LabVIEWと同様なプログラミングによってWeb Applicationを作成することができるG Web Development Software (以下GWDS)を触ったことがない方に向けて、基本的な事柄を解説していこうという試みです。なお、大部分の事柄は、GWDSの前身であるLabVIEW NXG Web Moduleと共通します。
シリーズ7回目として条件分岐です。
この記事は、以下のような方に向けて書いています。
- 条件によって処理を分けるにはどうすればいいの?
- 条件の決め方がわからない
- デフォルト設定って何?
もし上記のことに興味があるよ、という方には参考にして頂けるかもしれません。
なお、前回の記事はこちらです。

条件分岐
前回の記事では、グラフやチャートの使い方について紹介しました。
数値データをわかりやすく表示させるための選択肢として重要なものの、混同しやすい機能になっています。そもそも使い方が異なるので意識して使い分けをする必要があります。
そして今回は打って変わって条件分岐の話です。
プログラムで毎回同じ処理を行うのではなく、何か特定の条件によって処理の内容を変えたいときに使用します。他のプログラミング言語でif文などと呼ばれているものですね。
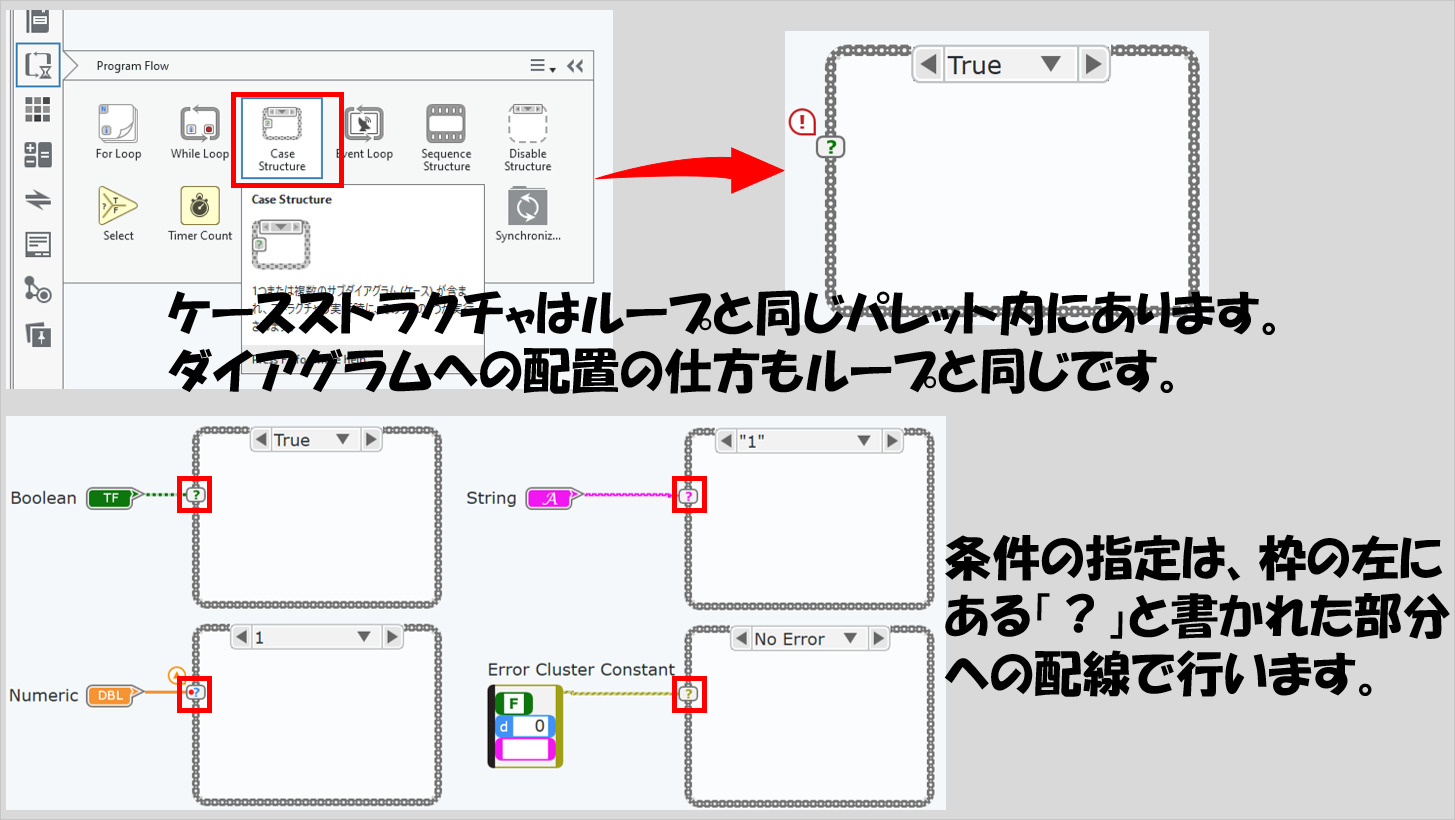
GWDSではケースストラクチャという枠組みでこれを表わします。
GWDSでは、条件と、その条件に対する値とで分岐をしていきます。例えば、下の図には他言語のプログラムで「condition」という値がどのような文字かによってoutputとしての文字列が変わるプログラムの形の例を示していますが、GWDSのケースストラクチャでは、ケースセレクタに「condition」の文字列制御器(定数)を入力し、セレクタラベルで「Morning」や「Afternoon」などと指定するようにします。

「条件」とは「Yes」か「No」かの二択とは限りません。もちろん、「Yes」か「No」の二択で条件を変えるということもありますが(そういう場合にはブールが便利です)、「○○が××なら△△する、□□なら☆☆する」といった分岐を好きなだけ作れます。
ケースストラクチャの枠左側にある「?」と書かれたケースセレクタが条件の内容を配線する端子となっており、二択の結果を示すブールデータタイプだけでなく、数値や文字列、あるいはエラークラスタなども配線できます。
例えば、乱数を使用して、その値が0.5よりも大きければ文字列表示器に「成功」、0.5未満であれば「失敗」と表示させるプログラムを作るのであれば、以下のような手順でプログラムを用意します。
まずは、条件の設定です。ここは今までにも乱数発生の関数を使用してきたので、その値と0.5との大小関係を不等号の関数(ノード)で表現します。
そして、乱数が0.5以上の場合、つまり、不等号の結果がTRUEの場合の処理を書きます。
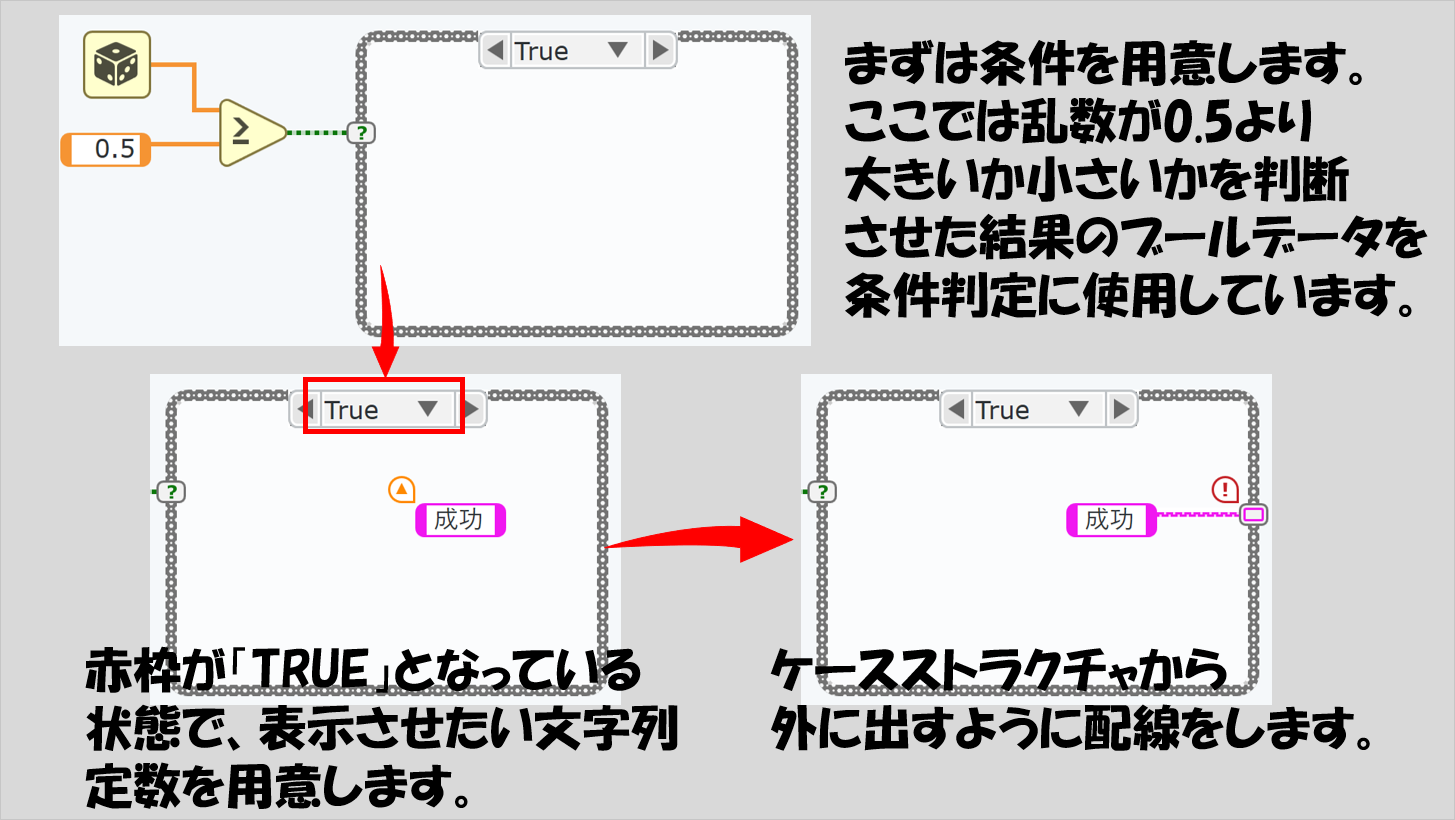
今回は、判定がTRUEでもFALSEでも文字を表したい、という意味で「どの条件(ケース)でも共通の動作(文字を表示)がある」状態なので、共通して使うもの(文字を表わすための文字列表示器)をケースストラクチャの外に作ります。そのため、出力トンネルから表示器を用意します。
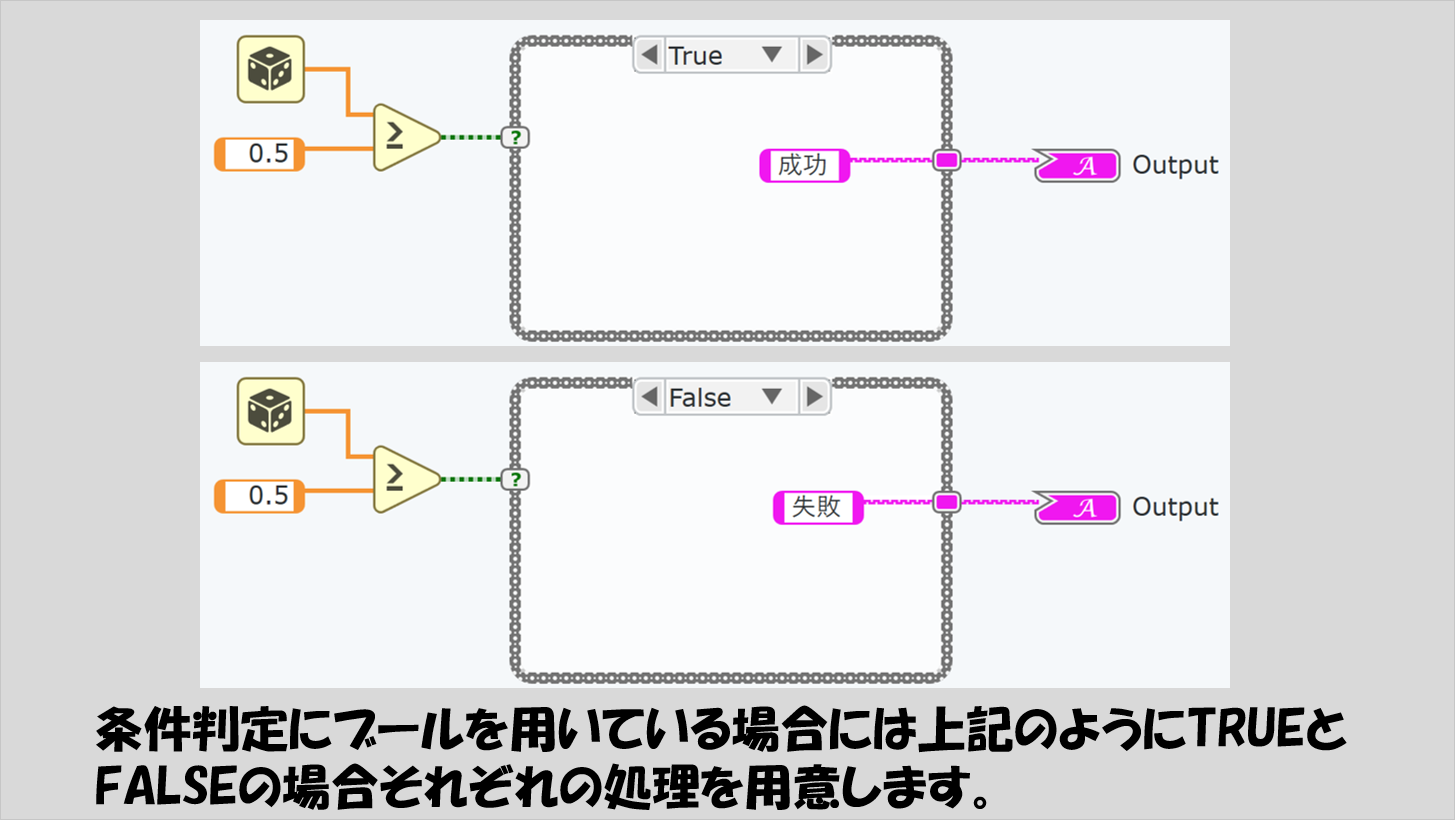
その後、ケースを変えて、FALSE(乱数が0.5より小さい)場合の処理を書きます。

これで、TRUE、FALSEどちらになってもそれぞれ異なる表示を行うことができるプログラムになりました。
この例は条件判定として一番わかりやすいブールデータタイプを使用していますが、他のデータタイプで条件判定をさせる場合にもやることは同じです。少し後で他のデータタイプを使用した例を紹介します。
なお、WhileループやForループ同様、ケースストラクチャを用意した場合、このケースの中にある処理しか、その条件下では実行されません。また、ストラクチャの中にある処理すべてが終わらないとケースストラクチャから抜け出せません。
例えば下のプログラムになると、ケースストラクチャに入っていない「判定中という文字列定数がOutput_2の表示器に渡される」という処理は、ケースストラクチャのTRUE、FALSEに関係なく実行されます。
また、ケースストラクチャの中身が全て実行されないとケースストラクチャから抜け出せないので、文字列が外のOutputに渡される前には必ず足し算(FALSEなら引き算)が実行されることになります。
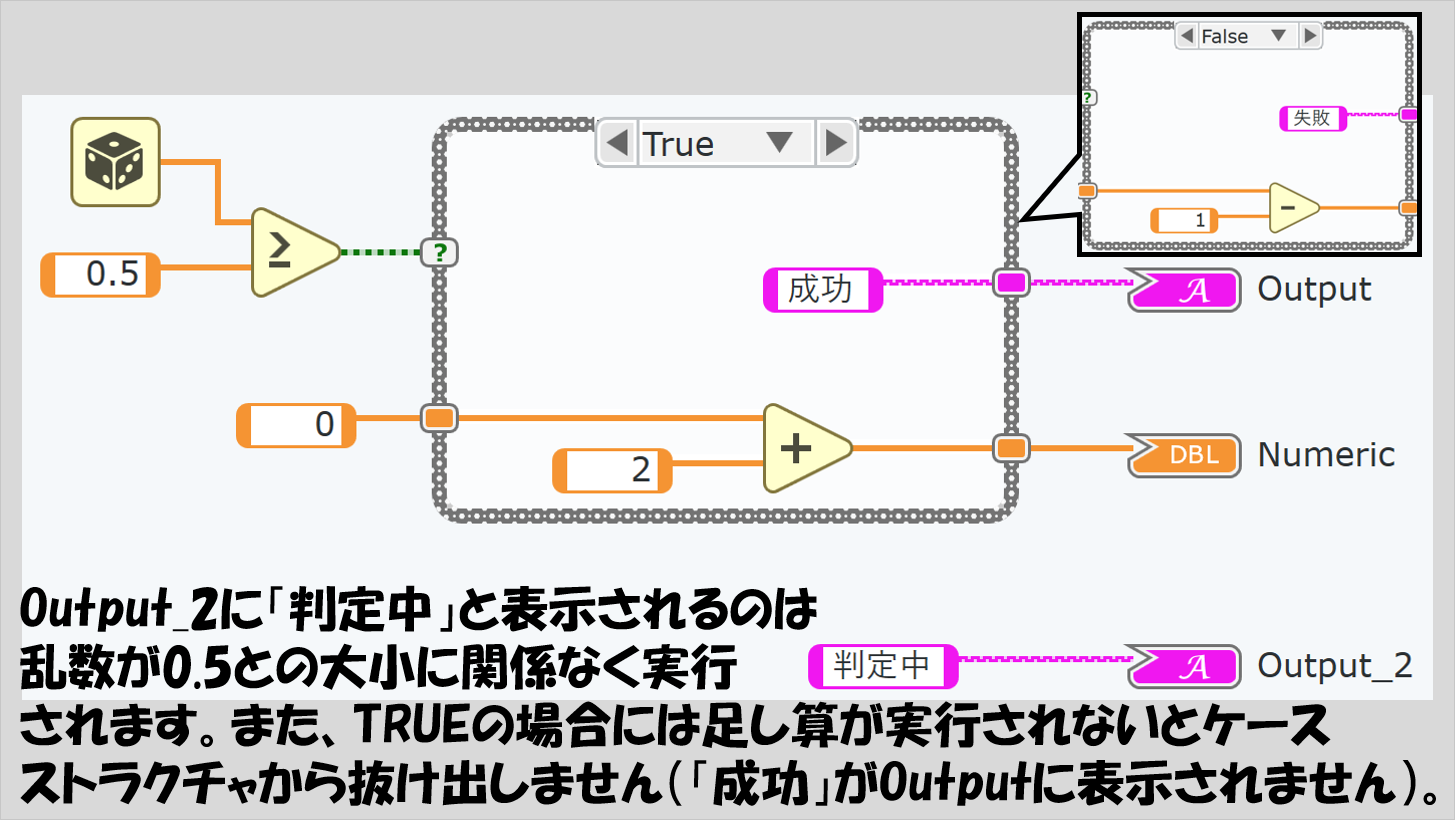
あくまで条件によって結果を分けたい処理だけケースストラクチャに入れてください。
ケースストラクチャの注意点
ケースストラクチャの使用にはいくつか注意点があります。
- デフォルトケースを用意する
- 出力トンネルはすべてのケースで定義する
これらを守らないとそもそもプログラムを動かすことができないので、しっかり覚える必要があります。
デフォルトケースを用意する
まず、デフォルトを用意する必要がある点について。
これは「条件」に対するデフォルト値のことで「定義されていない値が条件に来た場合に行う処理」を示します。具体例で示した方が分かりやすいと思うので、以下の例を考えます。
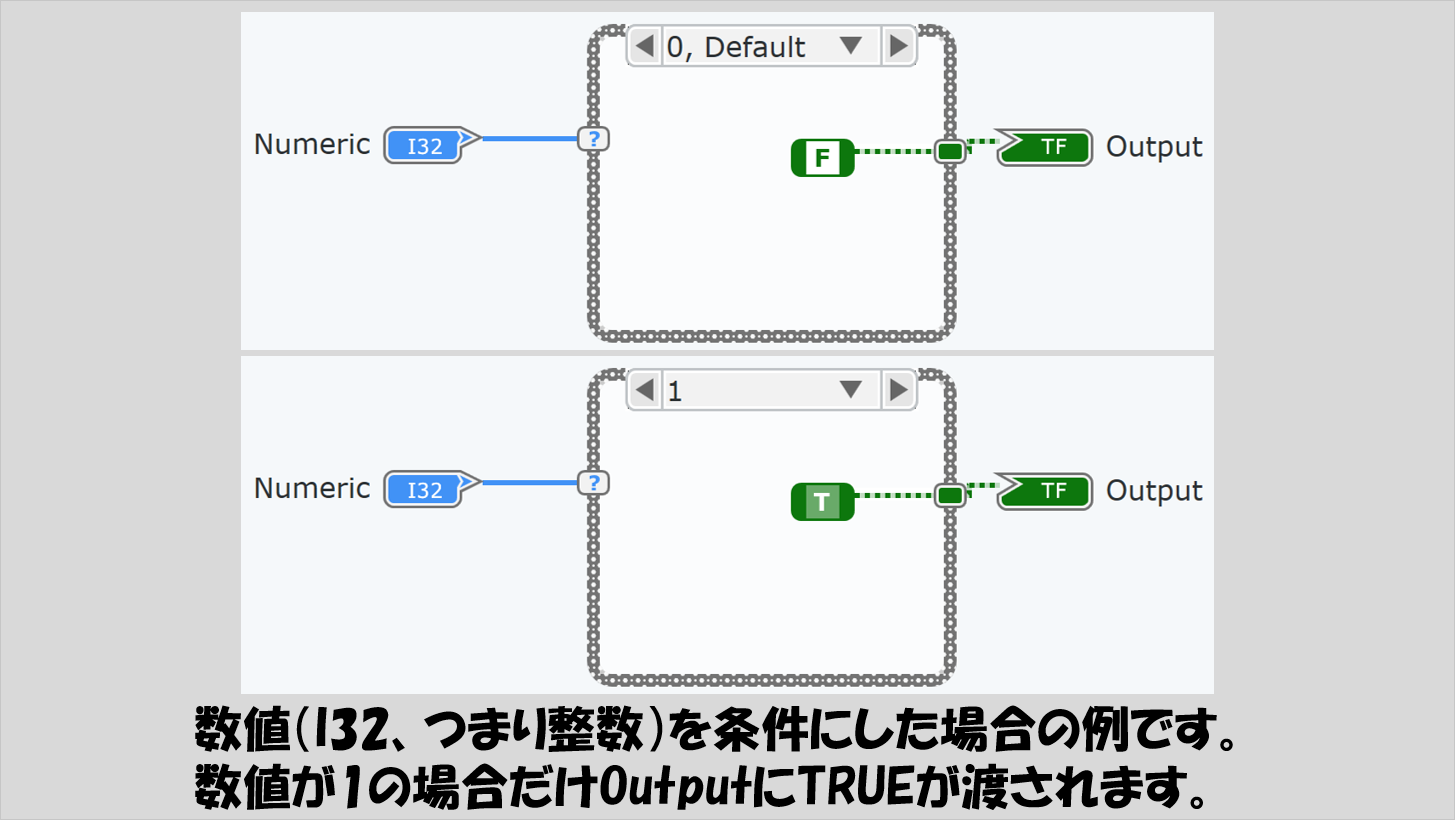
この例では、数値(Numeric)制御器の値を条件としています。定義したのは数値として「1」がケースセレクタに渡った場合だけですが、数値なんていくらでもあるわけなので、それ以外の値が来たら定義されていないことになる・・・と思いきやそうはなりません。
定義した以外の値、例えば777が入力された場合でも、プログラムとしては何かしらを実行しないといけません。そんな場合にデフォルトケースが実行されることになります。
上の図では、「0,デフォルトケース」と書かれたケースがありますが、これは「数値として0か、あるいは定義していない値が来たらこの中の処理を実行しますよ」という状態を表わしていることになります。
ケースは今表示しているケースの前か後ろに追加できる(前であるか後ろであるかに本質的な違いはなく、単に並び上の問題)ので条件を増やすこともできますが、それらすべてに当てはまらない値が来た場合には全て「デフォルト」の内容が実行されることになります。
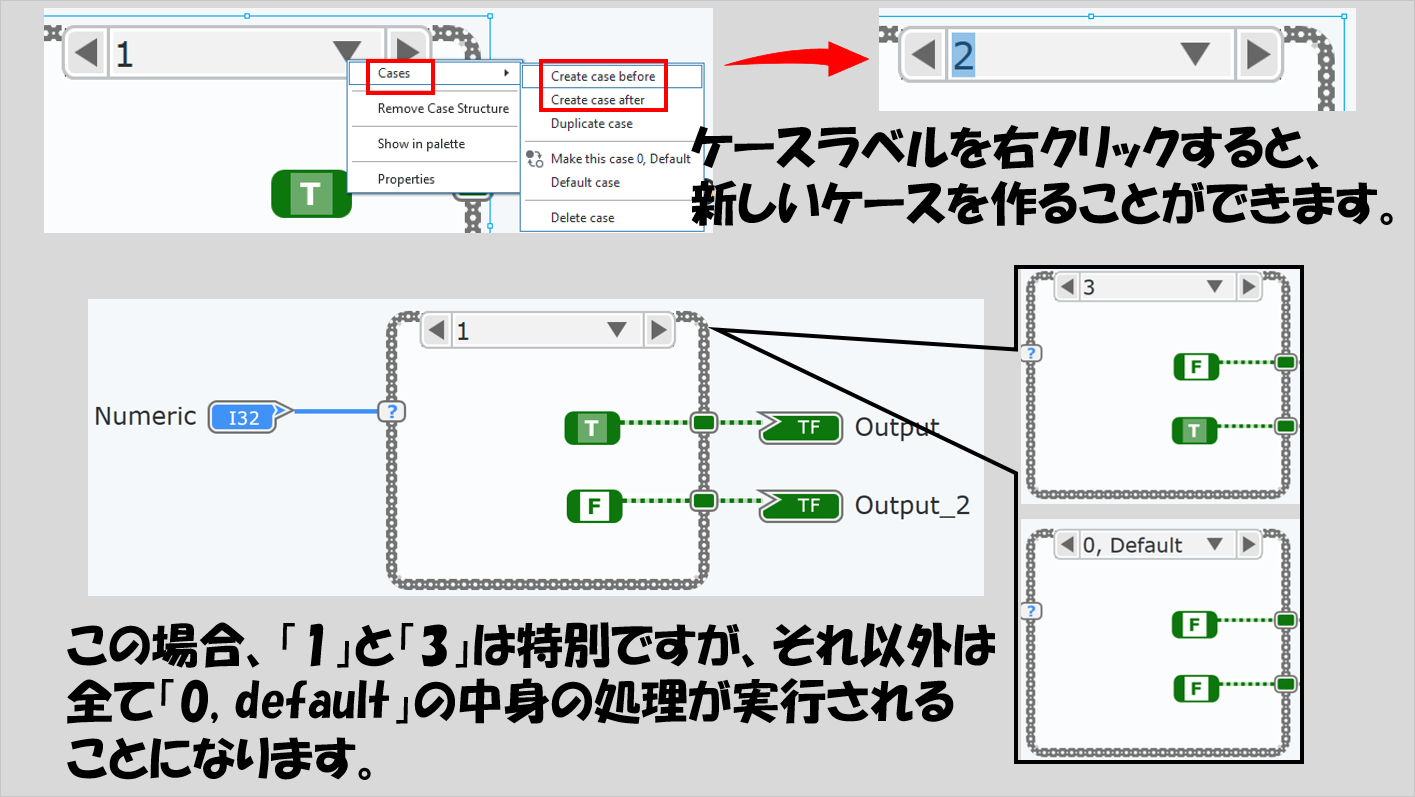
ケースストラクチャを作成し、あるデータタイプで条件を判定させるようにした場合、そのデータタイプのデフォルトデータが勝手に選ばれる(例えば数値なら「0」、文字列なら空文字)ことになりますが、これは後から変更可能です。

なお、デフォルトケースは、単体で存在させることもできます。が、どちらにしろ必ず用意する必要があります。そうでないとGWDSとしては定義されていない値が条件判定に渡されたときに何をしていいかわからなくなるからです。

例外は、ブールデータで条件を判定する場合です。ブールはTRUEかFALSEの二択なので「どちらにも当てはまらない」ということが起こりえず、したがってTRUEとFALSEの中身を用意するだけです。
出力トンネルはすべてのケースで定義する
ケースストラクチャでは、出力トンネルはすべてのケースで定義する必要があるのも重要です。
出力トンネルという言葉自体は繰り返しの構造であるループでも出てきました。これをすべてのケースで何かしら定義する必要があります。
定義をしていない場合、プログラムとしてはそのケースストラクチャが終わった後に何を結果として表示させればいいかわからなくなるため、とにかく何かしら出力するようにコードを書く必要があります。
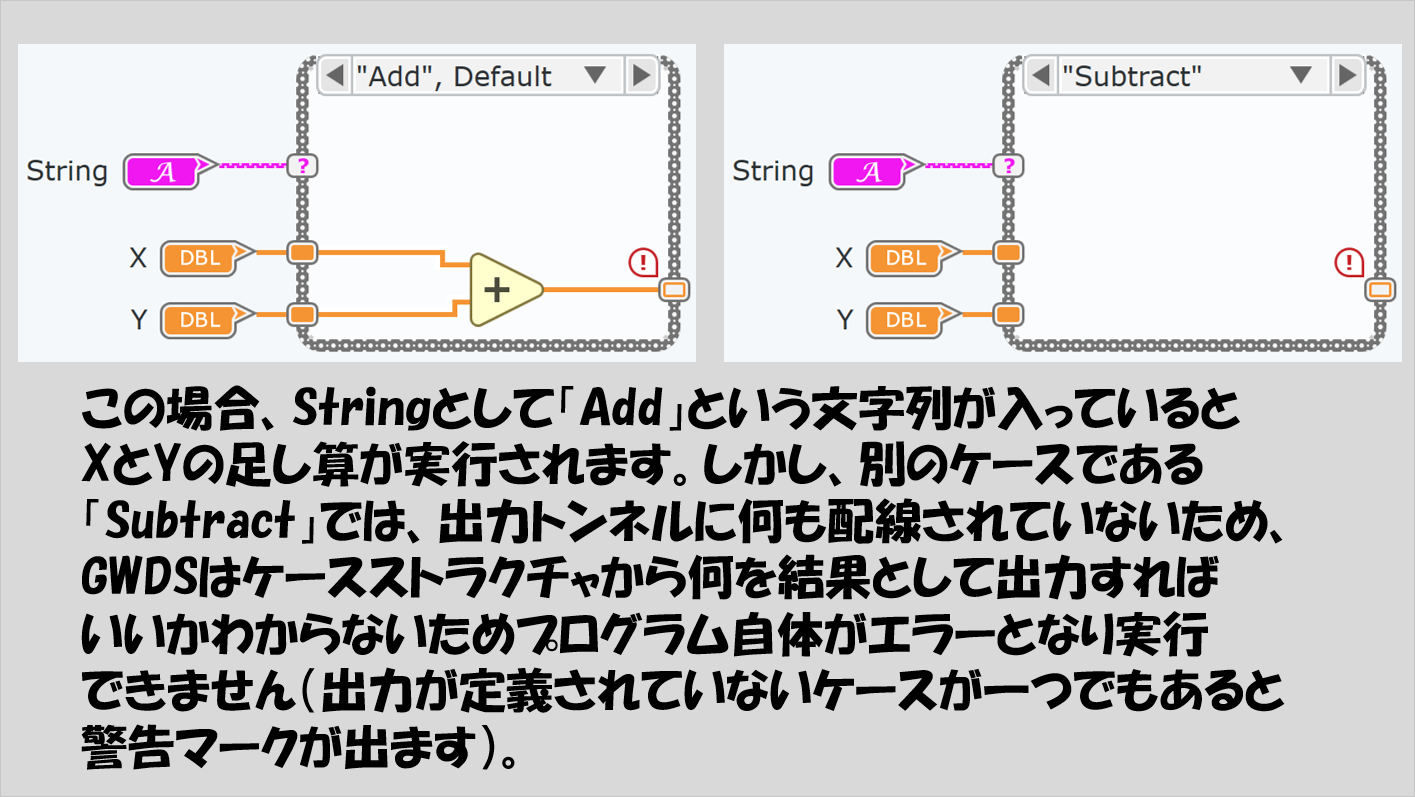
「特に決めていないよ」という場合にも何かしら出力させる必要があるのですが、「ほんとうに何でもいい」ということであれば「(その出力トンネルのデータタイプの)デフォルトデータ」を出力させるように設定することができます。
デフォルトに設定された出力トンネルは、白抜きでも、塗りつぶしでもない、特殊な表示になります。
これは、一つ前のトピックとして紹介した、ケースとしての「デフォルトケースを決める」のとは全く別なので注意してください。
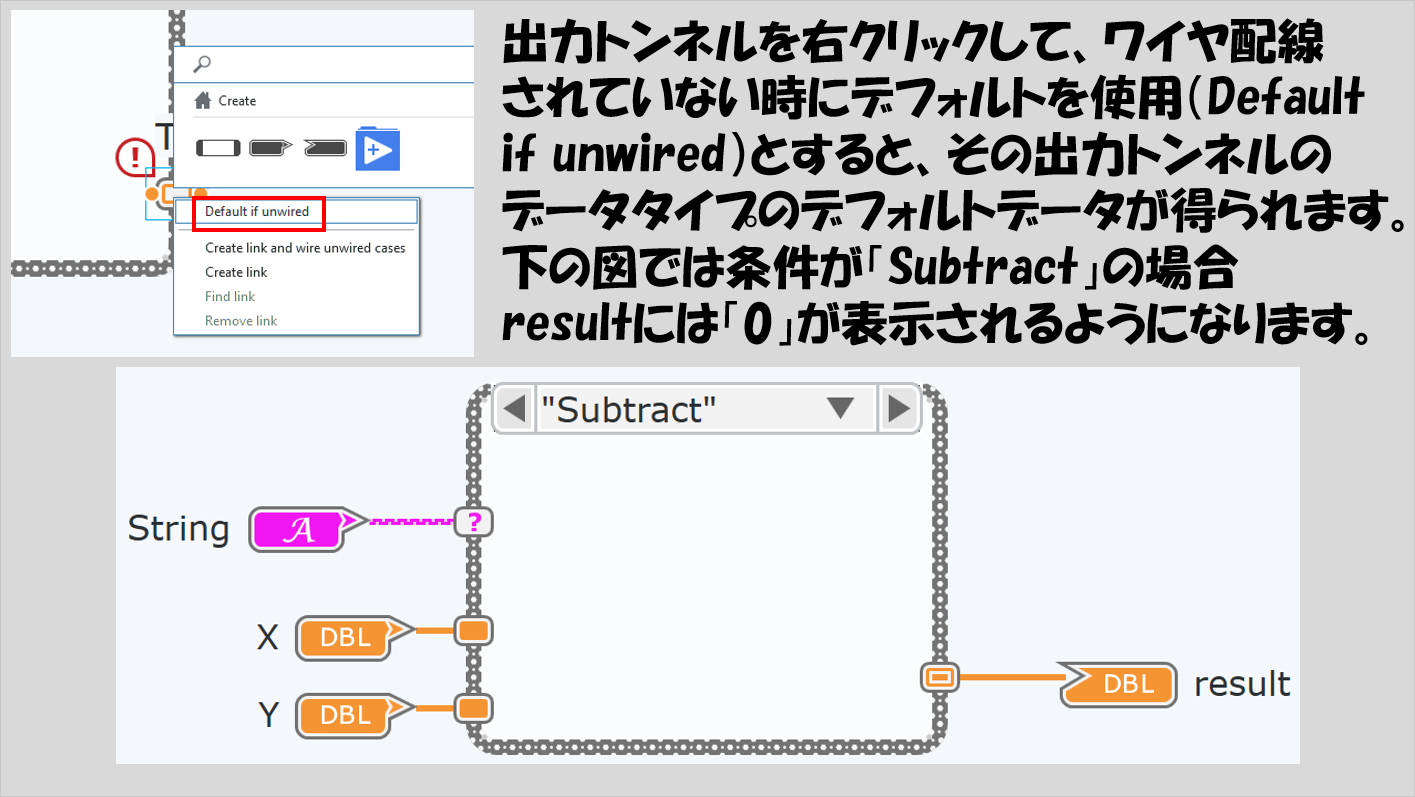
各データタイプのデフォルト値とは、例えば数値なら0ですし、ブールならFALSE、文字列なら空白、などと既に決まっています。ある特定の条件でだけ特定の出力を行いたくてそれ以外の条件の場合はどうでもいい、というときにはこの方法が便利です。
様々なデータタイプのケースストラクチャ
基本的な使い方は以上になるので、あとはいくつか、様々なデータタイプの条件を使用した場合のケースストラクチャの使用法についてざっと紹介します。
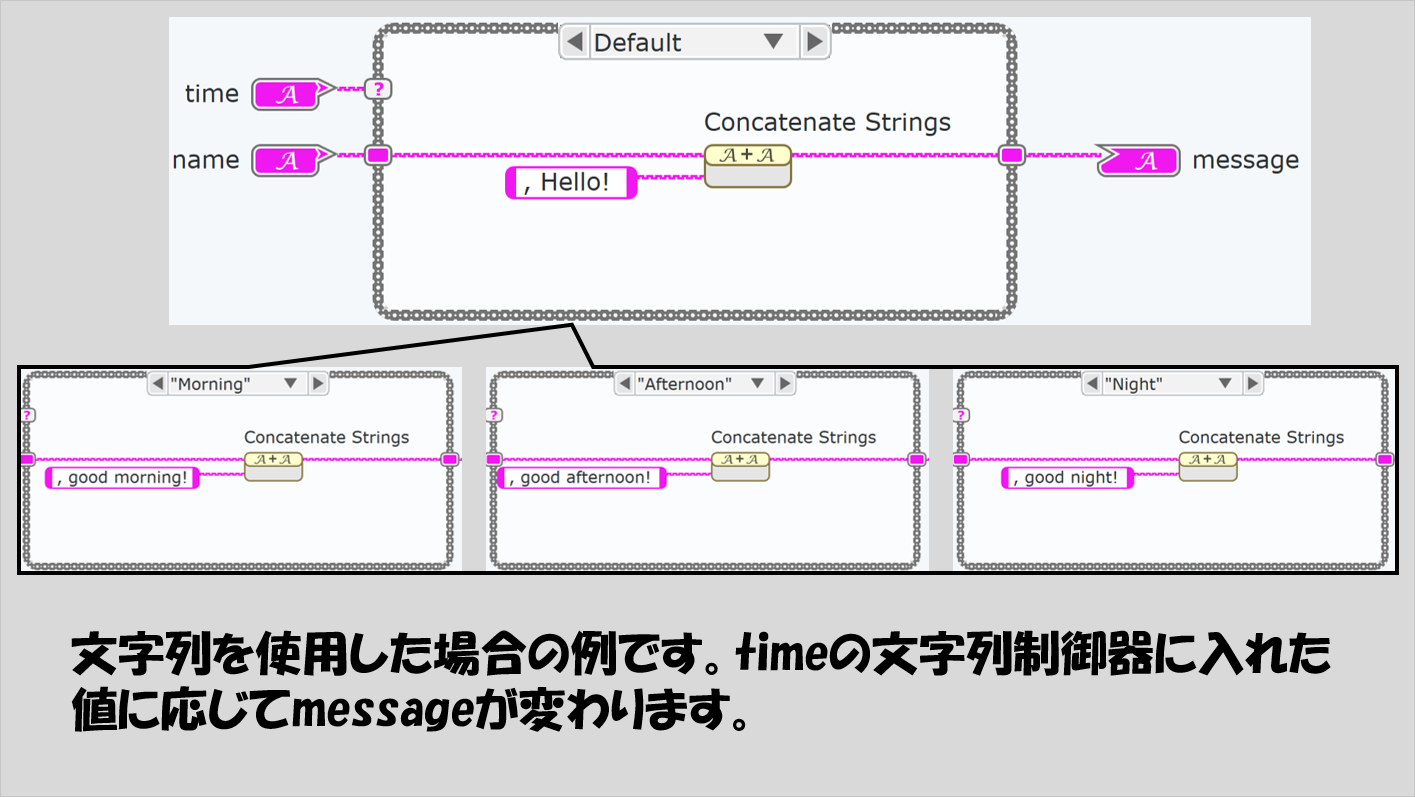
まずは文字列を条件にした場合。特定の文字列が入ってきたら特定のコードを実行させることができます。
以下では、どのケースにも共通してnameという文字列制御器を渡し、ケースに応じて違う挨拶の内容を文字列連結の関数で追加するようにしています。
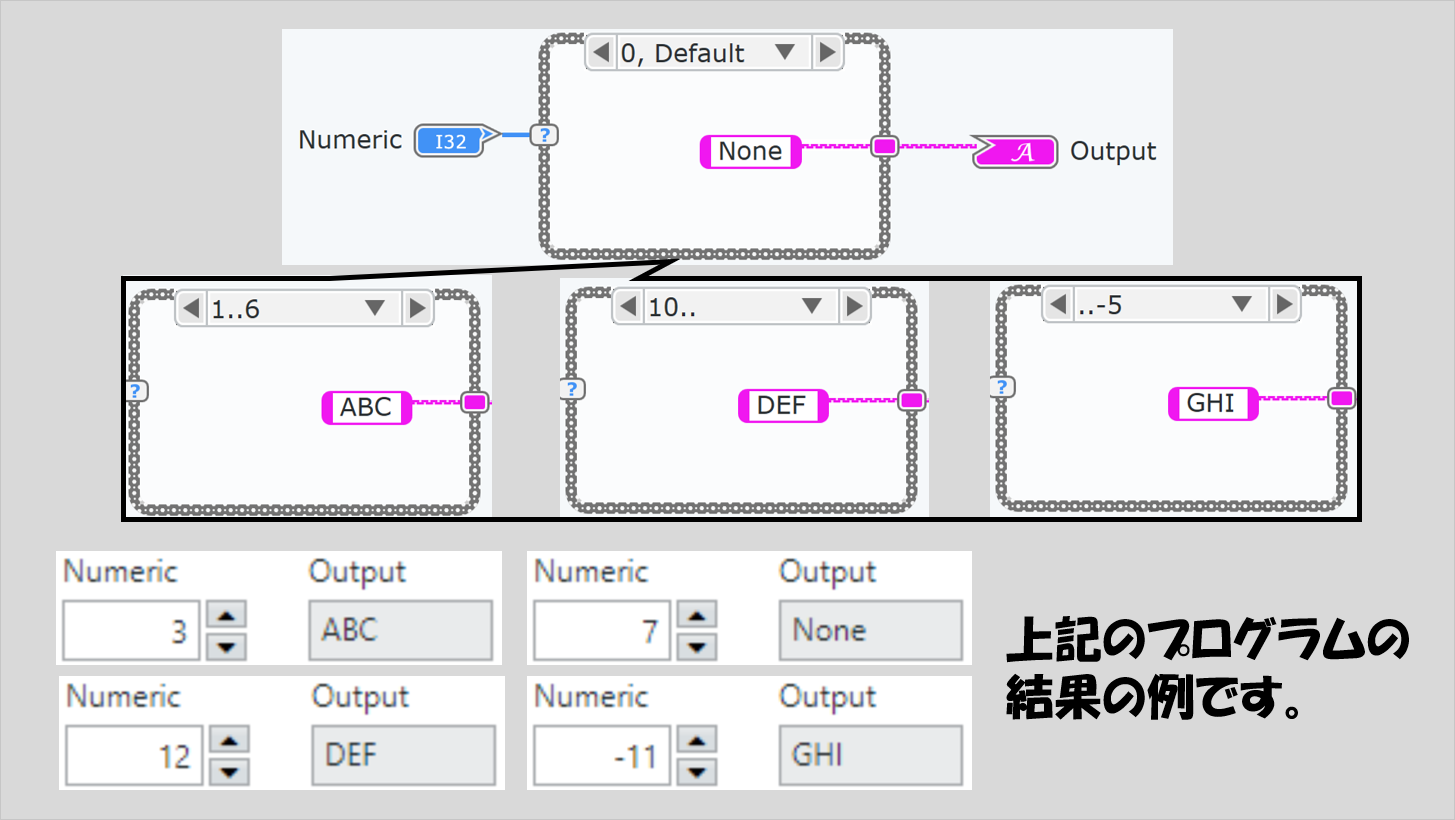
次に数値を条件にした場合。数値は、範囲を指定して条件を作ることができます。
例えば、「1..6」と指定すると、これは「1から6まで」と指定したことになります。また、「10..」と指定したとすると、「10以上」という指定になるし、「..-5」であれば「-5以下」という指定になります。
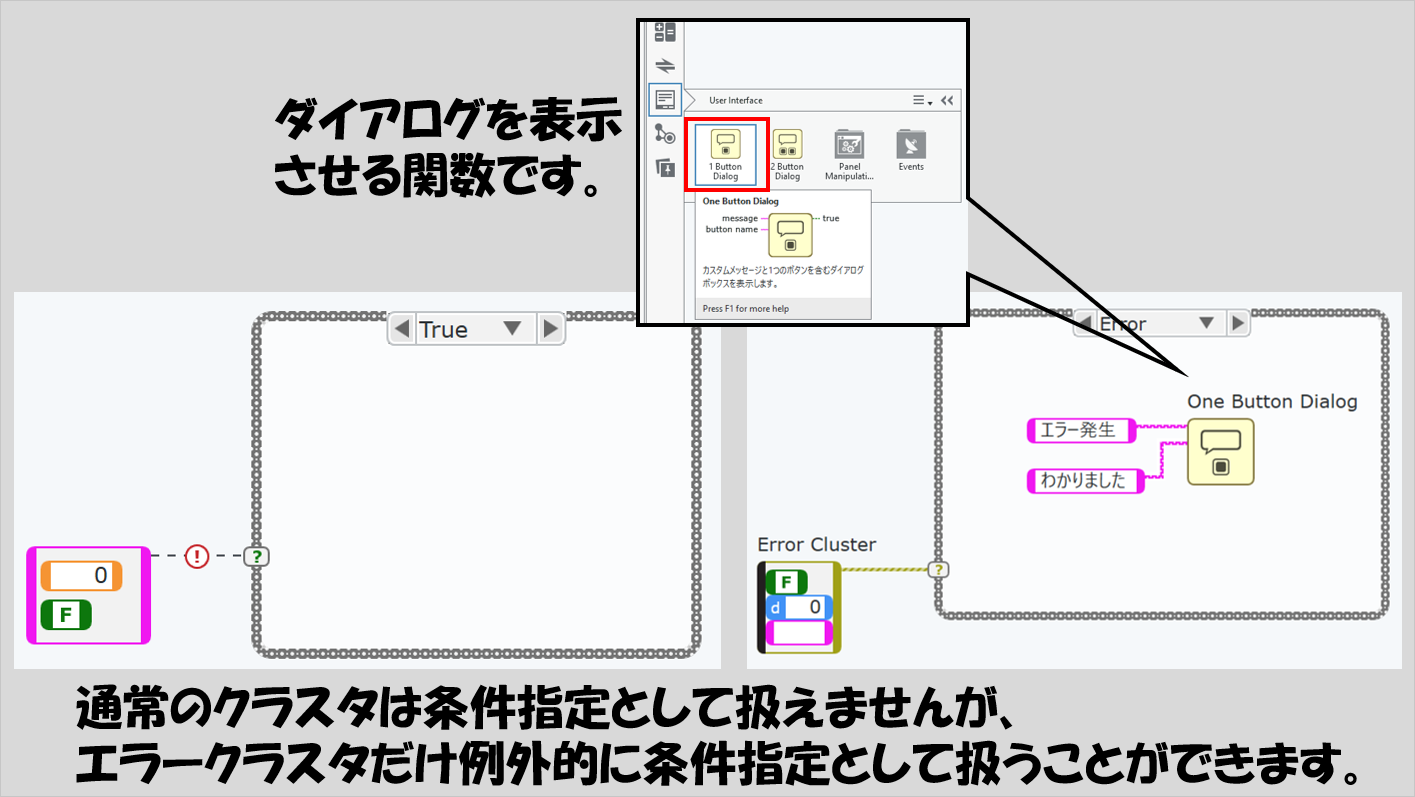
エラー処理の一環として、エラークラスタを条件とすることができます。エラーが起きたら特定の処理をさせる、といったことができるようになります。
なお、通常のクラスタはケースに選べないので注意してください。
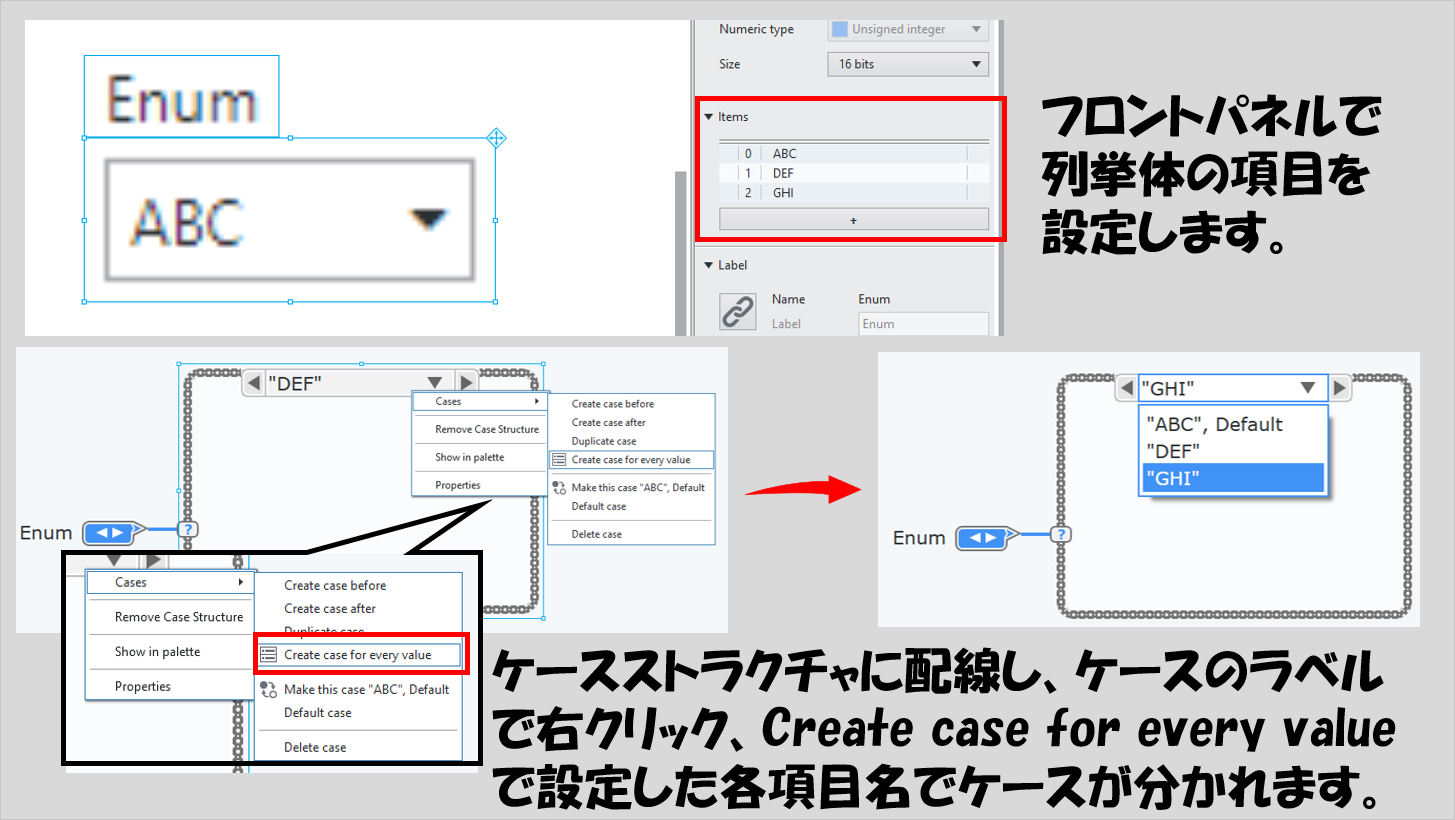
また、列挙体を配線することで、列挙体で指定した項目名でケースを分けることができます。
列挙体はそもそも、ユーザーが選択肢の中から選べる項目を列挙している制御器/表示器だったことを考えると、「列挙された項目から選ばれた任意の文字列の内容に従って処理を分けられる」と言えます。
単に列挙体を用意して、これをケースストラクチャの条件に設定、右クリックでCreate case for every valueを選ぶと、列挙体に定義していた複数の項目名が自動的にケースストラクチャのケースラベルに表示されるので、あとはそれぞれの項目がユーザーに選ばれたときの処理を書きます。
まずはこれらのデータタイプで条件分岐の仕組みについて慣れていけばいいかなと思います。
タイマーを作る
使い方だけ見ても面白くないので、具体的なプログラムを作ってみます。
今回は、ケースストラクチャも使用してかつ繰り返し処理の復習も兼ねて、タイマーを作ってみることにします。
仕様としては以下のような動作をするプログラムを考えます。
- タイマーで測りたい時間を設定する。
- 開始のボタンを押すと時間の測定を行う
- 指定の時間までをカウントダウンする
- 別の時間を設定して開始するとカウントダウンする値も新たな設定時間通りになる
完成例を以下に見せるので、まずは自力でこういったプログラムが作れるか試してみるのもいいかもしれません。

こういったプログラムを作る場合には、繰り返しはもちろん、設定した時間が経過したことを判定するフラグを作ることもできると便利です。
答えは一つではないと思います。きっともっとうまい実装方法があるかもしれませんが、プログラムのダイアグラムの例を以下に紹介します。
以下では、表示しているケースストラクチャの他のケースも吹き出しの中に表しています。
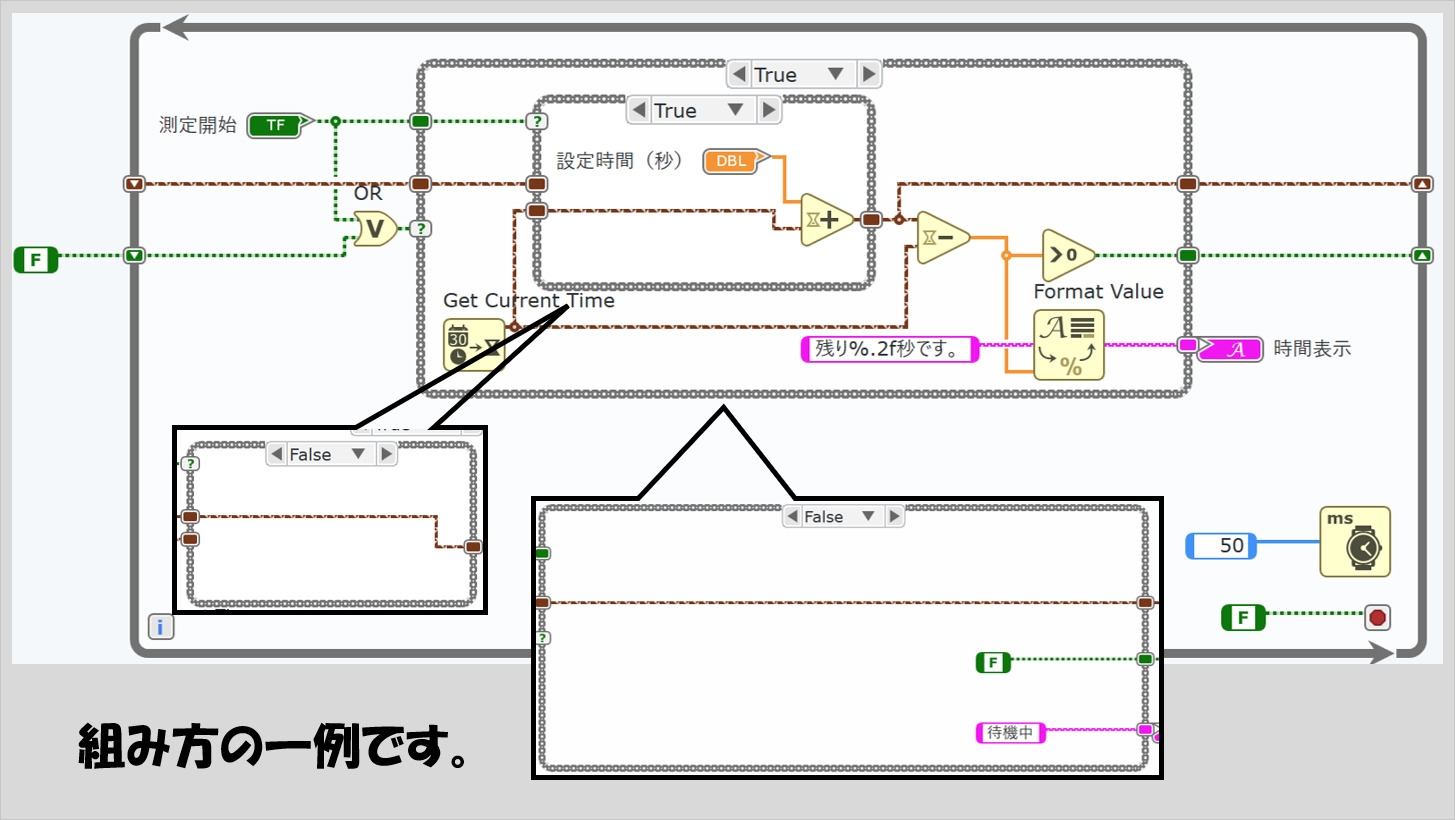
・・・と、紹介したはいいのですが、このプログラムはあまりきれいではないかもしれません。ケースストラクチャの中にさらにケースストラクチャが入っているからです。
当然、プログラムによってはやむを得ない場合もありますが、ケースストラクチャはその性質上、ダイアグラム上に見えているのは複数あるケースの一つだけで、他のケースを見るためにはケースを変える操作を必要とするので、それが何個も入れ子になっているのは見にくく、できれば避けたいところです。
そんな時便利な関数が選択関数です。この関数は、真ん中の入力がブールになっていて、その値がTRUEかFALSEかで出力値を変えることができるようになっています。
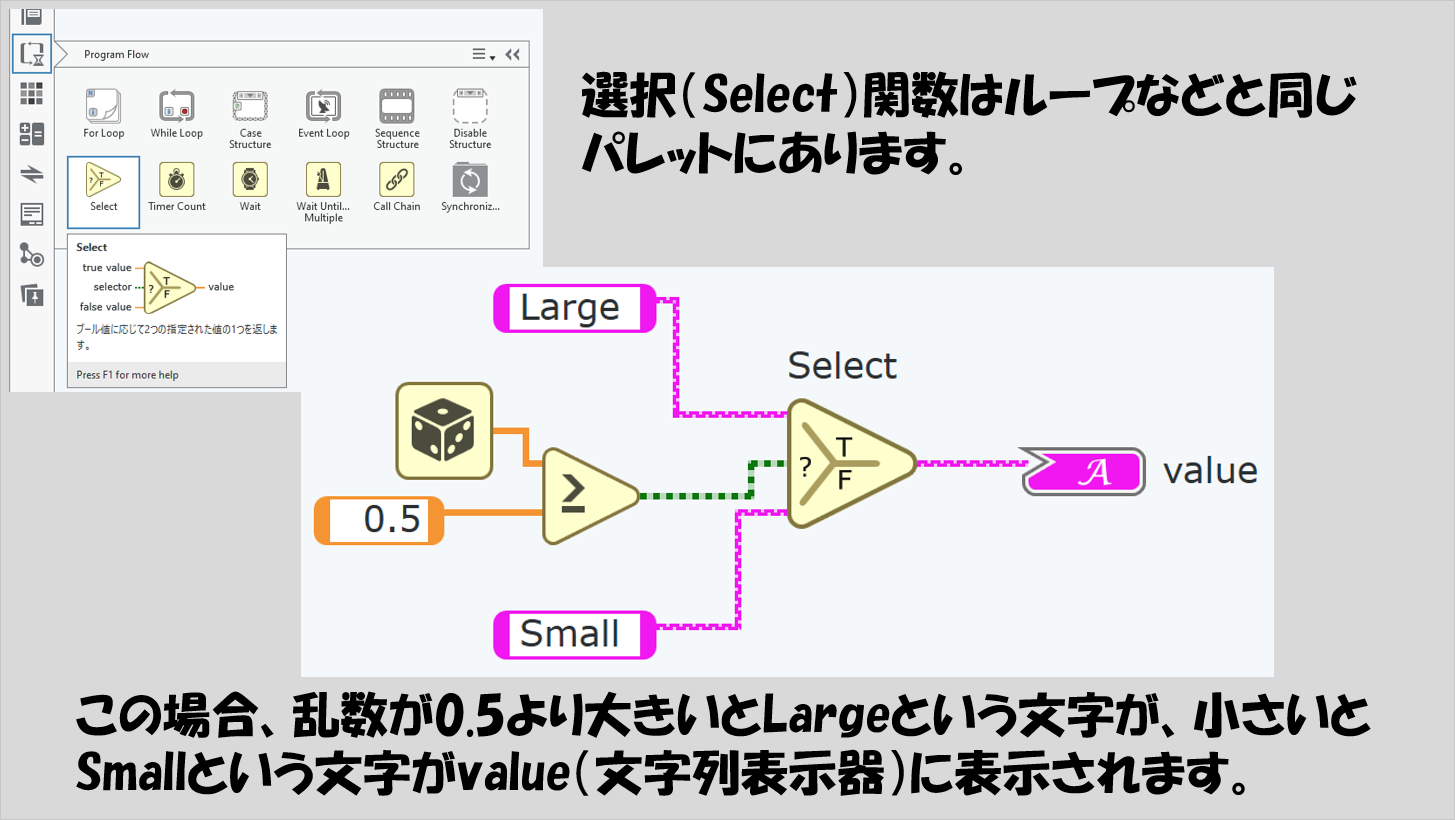
なお、上の図では文字列を使用していますが、他のデータタイプでも構いません。ただし、入力の真ん中はブールで固定で、上下は同じデータタイプである必要があります。そして、出力はこれら上下のデータタイプと一致させます。
この選択関数を用いて上のプログラムを書き換えると次のように書けます。
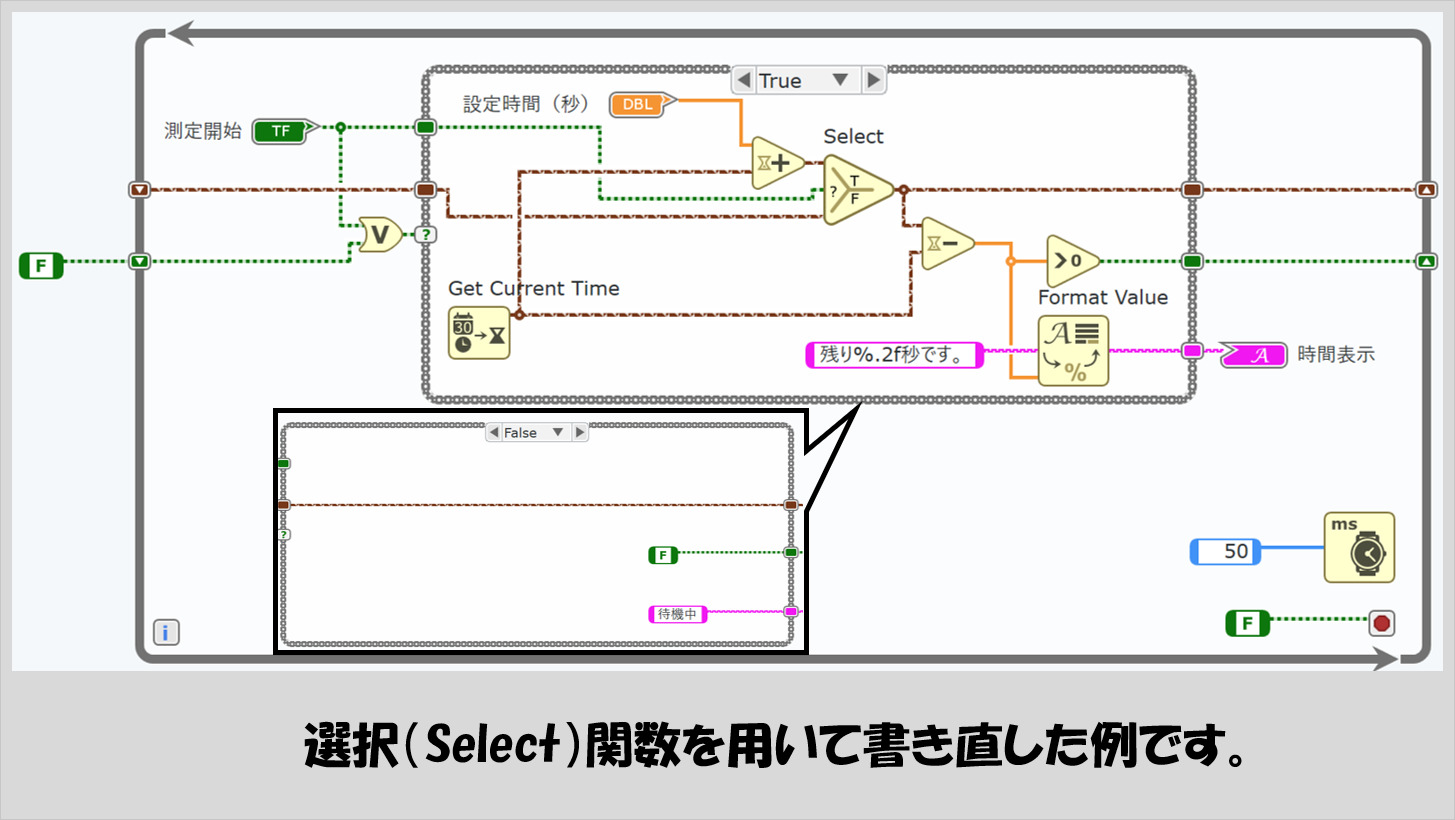
ケースストラクチャは一か所使用していますが、内側のケースストラクチャはなくなりました。3つある入力の真ん中でブールデータの入力を入れ、TRUEのときとFALSEの時とで出力する値を変えることができるようにしています。
選択関数はブールでの入力を必要とするので、二択の場合にしかケースストラクチャの代用になりえないですが、ボタン操作に対する応答などで活躍する関数なので覚えておいて損はないと思います。
今回の記事では、条件分岐の方法を紹介しました。条件分岐は、繰り返し処理と同じくらい、プログラミングを行う上で必ず覚えておく必要があるものです。
ループの時に説明したように、枠組みに囲まれた処理は全て実行し、また入力や出力の概念があることなど共通しているため、ループについて扱い方をわかっているのであれば条件分岐の扱いも特別難しく感じることはないと思います。
ところで、最後に紹介したプログラムは測定開始ボタンの状態をループの中で毎回判断してTRUEかFALSEかで状態を変更していました。
測定開始を押していない場合には待機中と表示するのはいいとしても、測定開始を押さない間ずっとFALSEケースを実行し続ける、いわば「空回り」状態になっています。
こういった無駄な動作が入る組み方は、効率がいいとは言えません。そこで次回の記事では、より効率のいいプログラムを作るための仕組みであるイベントストラクチャについて紹介してようと思います。
もしよろしければ次の記事も見ていってもらえると嬉しいです。
ここまで読んでいただきありがとうございました。
コメント