データを解析するループが1回実行されている間にデータを取得するループは10回も実行されることになります。
このように、二つのループの速度があまりに違いすぎると、「周回遅れ」が発生することがあります。
これを確かめる楽な方法は、各ループの反復端子に表示器をつけて、その値の変化の速さを見比べることです。速さに違いがあると各反復端子の値に差が出ますが、違いがないと差はほとんど出ません。
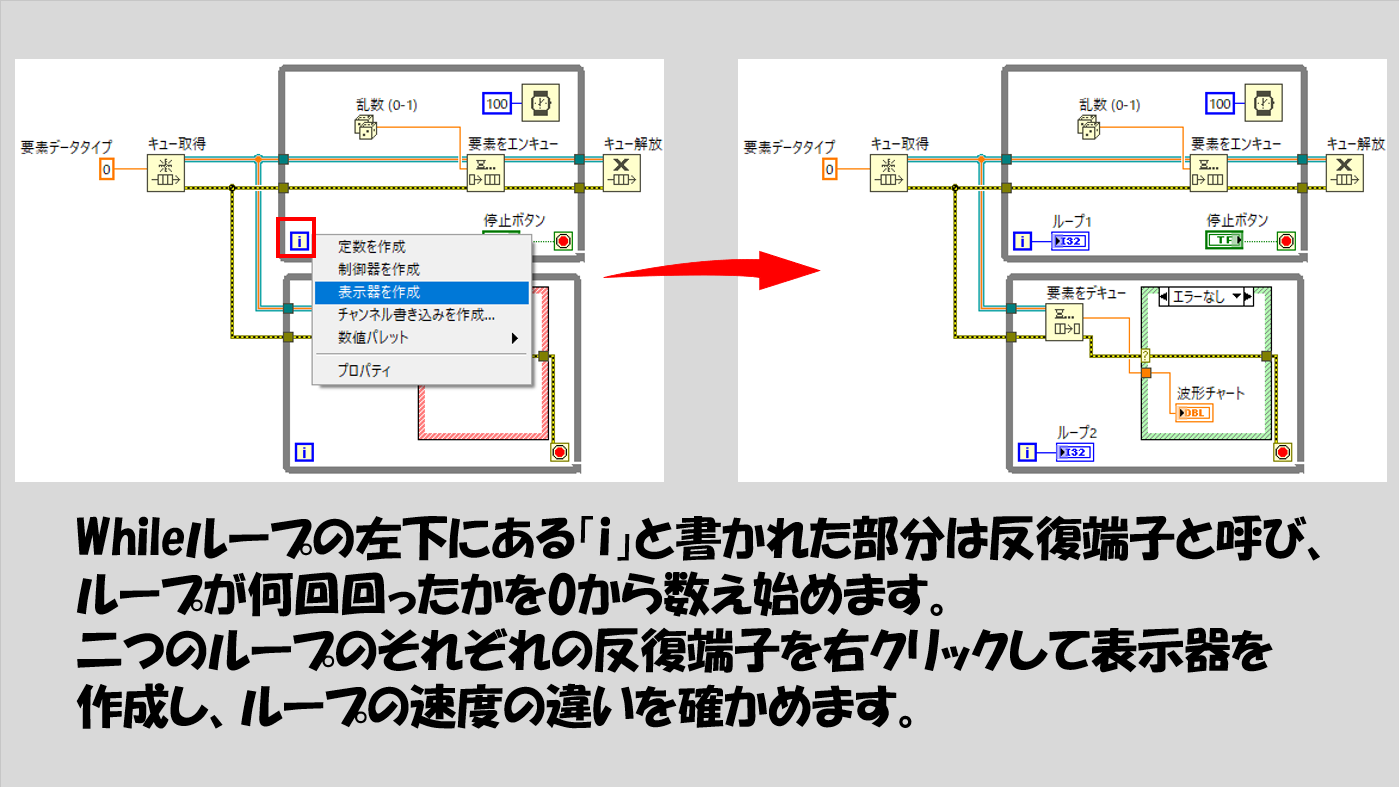
実際問題として、よほど大きなデータ(配列)を扱って解析して保存もして・・・なんてことをしない限り速度に大きな差が出ることは少ないのですが、キューを使用していてループ速度の差に問題が出たときには解消がなかなか難しいです。
手っ取り早く解消するためにはデータを取得するループをわざと遅くすることが考えられます。
せっかく効率のいいプログラムにしたいのにわざと遅くするなんて意味ないじゃん、と思うかもしれませんが、ことDAQを動かすプログラムに関しては、DAQmx読み取りの「サンプル数/チャンネル」の大きさを大きくすることでループ一回の時間が遅くなります。しかしデータとしてはちゃんとすべてのデータを得られているので、これでも効率のいいプログラムにすることはできます。
実際に以下のようにしてループの速度を測ってみると様子がつかめると思います。

もしシフトレジスタを知らない、使い方に慣れていないということでしたら、以下のような方法でもループにかかる時間を見積もれます。
以下の図で紹介しているフラットシーケンスストラクチャは、右クリックすればフレームをいくらでも増やせますが、フレームの中身が全て終わらないと次のフレームに進まないという性質があり厄介なので、本番のプログラムではなるべく使わないようにします。
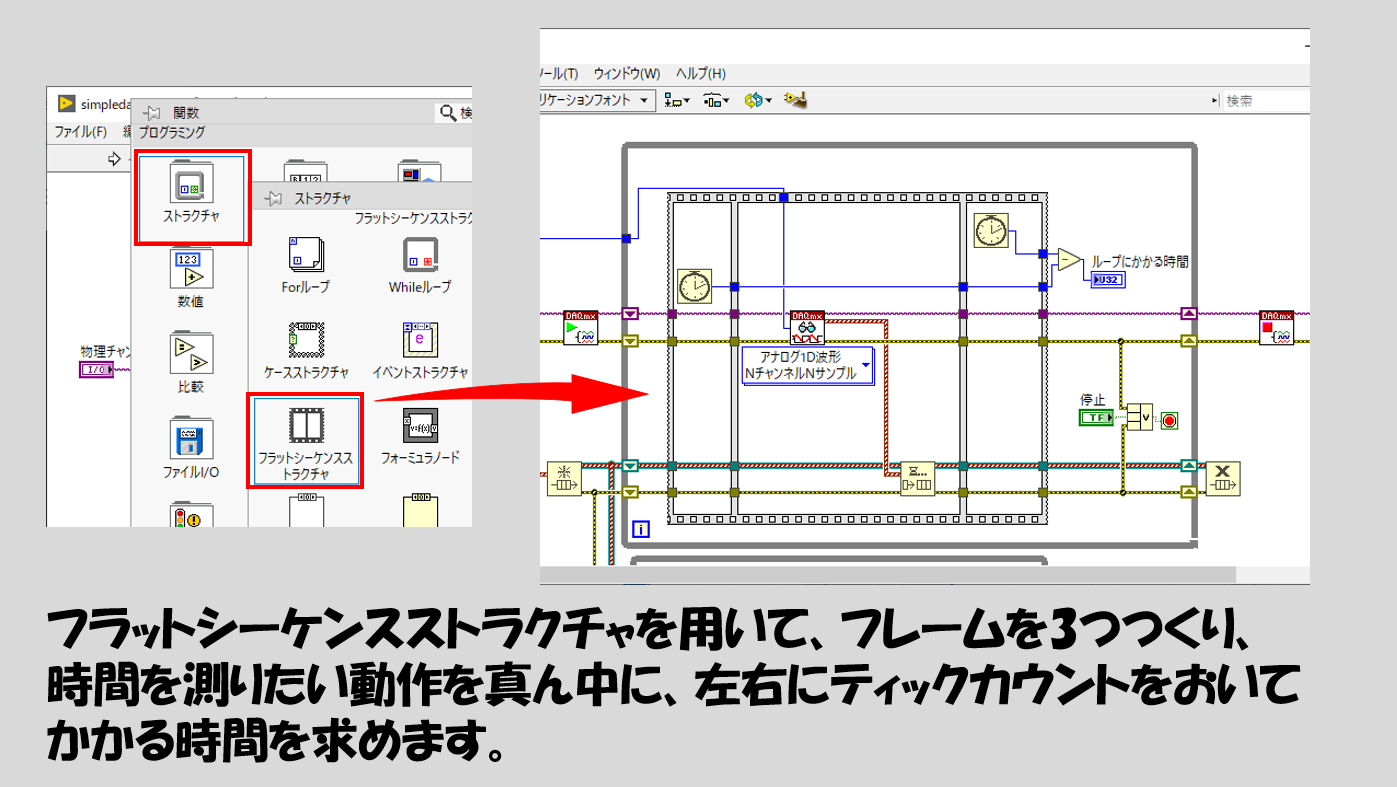
一度に読み取るサンプル数を多くすることでデータ取得のループが遅くなりますが、それだけ処理側でかかる時間も増えることになります。この辺りのバランスは、実際にプログラムを組んでみないと何とも言えません。
(サンプル数を大きくする代わりにサンプリングレートを小さくするという方法もありますが、たいていはサンプリングレートは要件として決まっているため変えられない場面が多いと思います)
あるいは、解析処理は後回しにして保存だけにする、といった工夫も考えられます。あれもこれもやる、となるとPCの性能が関係してくるので、できる範囲のことで無理のないプログラムにすることを考えます。
キュー解放時のデータの損失
プログラム終了時にはキュー解放の関数を使用することでキュー用のメモリを解放します。
このときに問題になるのが、まだ処理しきれていないデータがたまっている場合です。キューは入れ物であり、データを入れる操作(エンキュー)とデータを取り出す(デキュー)操作の二つがありますが、キューを解放することでこのキューの中のデータは消失します。
例えば、エンキューの操作が10回行われてデキューの操作が8回しか行われていない状態でキューを解放すると、まだ取り出されていない2回分のデータはそのまま取り出されずに消えてしまう、という感じです。
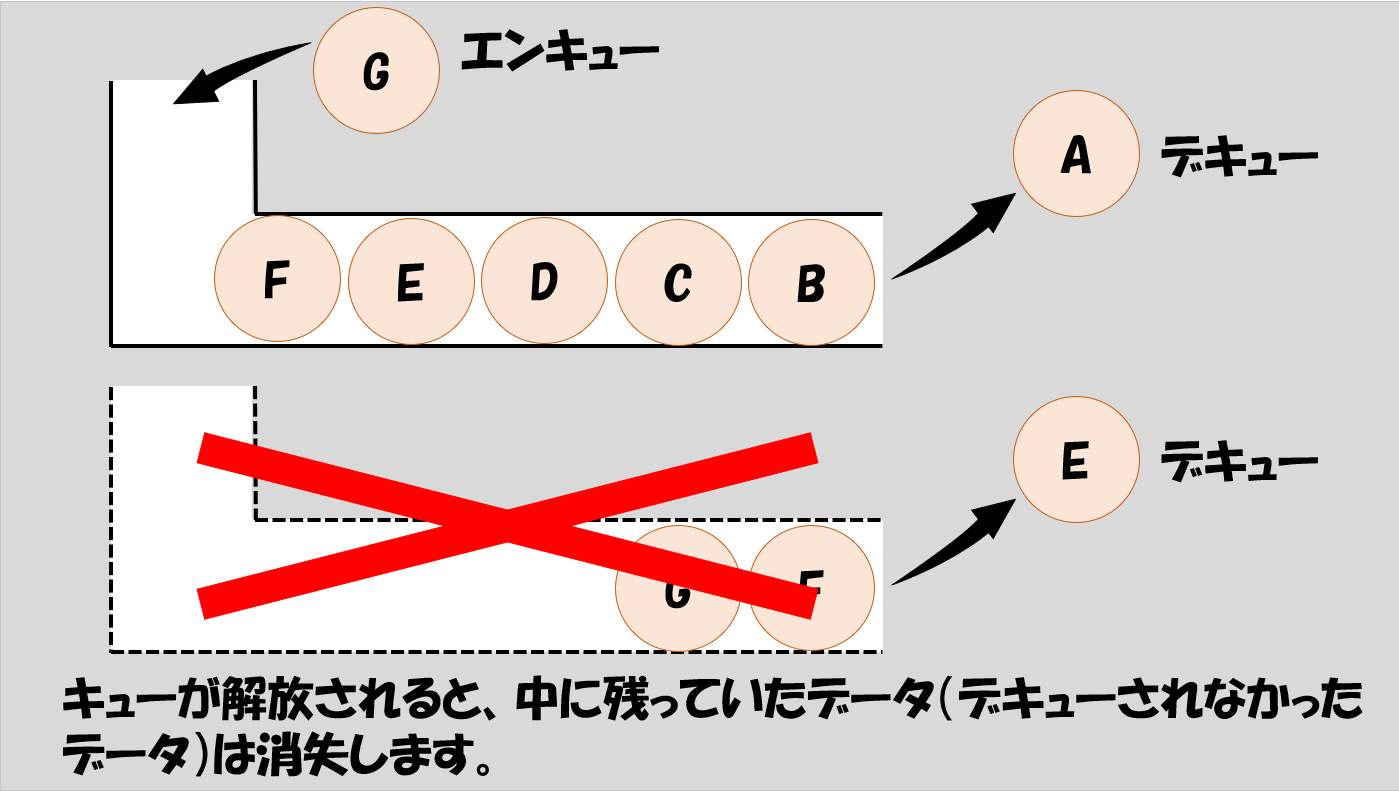
これだとせっかくデータを取ったのに最後の方のデータがうまく解析やら保存やらされない状態となってしまいます。
そんな状態を防ぐための工夫が、キューの中の要素(データ)が空になってからキューを解放するという組み方です。キューの中にあとどれくらいの要素が残っているかを調べる関数があるのでこれを使用し、要素が0になったらキューを解放するという組み方ができます。
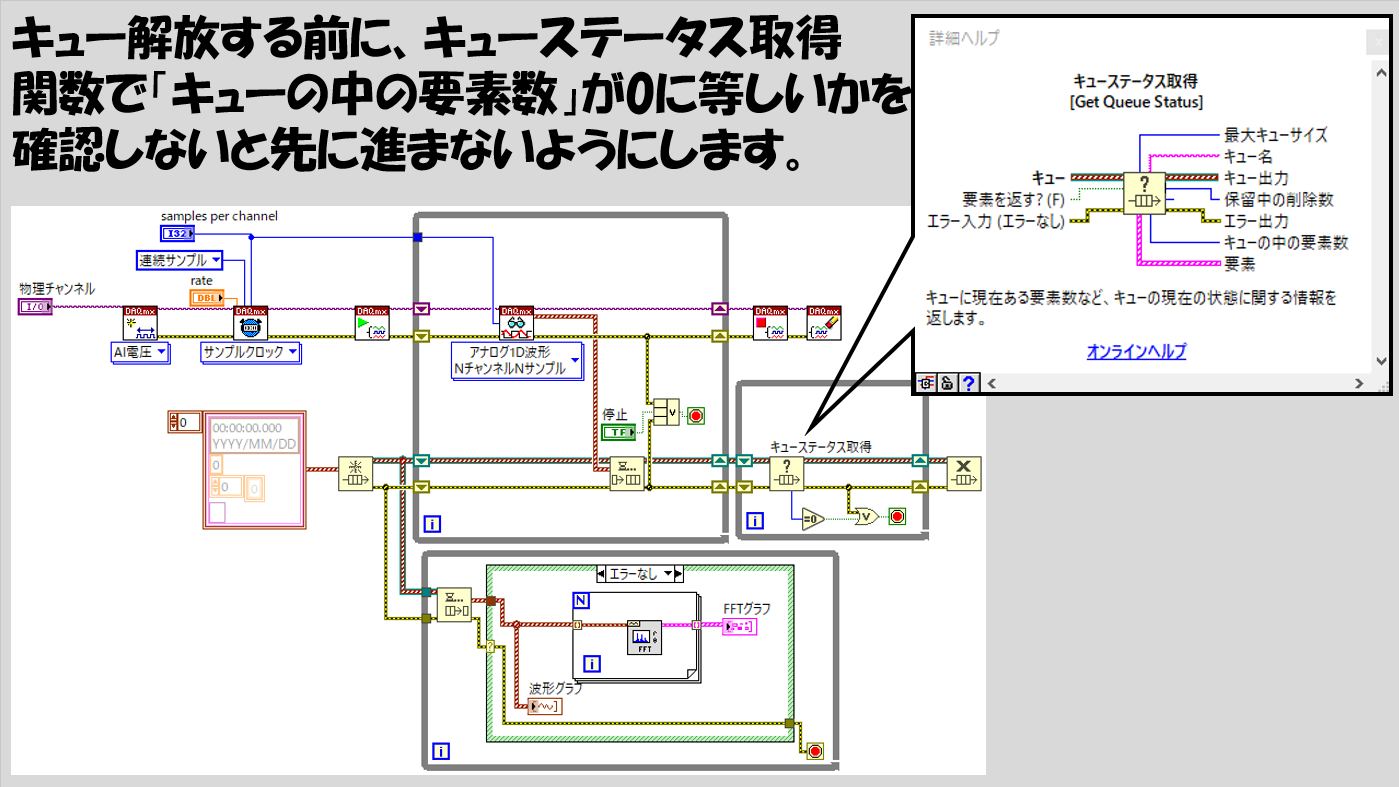
本記事で紹介したキューを使用したプログラムは、何もDAQを使用した場合に依りません。LabVIEWが得意とする並列処理の仕組みを活かせる場面であればどんな場合でも同じ形で使用することができます。
また、LabVIEWで複雑なプログラムを書く際にも十分使えるテクニックなので、覚えておいて損はないと思います。
DAQmxのAPIを使用する場合でもExpress VIを使用する場合でも、効率のよい書き方をして長く、安定して使えるプログラムを目指す際に参考にしてもらえるとうれしいです。
ここまで読んでいただきありがとうございました。
コメント