この記事で扱っていること
- 配列の要素の種類と位置を調べる方法
を紹介しています。
注意:すべてのエラーを確認しているわけではないので、記事の内容を実装する際には自己責任でお願いします。また、エラー配線は適当な部分があるので適宜修正してください。
プログラムの目的によって、データの扱い方は様々あると思いますが、今回は配列に着目しています。
配列の要素は、ソートの関数を使用して特定の順番に並び替える場合もありますが、ある瞬間での順番そのものが重要である場合があります。
(波形データを構成する一要素であるY値配列も、要素の順番が重要であり、ソートをかけたら意味がないですよね)
そんな場合に、その配列に何種類の値が含まれており各値は配列のどこにあるか(要素番号)という分布を知る必要があったため、そのための処理を考えてみました。
配列の要素としては様々なデータタイプをとりえ今回は例として数値の配列と文字列の配列を扱っていますが、どのようなデータタイプであっても考え方は同じです。
どんな結果になるか
例えば以下のような配列が得られていて、この中に各要素はどこにいくつかあるか、ということを調べることになります。
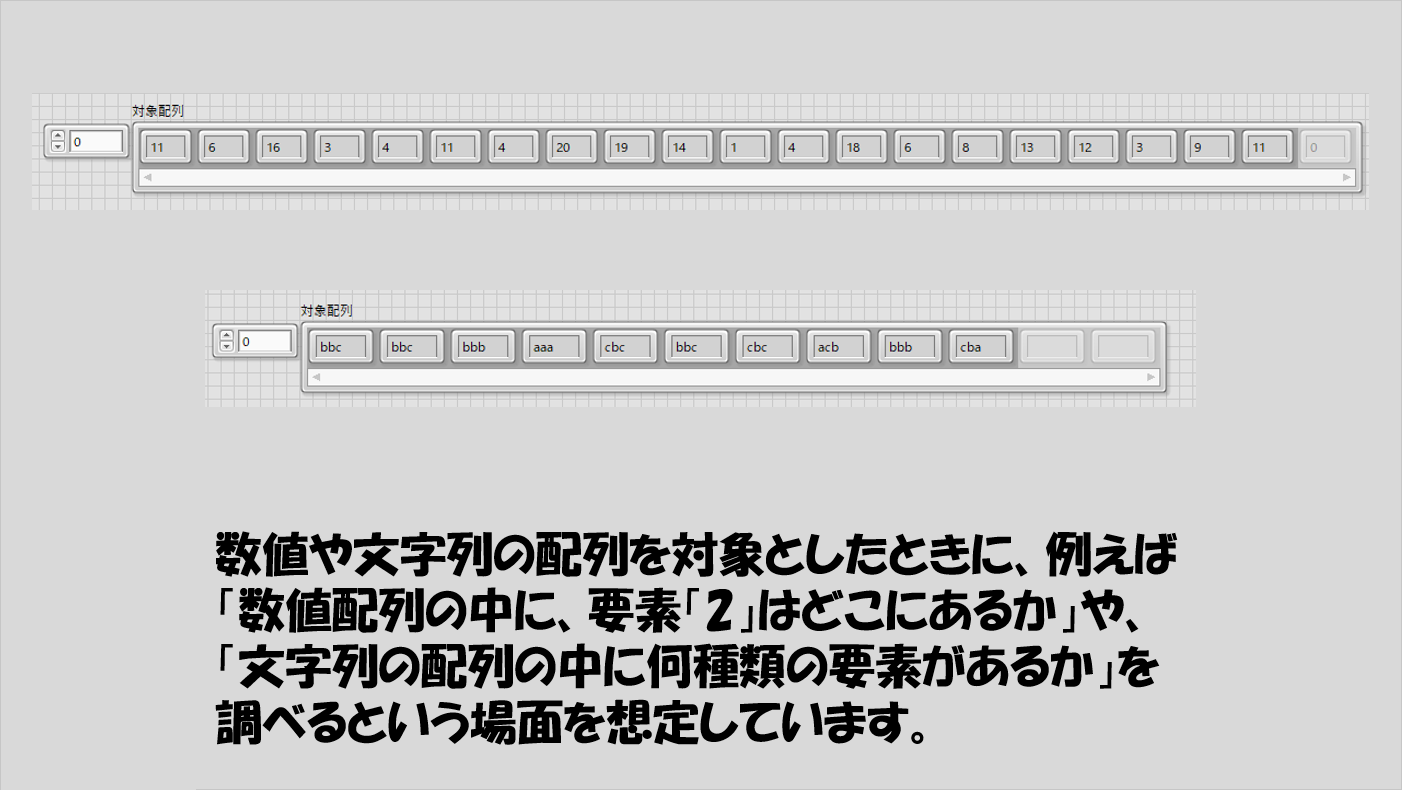
調べた結果としては以下のような情報を得ることになります。
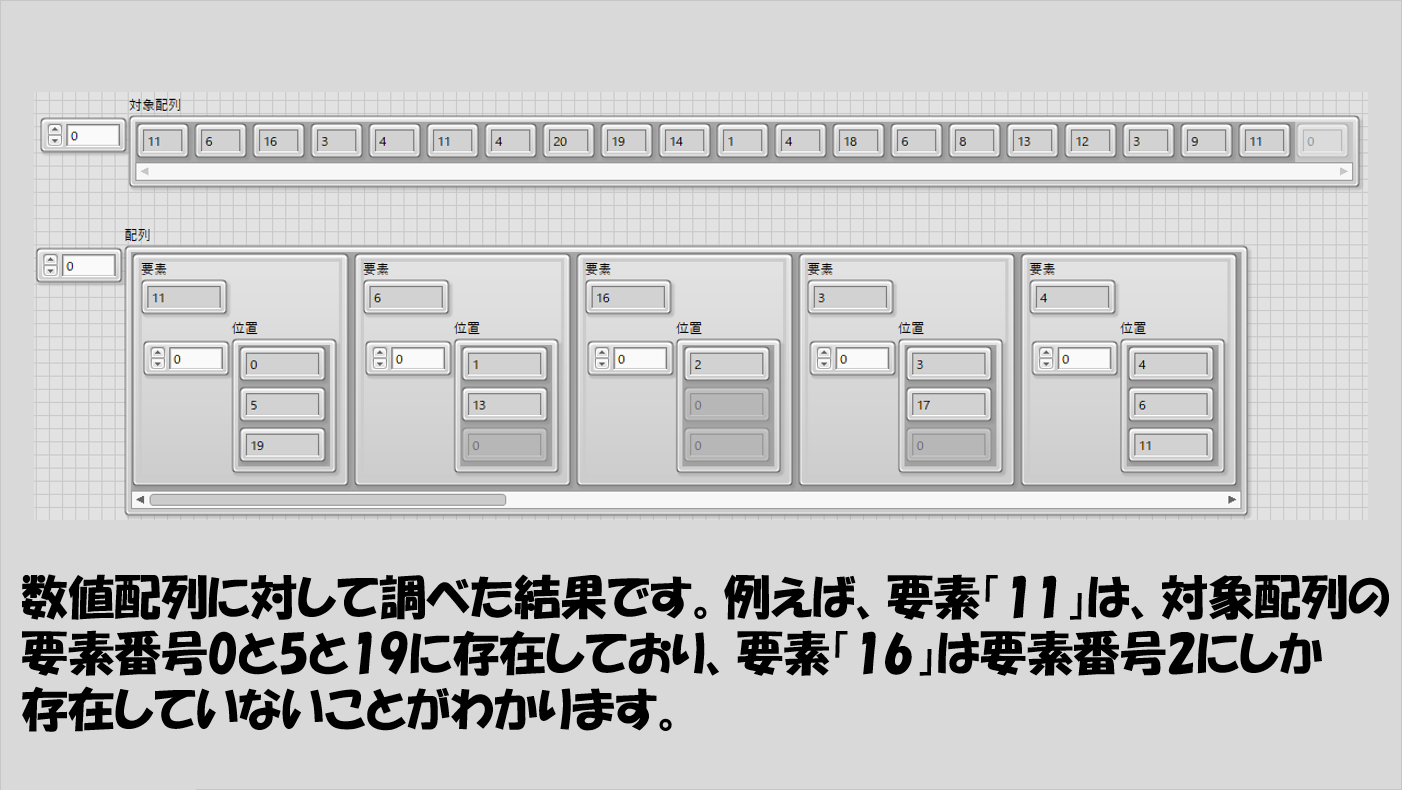
まずは数値の配列の場合。
例えば要素「11」というのは対象の配列の指標番号0と5と19にあります。
要素「16」は指標番号2にしかない、ということも一目でわかります。
文字列であっても同様な処理ができます。
要素「bbb」は対象配列の指標番号2と8にある、と結果が得られ、実際に確かめてみるとその通りです。
もちろん、対象配列の要素数がもっと増えても対応できます。

プログラムの構造
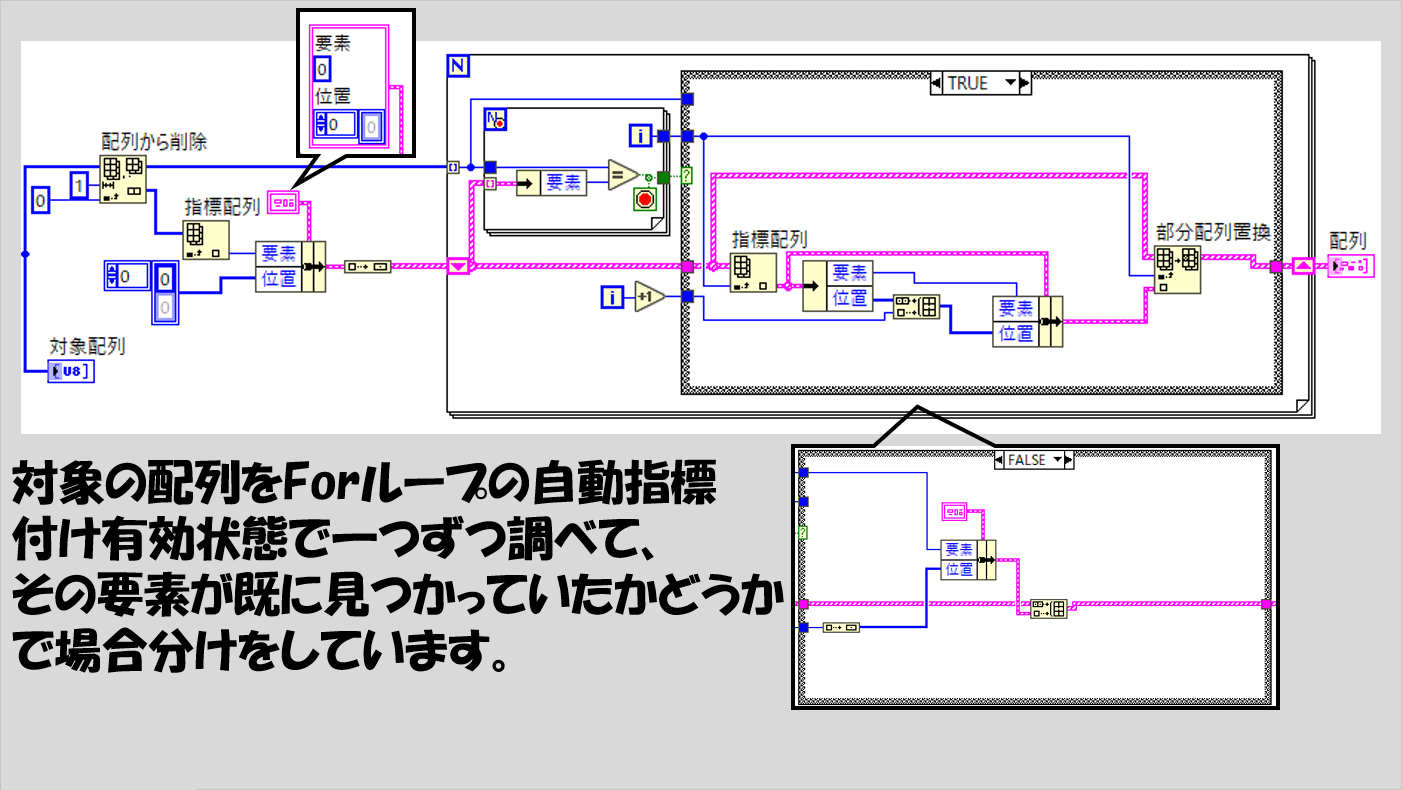
考え方としては単純で、配列の要素を一つずつ調べて、既に存在していた要素なのかどうかを判定し、結果を表示するクラスタ(の配列)に対して、Trueならその要素番号を追加していく、Falseならその要素自体を追加していく、という作業を繰り返します。
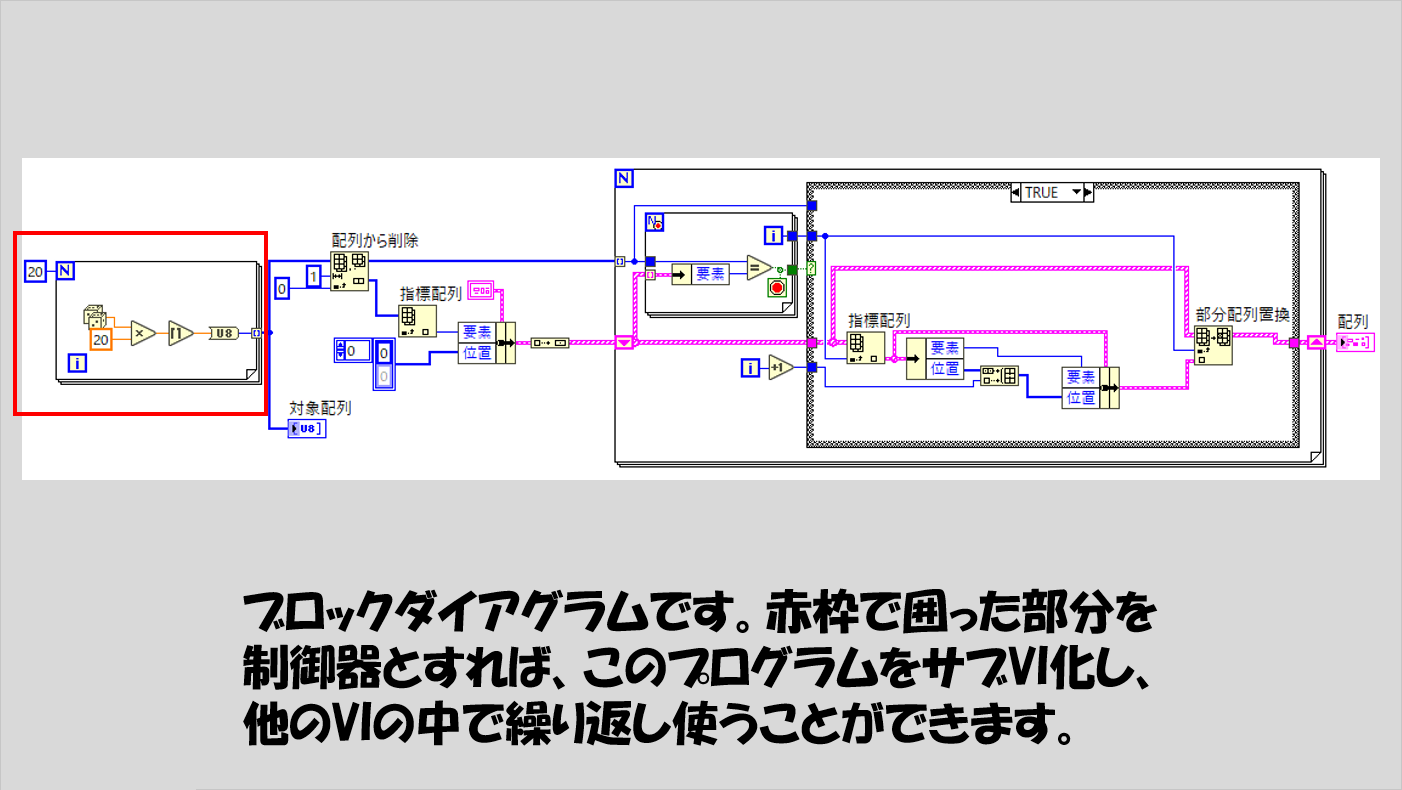
いっけん分かりづらいかもしれないですが、最終的な値の見せ方である、要素そのものとその要素がどこにあったかを表す配列のクラスタをあらかじめ用意してこのクラスタの配列を扱うように意識すると理解しやすいと思います。
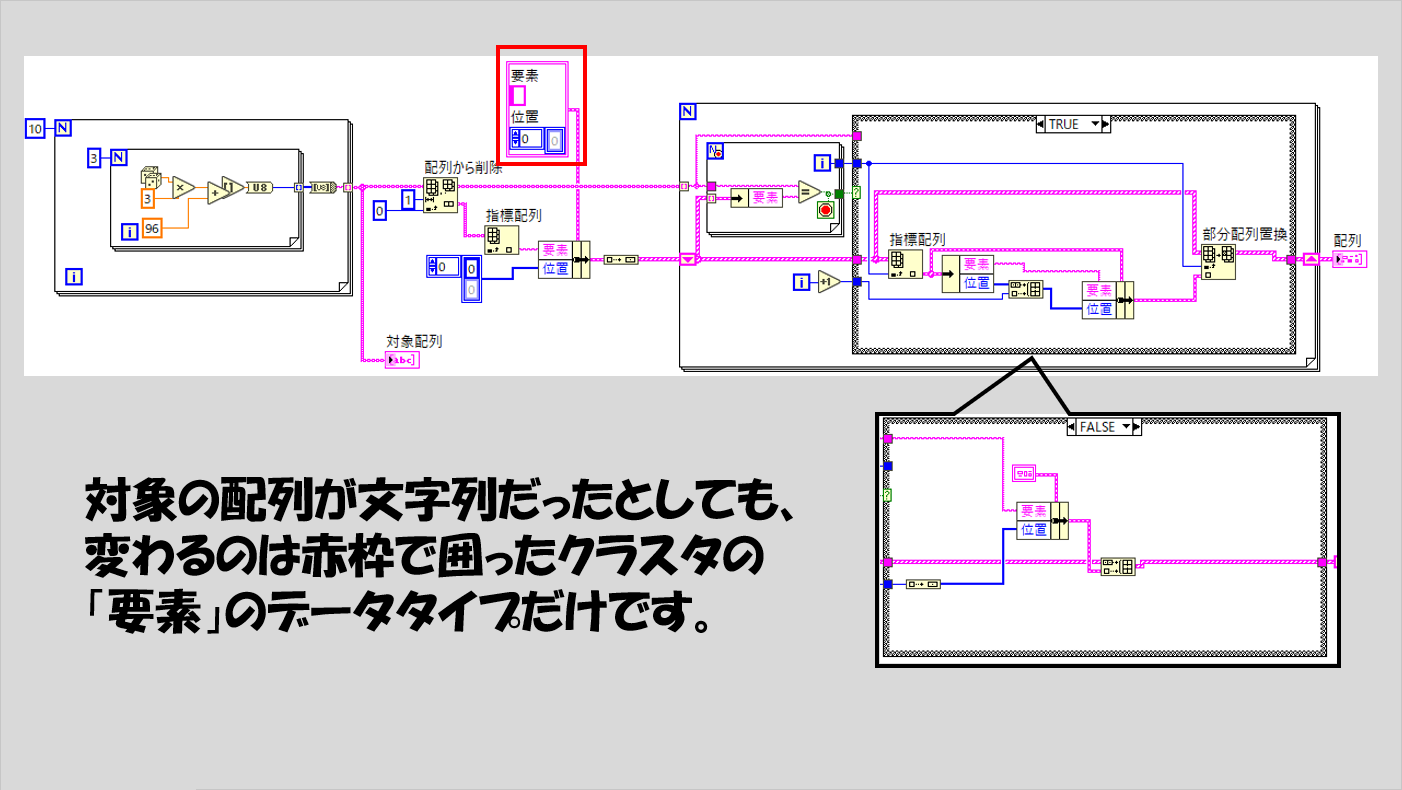
データタイプが異なってもこれは一緒ですね。
最終的に結果を表示するクラスタ配列の、クラスタの「要素」のデータタイプを変えるだけです。
最頻要素とその個数を調べる場合
単純に、対象となる配列上で、何種類の要素がそれぞれどこに存在しているかを調べるだけでなく、その配列に最もよく出てくる要素は何でその個数は何個か、という情報が重要になる場合もあります。
これを調べられるように、各要素が登場する回数をもクラスタの要素としてしまい、最終的にその情報をもとに最頻要素を特定することができます。
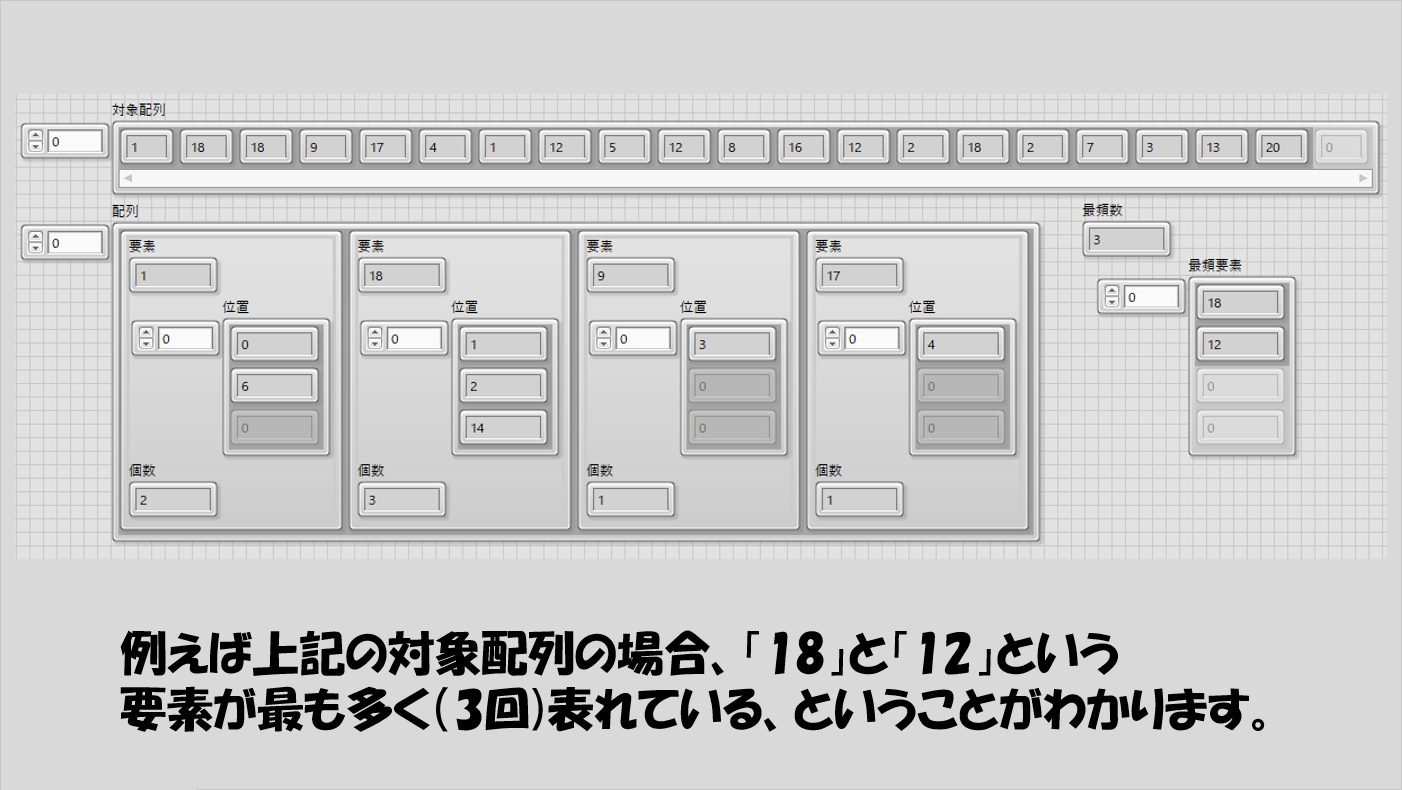
例えば以下の場合、対象配列の要素として表れる値で最も多く表れているのは「18」と「12」で、その回数はどちらも3回、ということがわかります。
最頻要素の調べ方は、もしかしたらもっとうまくできるかもしれませんが、とりあえず考えたままに実装すると以下のような形が考えられます。
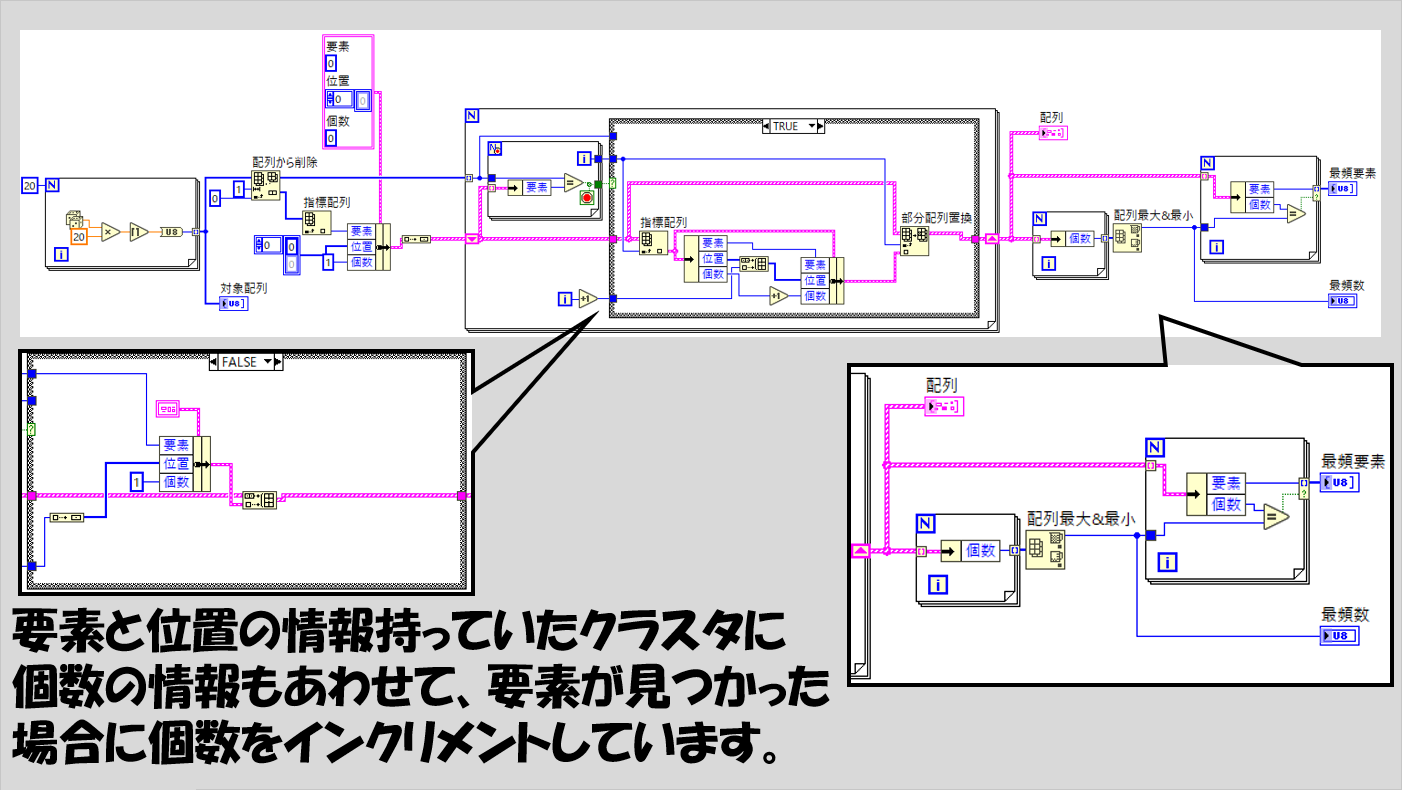
あるいは、いったん「要素とその要素が表れた指標番号を要素にもつ配列」のクラスタ配列のみを求めておいてから、後から各配列のサイズを求めて最頻要素を求めるという方法でもいいと思います。
本記事では、配列要素の種類とその位置を調べる方法を紹介しました。
データの扱い方はプログラムの目的によって様々で、ある配列の特徴を調べる際の特徴量の抽出に役に立てばうれしいです。
ここまで読んでいただきありがとうございました。
コメント