
この記事では、LabVIEWの特徴である、簡単に実装できる並列処理に関連したデータの処理方法についての比較実験を行った結果を紹介しています。
並列処理の実装で、それぞれの並列ループが全く何のデータも共有せずに独立して動作するという場合もありますが、ある程度モジュール化を意識したプログラムを設計したときには、何らかの方法でデータを共有させて処理を進めていく、というプログラムになることが多いと思います。
そんなときに、どのようにデータを渡すのか、というのはいくつかの種類の方法があり得るかと思いますが、それらについてパフォーマンスを比較するための簡単なコードを試しました。
恐らく、この記事で紹介している結果はどのようなPCであっても、LabVIEWというソフトウェアを使い続ける限りでは大きく傾向は変わらないと思います。
ただし、実際のテスト結果で示している具体的な数値の結果については多分に環境に依る部分が多いと思いますのでその点はご注意ください。
ループ間でデータを渡す方法
まずは、ループ間でデータを渡す方法にはどのような種類があるか、についてみていきます。
プログラムのある場所から別の場所に値を移すという操作にはどういった選択肢があるか、ということになりますが、ざっとこんな選択肢があると思います。
- ローカル変数
- グローバル変数
- シェア変数
- 機能的グローバル変数
- プロパティノード
- キュー
- ノーティファイア
- チャンネルワイヤ
- TCP

「ネットワークストリームはどうなの」とか「UDPもあるだろ」というご意見もありそうですが、同じvi内でデータを受け渡しする目的に限れば上で挙げたものが使えれば十分かと思い今回はこれらに絞って確認してみます。
(とはいえ、中には実際にはあまり「ループ間のデータの受け渡し」という用途では使わない方法も含んでいますが)
この中でどれが早く、どれが遅いと思うか、予想してから読み進めてください。
ちなみに、一番早いものと一番遅いものは、微妙な差しかない・・・のではなく、かなりパフォーマンスに差が出ます。
比較の仕方
パフォーマンスの比較の仕方についてですが、2種類のプログラムを使いました。
(1)「片方のループから1ミリ秒ごとに100個の異なるデータを送る間に、もう片方のループで何個受け取れるか」というプログラム
以下のような形のプログラムです(ローカル変数で値を受け取っている場合の例です)。
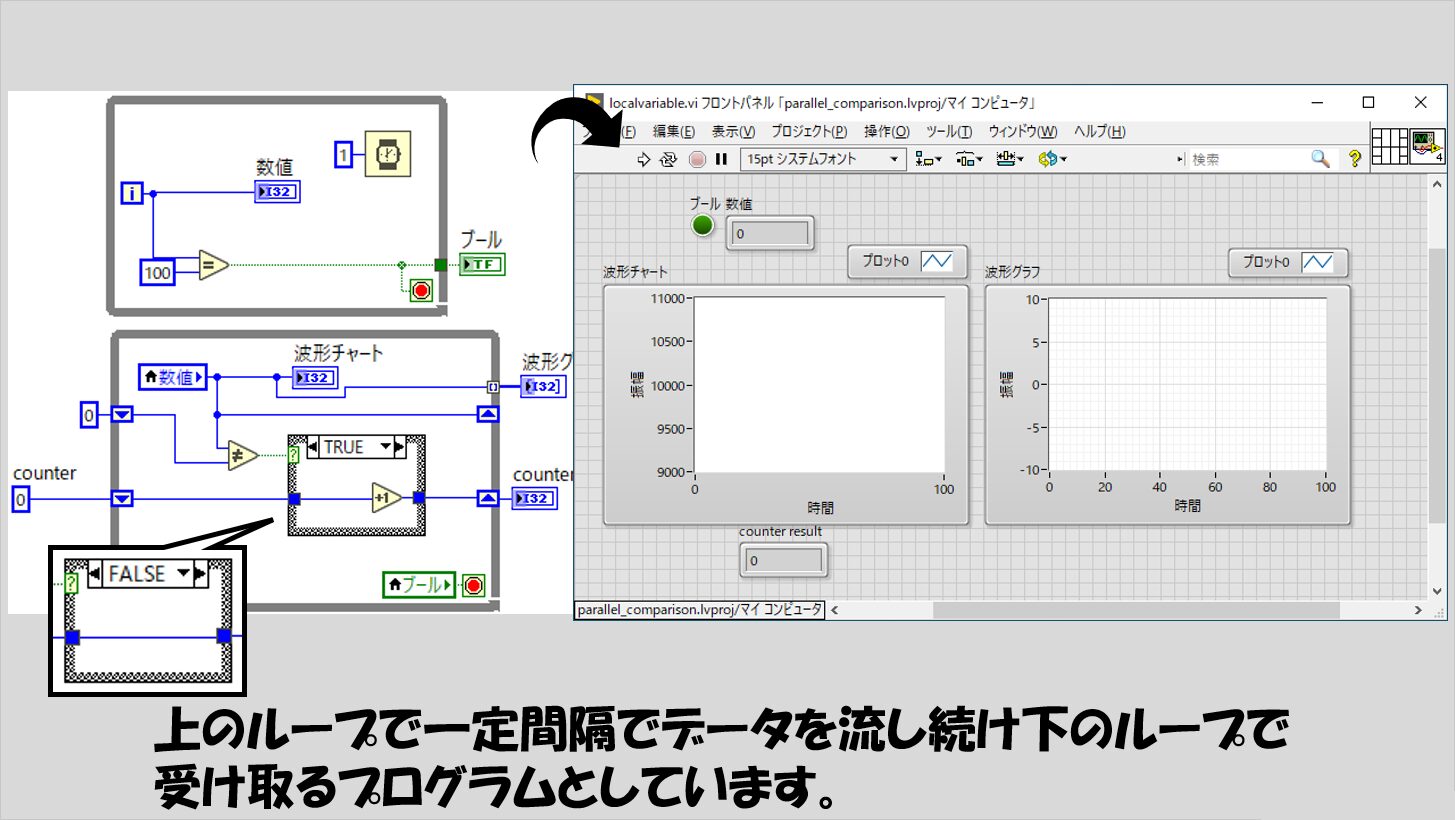
このプログラムを見ると、「counter resultの部分ってどの方法でも100近くになるのではないの?」と思う方もいるかもしれません。
確かに、ほとんどの方法で100に近い値になりますが、中には全然100に満たない方法があります。
また、この方法で下のループが終わった後に波形グラフに表示している理由は、「どれだけ無駄にループが回っているか」を表しています。
効率よく回っていれば、下のループは101回回れば上のループからくるデータを全部回収できるはずで、この場合波形グラフは綺麗な直線になるはずですね。
この波形グラフがギザギザな形になった場合、これはつまり同じ値を繰り返し読んだりあるいは値を飛ばしてしまっていることが考えられるため、無駄があったりあるいは目的に適った操作になっていないととらえることができるかと思います。
(2)「片方のループから異なるデータを送って、もう片方のループで10000種類のデータを受け取るまでどのくらいの時間がかかるか」というプログラム
こちらも、代表的なプログラムの例を挙げておきます。
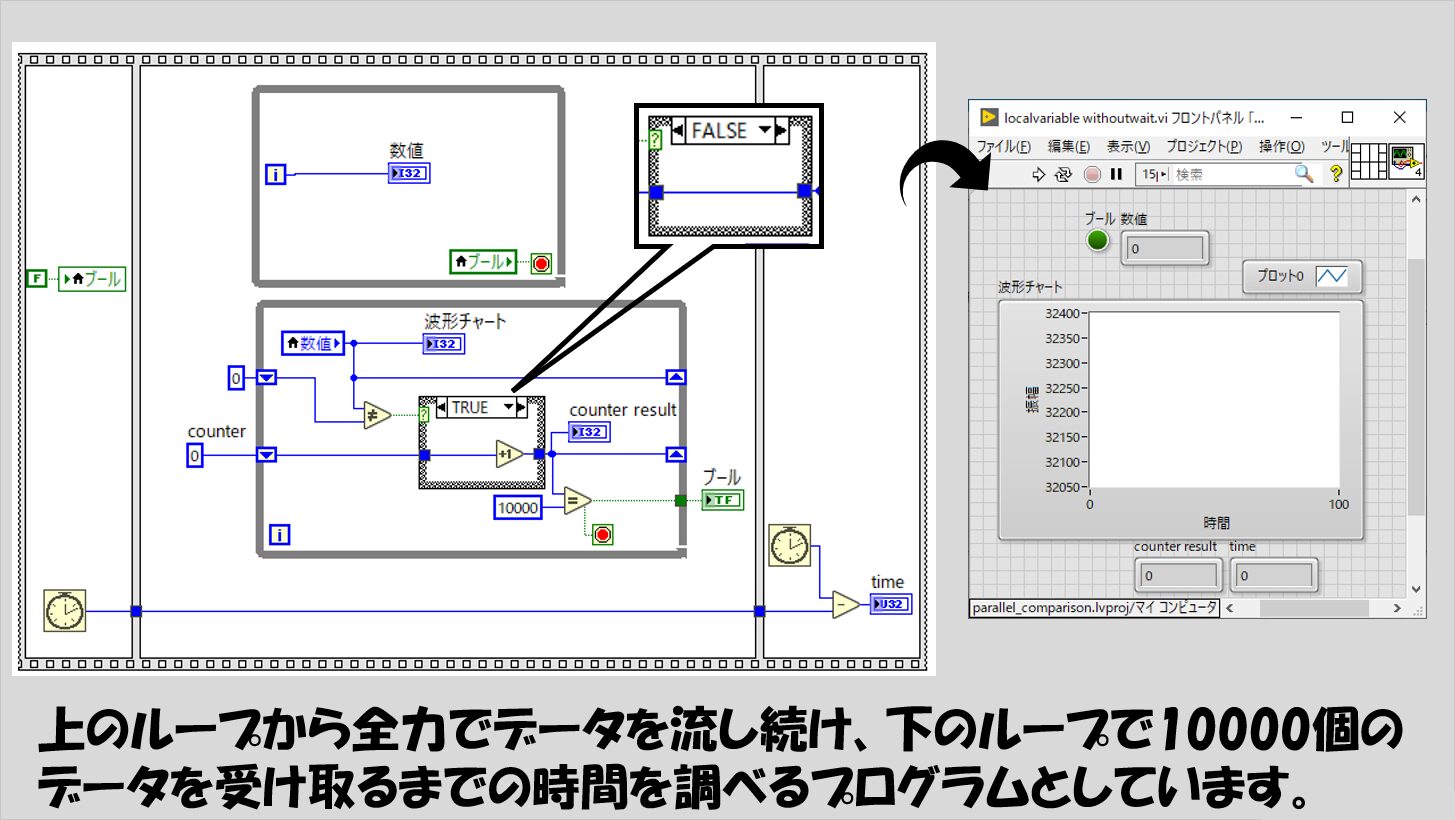
一見二つの方法は同じことやっているように思うかもしれませんが、データを渡す際にどういった点を気にしてどの方法を採用するか、ということを選ぶ基準として、「定期的な周期で送る」ことと「どれくらい早く、効率的に送れるか」について参考になるのではないかと思います。
ただし、これらの検証を行った環境がWindows上であること、には注意が必要です。
(1)の場合、そもそも1ミリ秒ごとにデータを渡すようにWhileループのループ速度を1ミリ秒に制限したとして、毎回きっちり1ミリ秒で回っているかについて、Windows環境の場合不安定となります。
より確からしい検証を行うのであれば、リアルタイムOS上で動作するプログラムで確認した方が信頼性は増すものと思います。
それでも、Windows上で動作させるプログラムを作るだけ、という方もいるかなと思うので、今回は「Windows上での実行による不安定さ」も踏まえての結果だと考えてください(ここら辺の検証の方法について詳しい有識者の方、より良い方法があるというご意見ありましたらコメントください)。
実験結果
それでは実験結果を順次紹介していこうと思います。
ローカル変数の場合
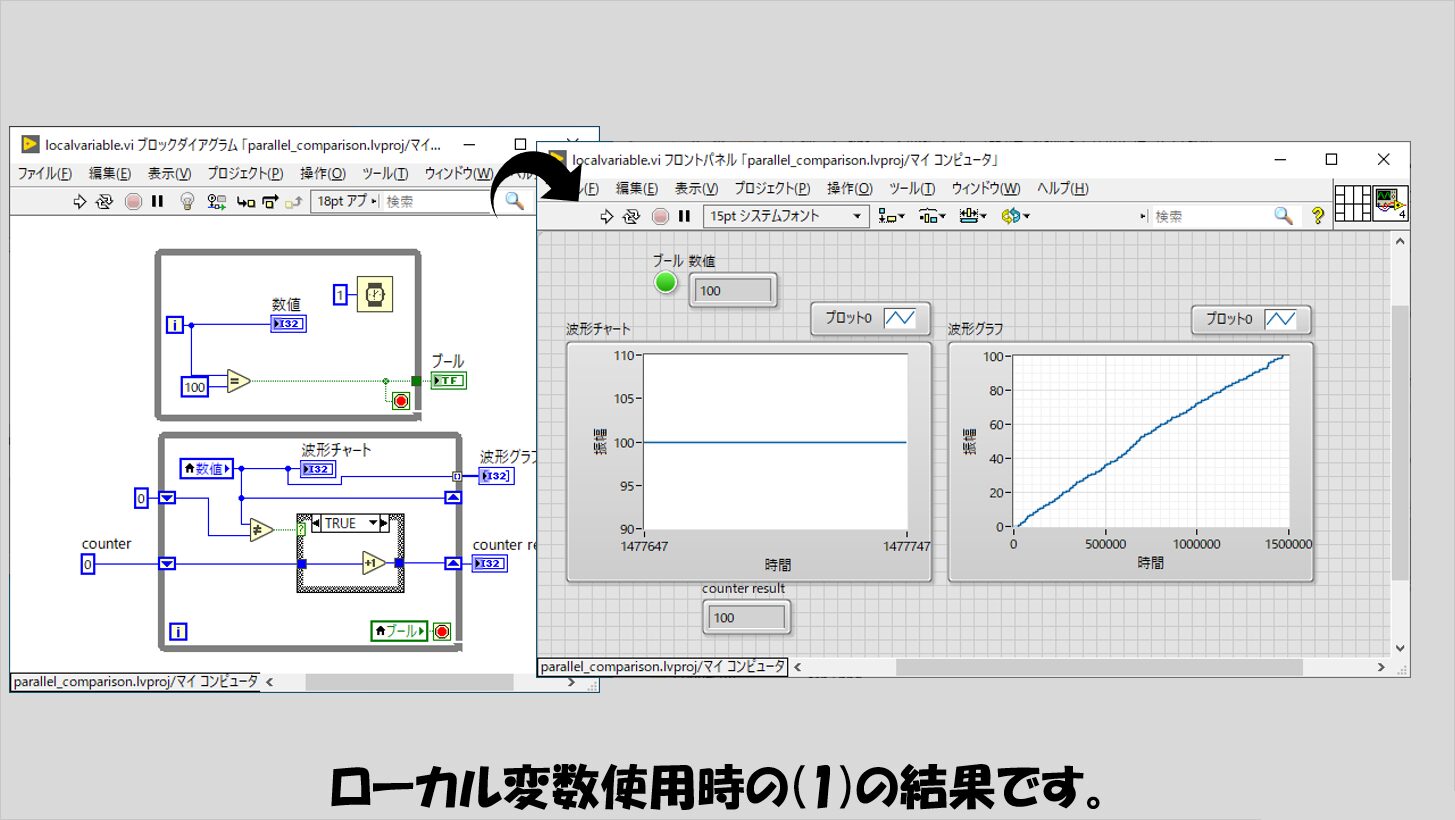
まずはローカル変数を使用した場合の(1)の検証の結果です。
波形グラフは少しギザギザしています。
そして、波形グラフの横軸の値を見ると、1500000程度となっています。
つまり、100個のデータを送っている間に下のループが1500000回程度回ったということになります。
これを、「それだけ無駄に回った」と考えるかあるいは「それだけの高頻度でローカル変数の値の変化をとらえようとしている」と考えるかは、作るプログラムでどのように値の受け渡しをしたいかに依るので、この方法が他の方法と比べて劣っている、とも言い切れません。
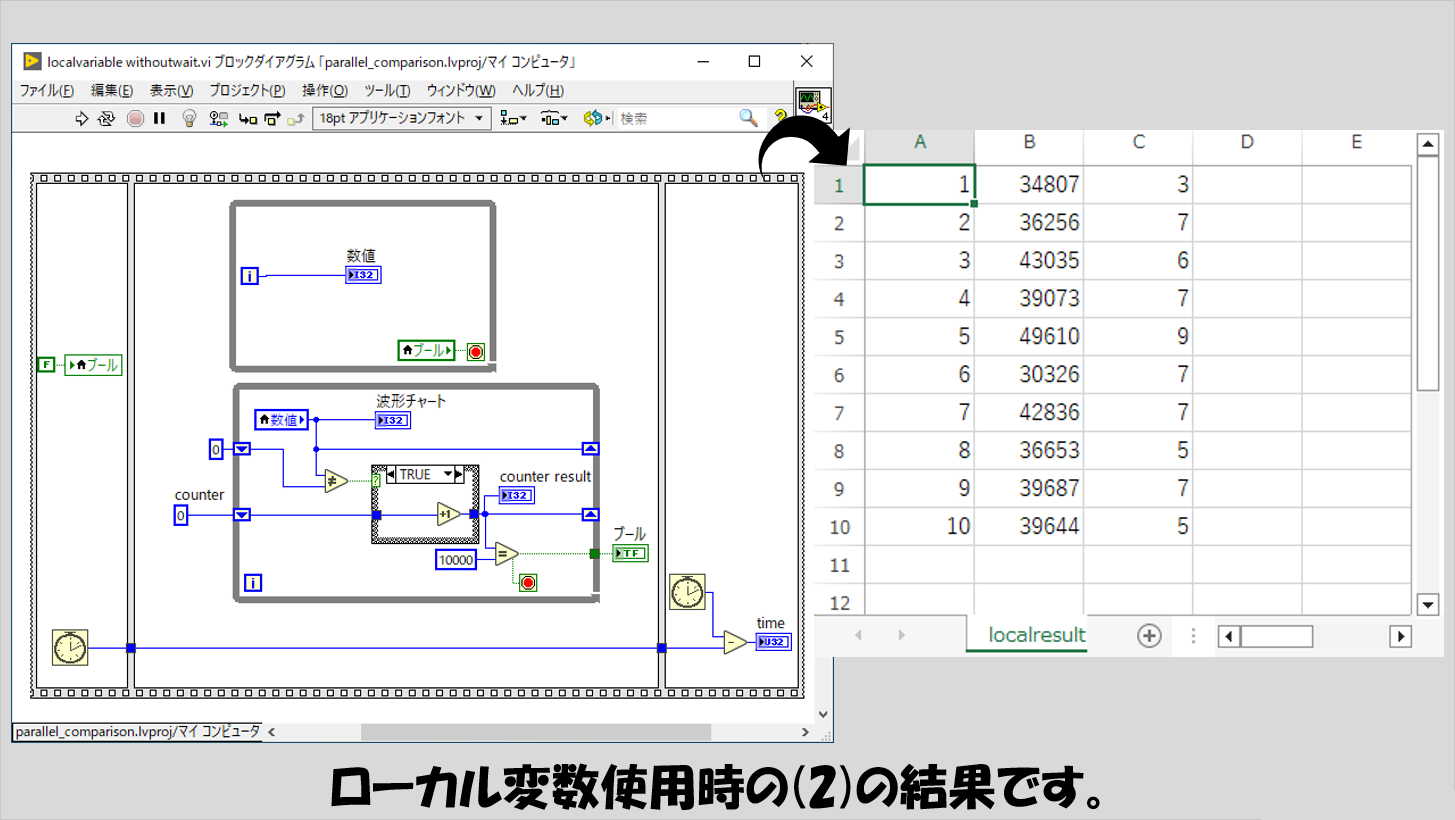
(2)の結果は以下の通りです。
右に載せた結果は、A列が試行回数を、B列が上のWhileループの「数値」がプログラム実行後にどんな値になっていたかを、C列がtimeの値を表しています。
10000個のデータを下のWhileループで受け取るのに10ミリ秒もかかっていない、と言えます。
グローバル変数の場合
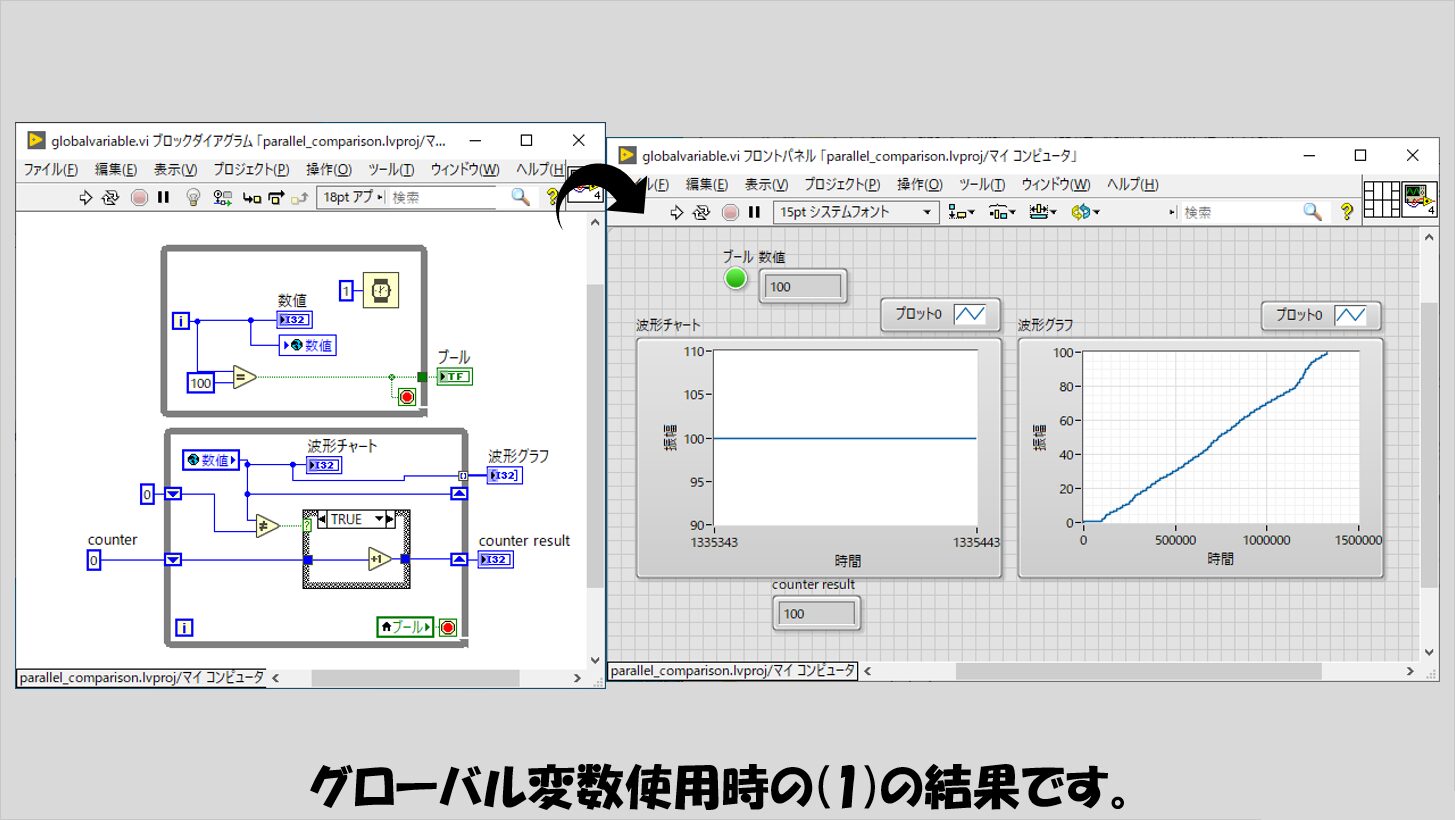
次にグローバル変数について、(1)の結果が以下のものです。
ローカル変数とあまり差はありませんでした。
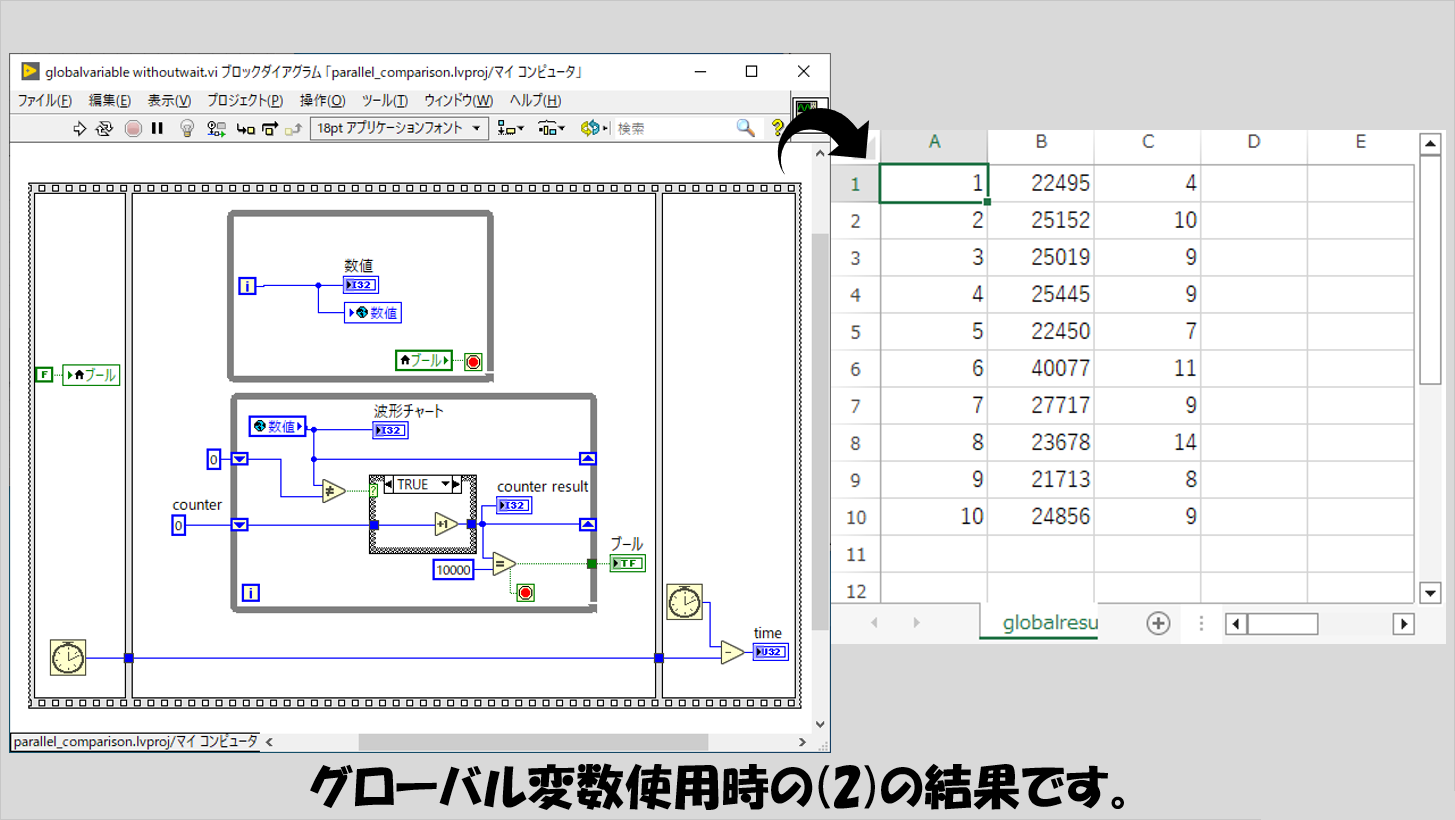
続いて(2)の結果です。
B列の値をローカル変数の場合と比較すると、グローバル変数の方が数字が小さい傾向があります。
つまり、上側のWhileループがそこまで多くの回数回らなくてもプログラムが終了できた、ということなのですが、C列を比較すると、若干ローカル変数の場合と比べて時間がかかっている傾向があるようにも見えます。
とはいっても後述する他の方法と比べるとローカル変数とグローバル変数の違いはそこまで大きくはないです。
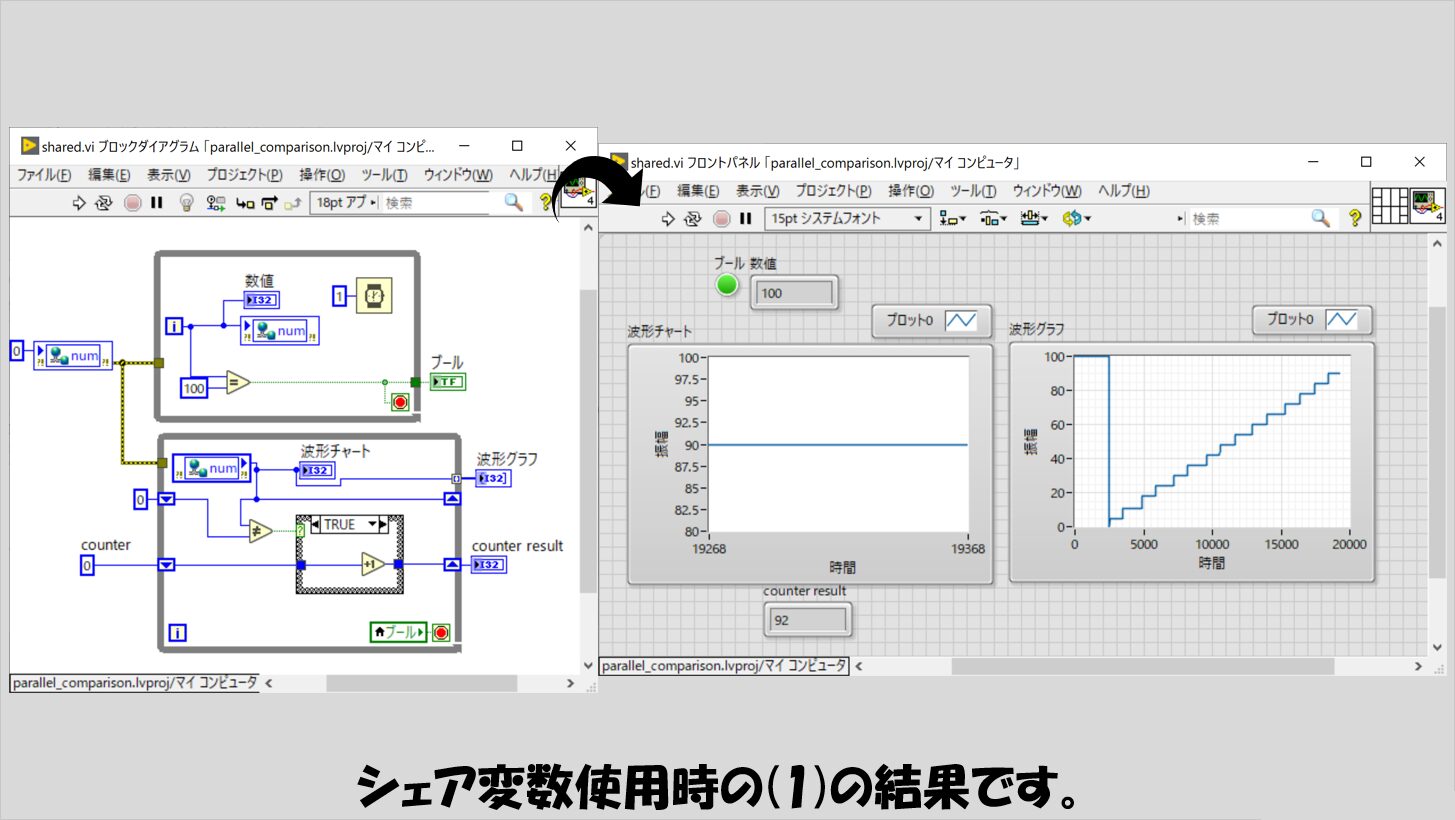
シェア変数の場合
(1)の結果を見ると、だいぶギザギザしています。
ただし、横軸の値を見るとせいぜい20000程度なので、ローカル変数などと比べるとずいぶん無駄に読み取っている下のWhileループの回数が少ないと言えます。
ただし、綺麗な直線になっておらず飛び飛びの値しかとれていないということは、シェア変数自体の読み取りに時間がかかっていてかつ読みこぼしているデータがあるということになりそうです。
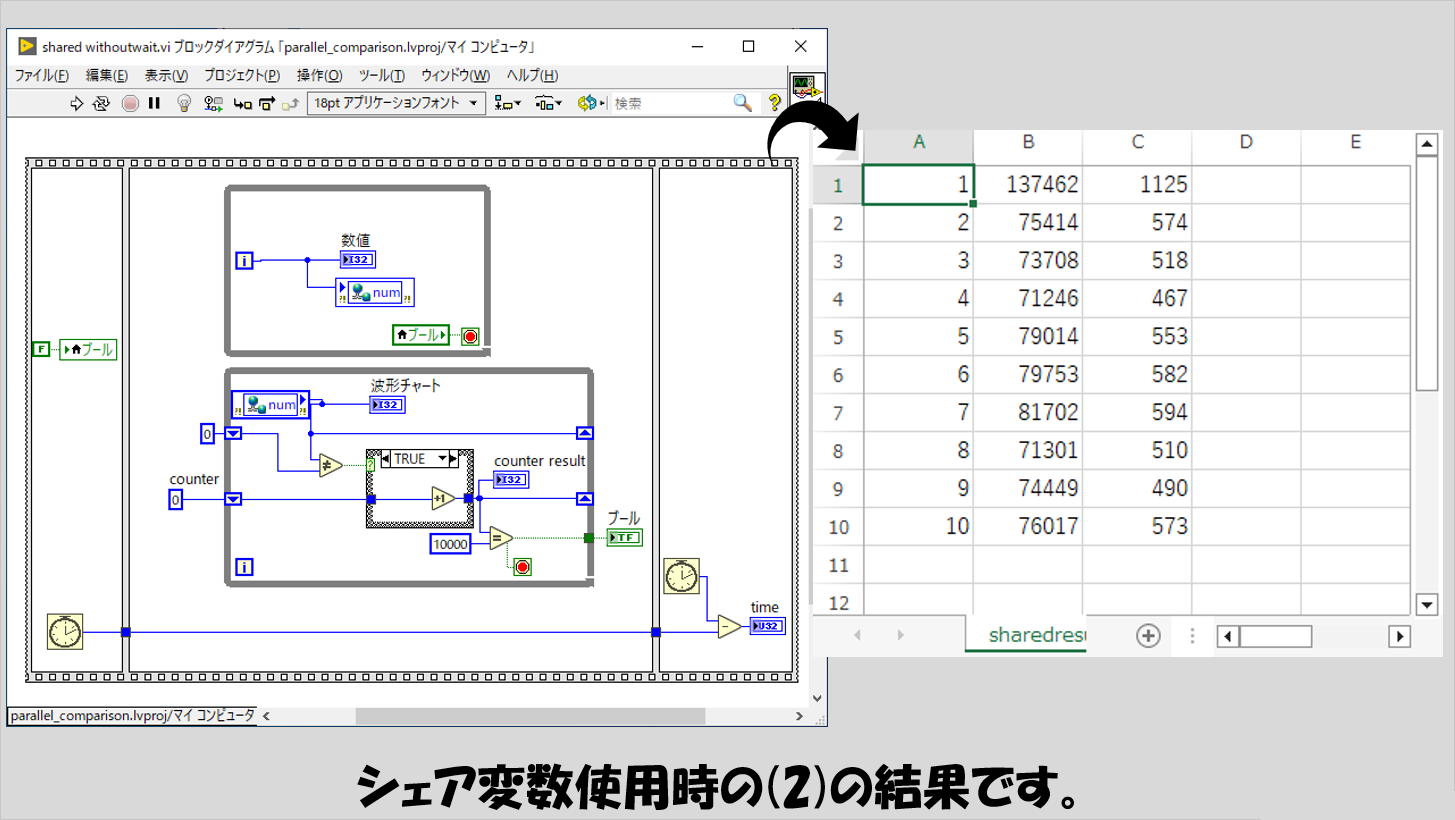
(2)の結果は以下の通りです。
(1)の結果からも推察されるように、ローカル変数やグローバル変数と比べてデータの受け渡しは遅い、と言えそうです。
機能的グローバル変数の場合
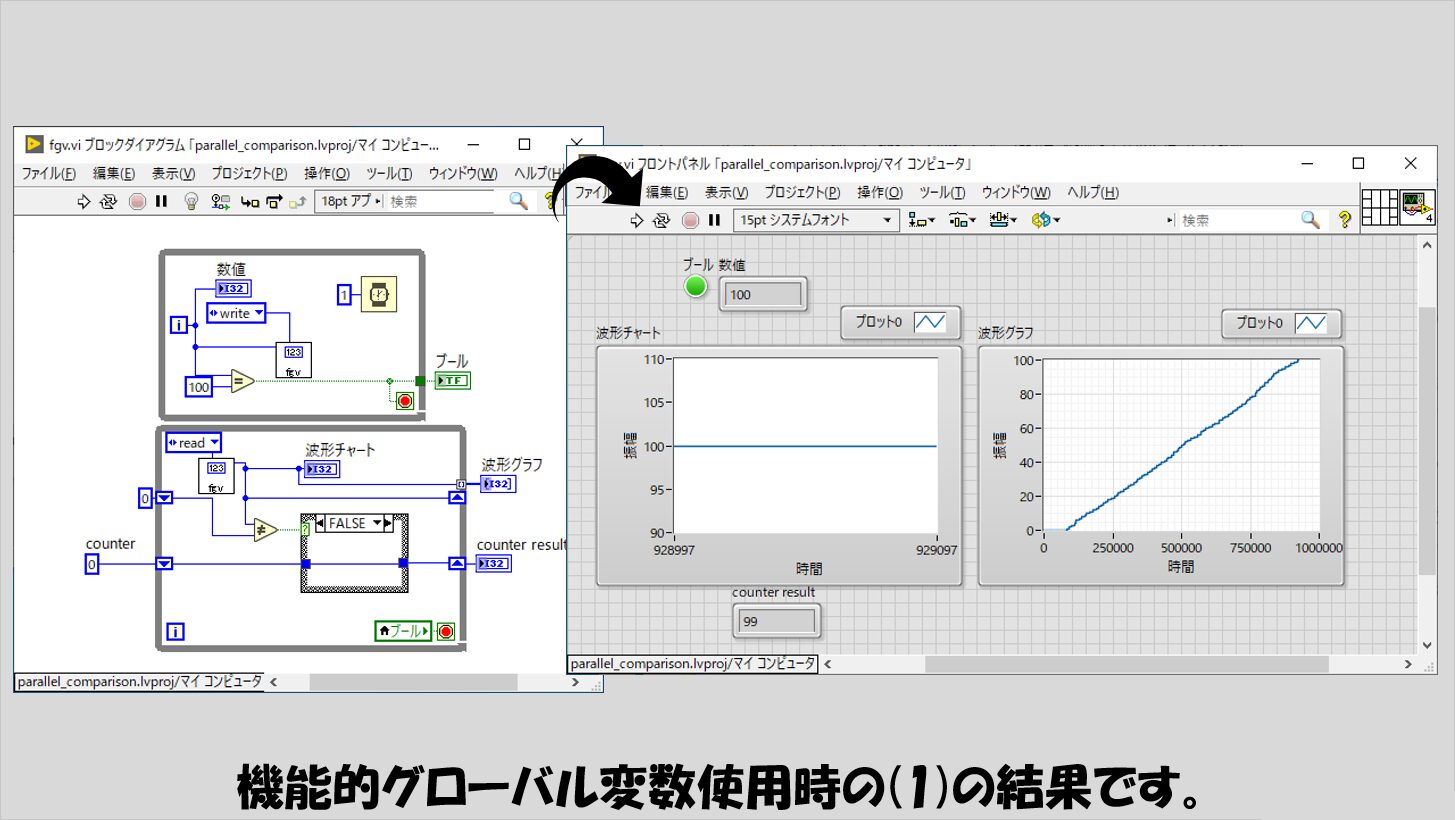
(1)の結果は以下の通りです。
波形グラフの結果はそこまでギザギザしていないように見えます。
横軸の大きさも1000000程度で、シェア変数よりはローカル変数などと近いパフォーマンスと言えそうです。
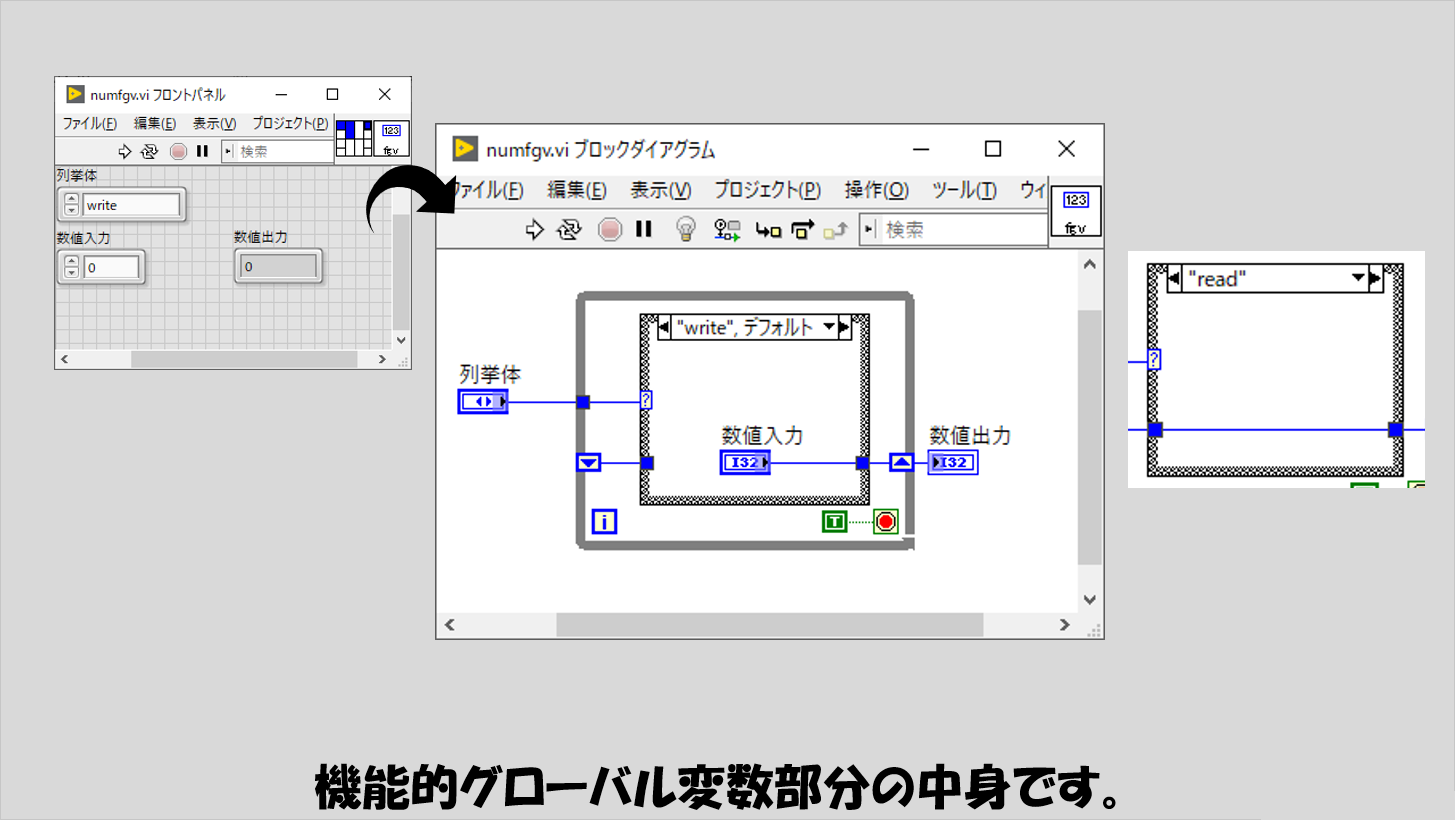
なお、機能的グローバル変数は以下のような単純な構造のサブVIとしています。
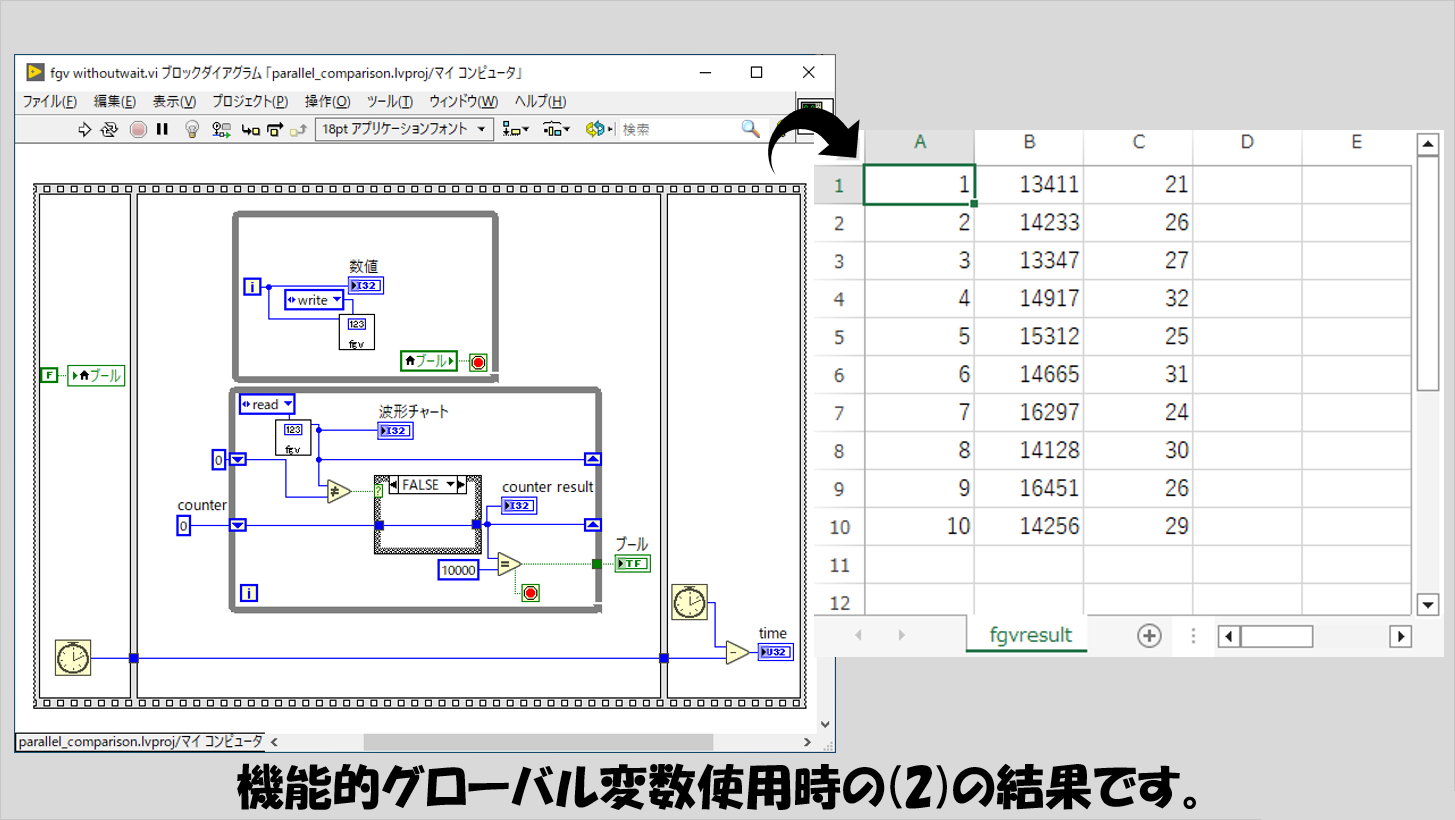
(2)の結果を見ると終了時間はローカル変数やグローバル変数と比べると若干遅い傾向があるようです。
この遅さは、機能的グローバル変数として配置しているサブVIの呼び出しに生じているオーバーヘッドが関係しているのかなと思います。
プロパティノードの場合
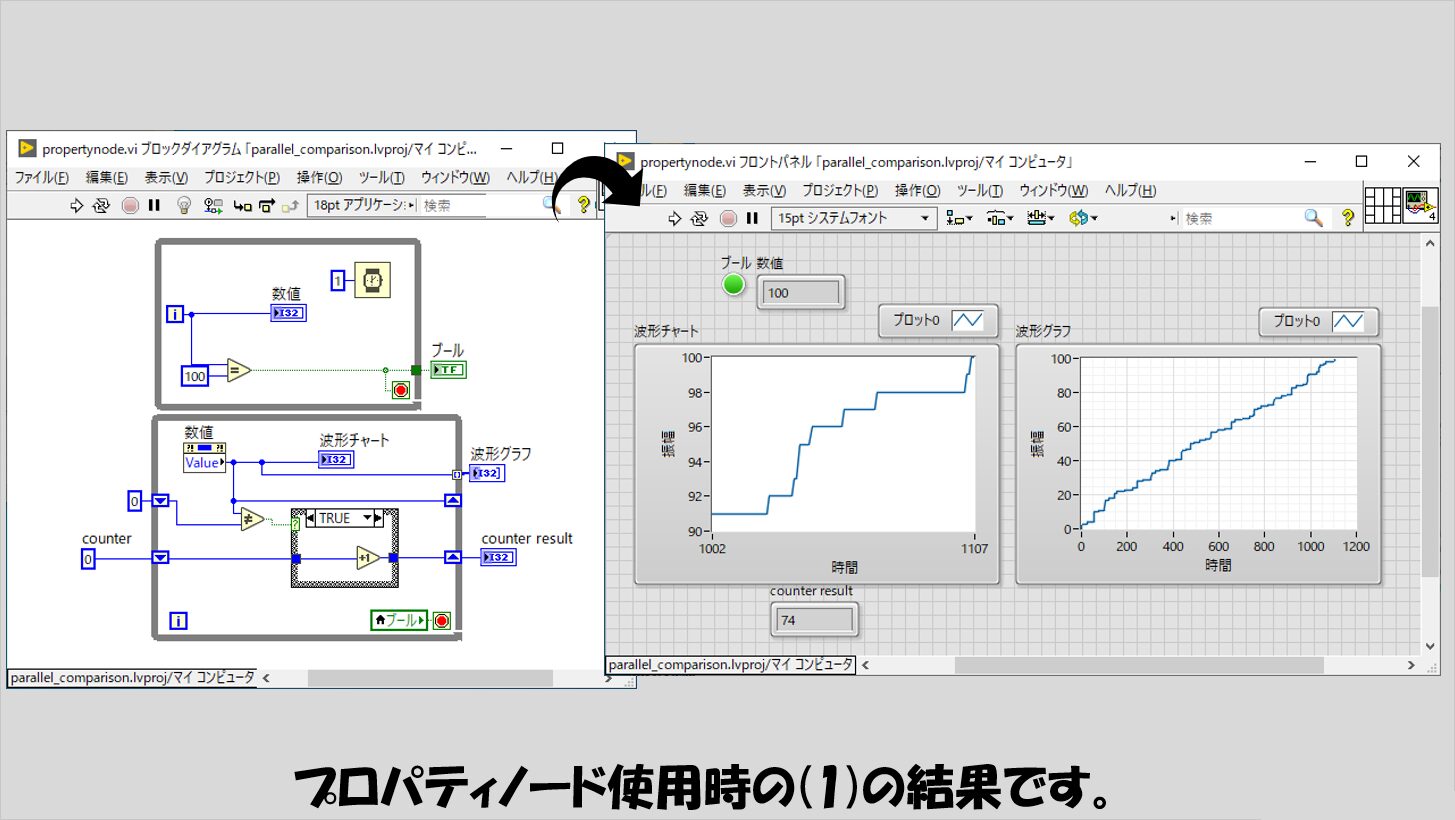
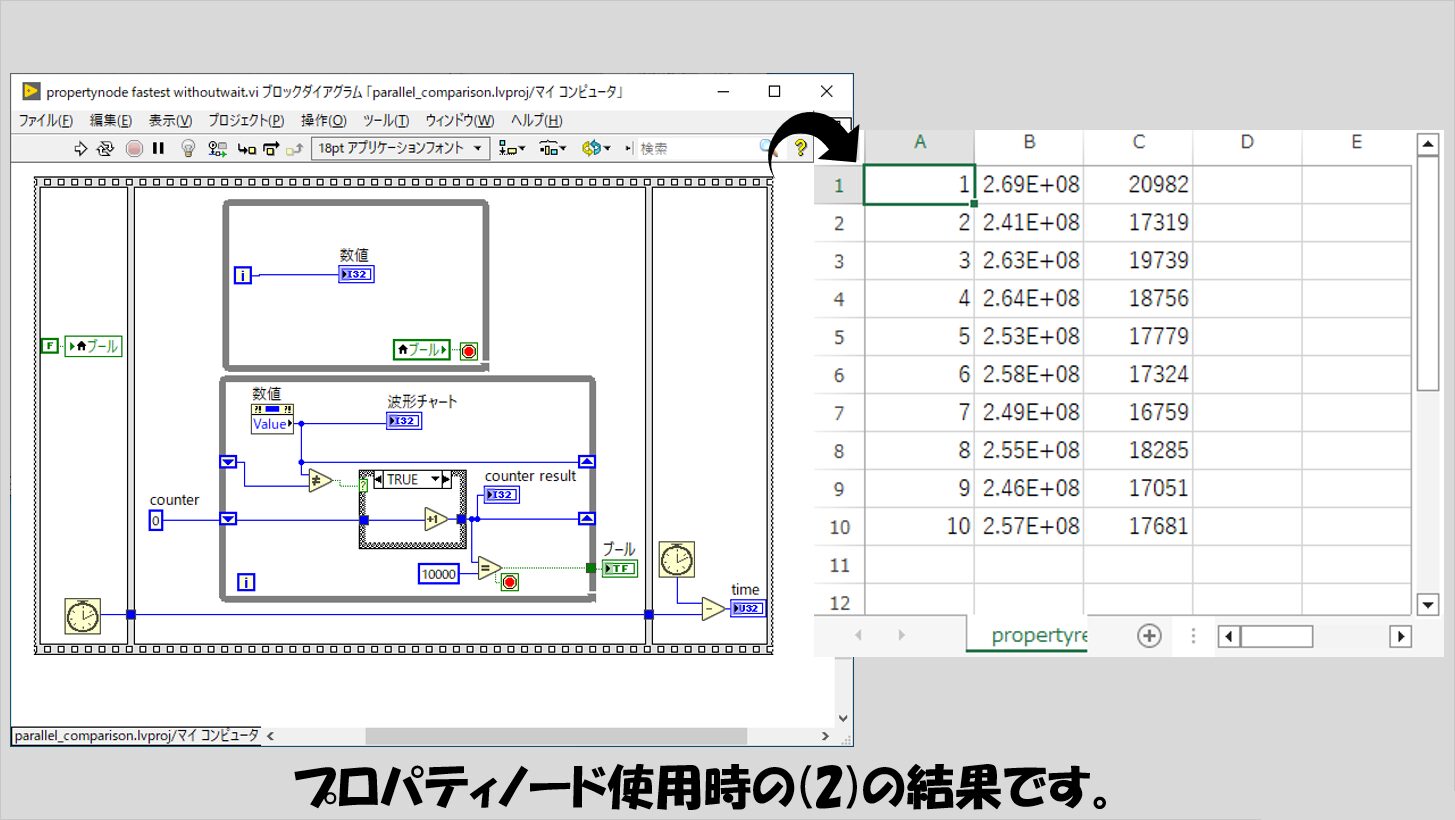
実はこの記事はこのプロパティノードの結果を調べるために書いたのですが、その結果が以下のものです。
これまで、counter resultの値には特に記載していなかったのですが、100に全然及んでいません。
つまり、下のWhileループが他の方法と比べてとても遅いという結果になっています。
これは、(2)の結果を見てもわかり、B列の値が他の方法と比べて圧倒的に大きくなっています。
B列は上側のWhileループのプログラム終了時点での数値の値であることから、下のループでプロパティノードからこの数値の値を読み取るのにとても時間を要していることがわかります。
これを見ると、データの受け渡しにプロパティノードを使用するのはパフォーマンス上最も効率が悪いと言えます。
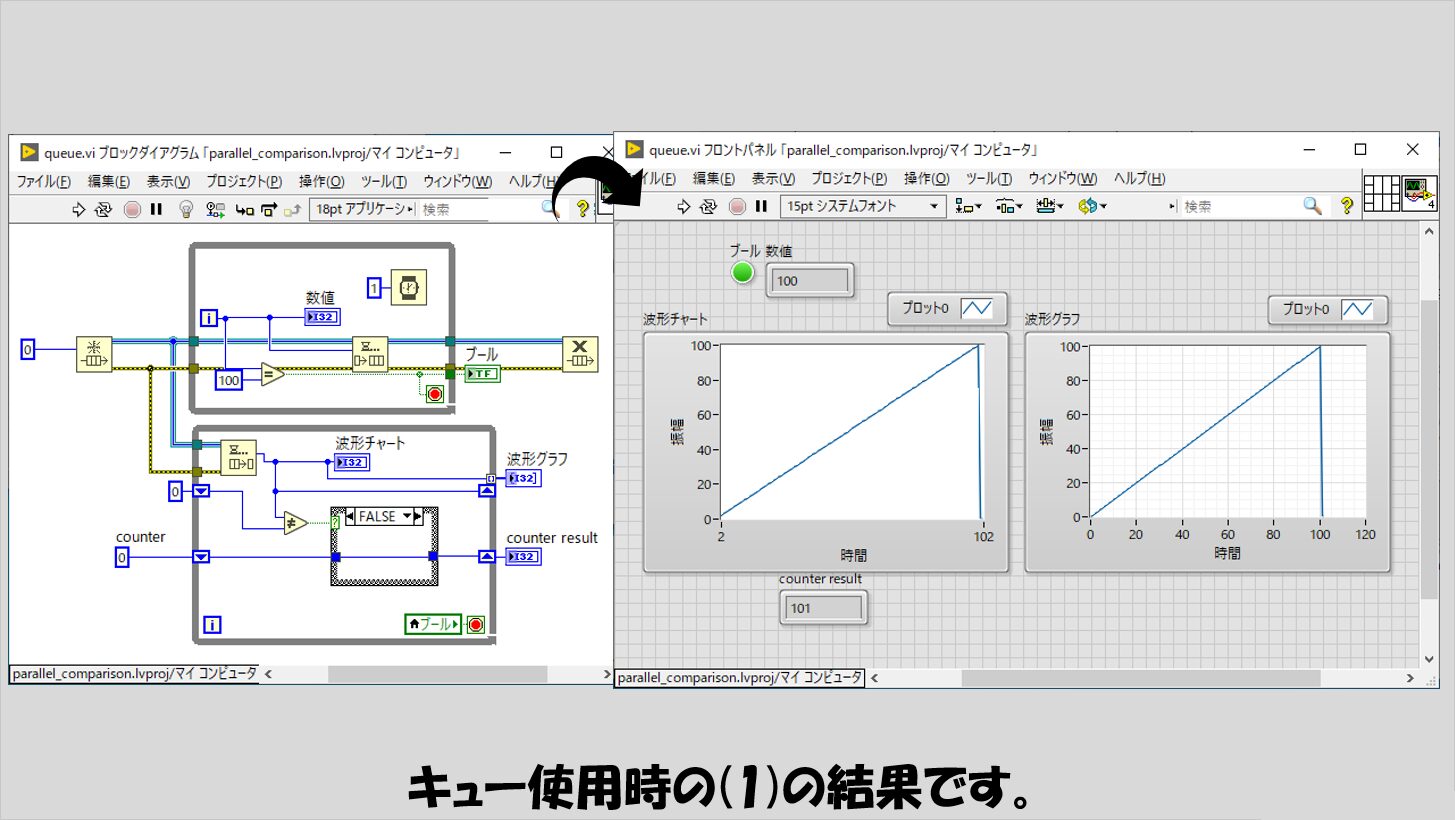
キューの場合
ループ間でデータを渡す際の方法の代表格がキューですが、(1)について波形グラフを見ると横軸の値がほぼ100で終わっていることがわかります。
キューの性質上当たり前と言えば当たり前なのですが(波形グラフの最後がドンと下がって0になっているのは、下のループが終わる最後の回でデキュー関数から得られる値がデフォルト値の0になっているからですね)。
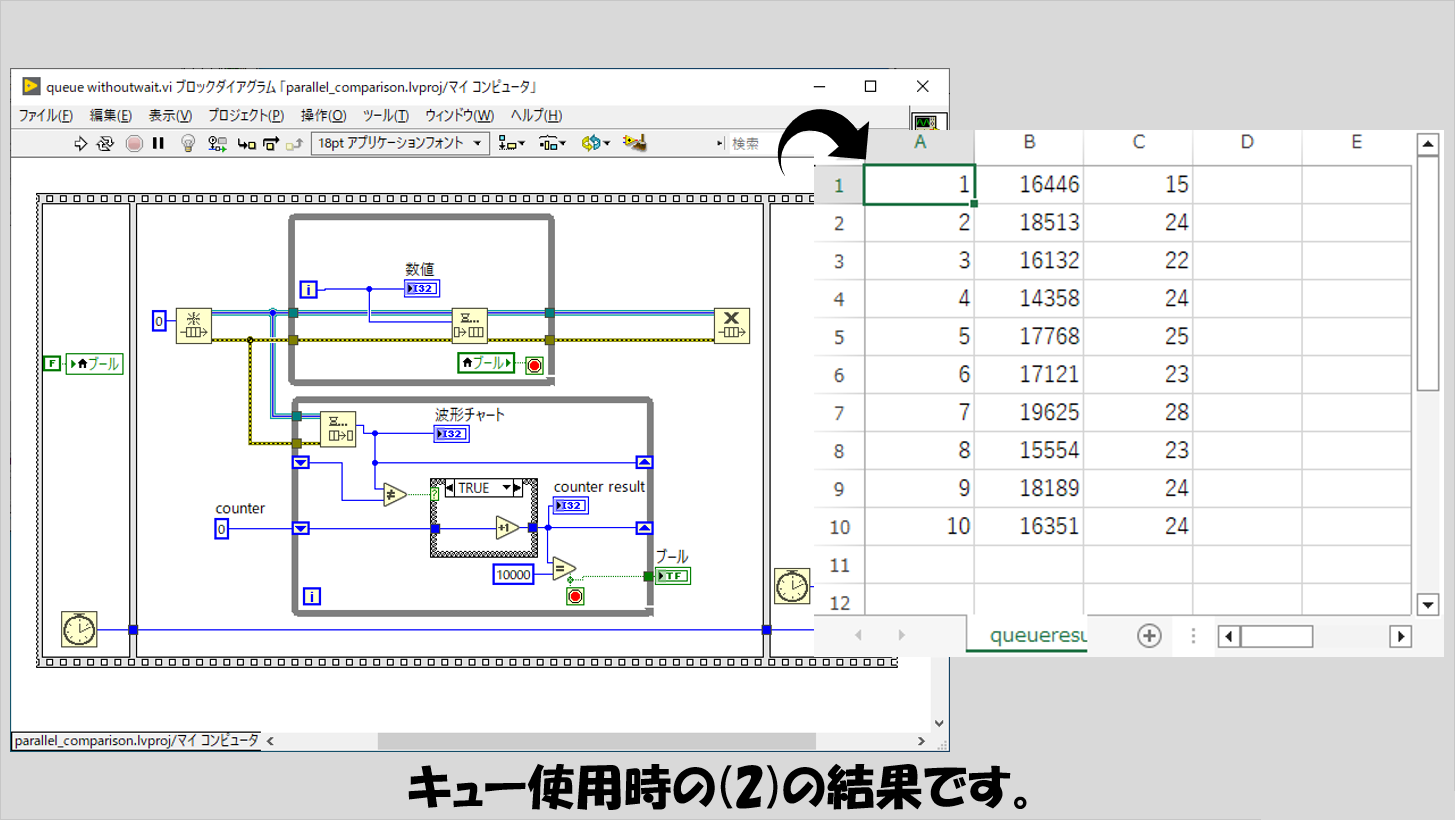
(2)を見ても、特に可もなく不可もなくといった結果です。
ただ、C列を考えると、ローカル変数よりも時間がかかっていることがわかります。
つまり、諸々の効率を考えるのであればキューは優秀と言えるのですが、とにかく早くデータを読み取って処理する(無駄にループが回ってもいいから)ことを優先するのであれば、ローカル変数も捨てたもんじゃない、ということですね。
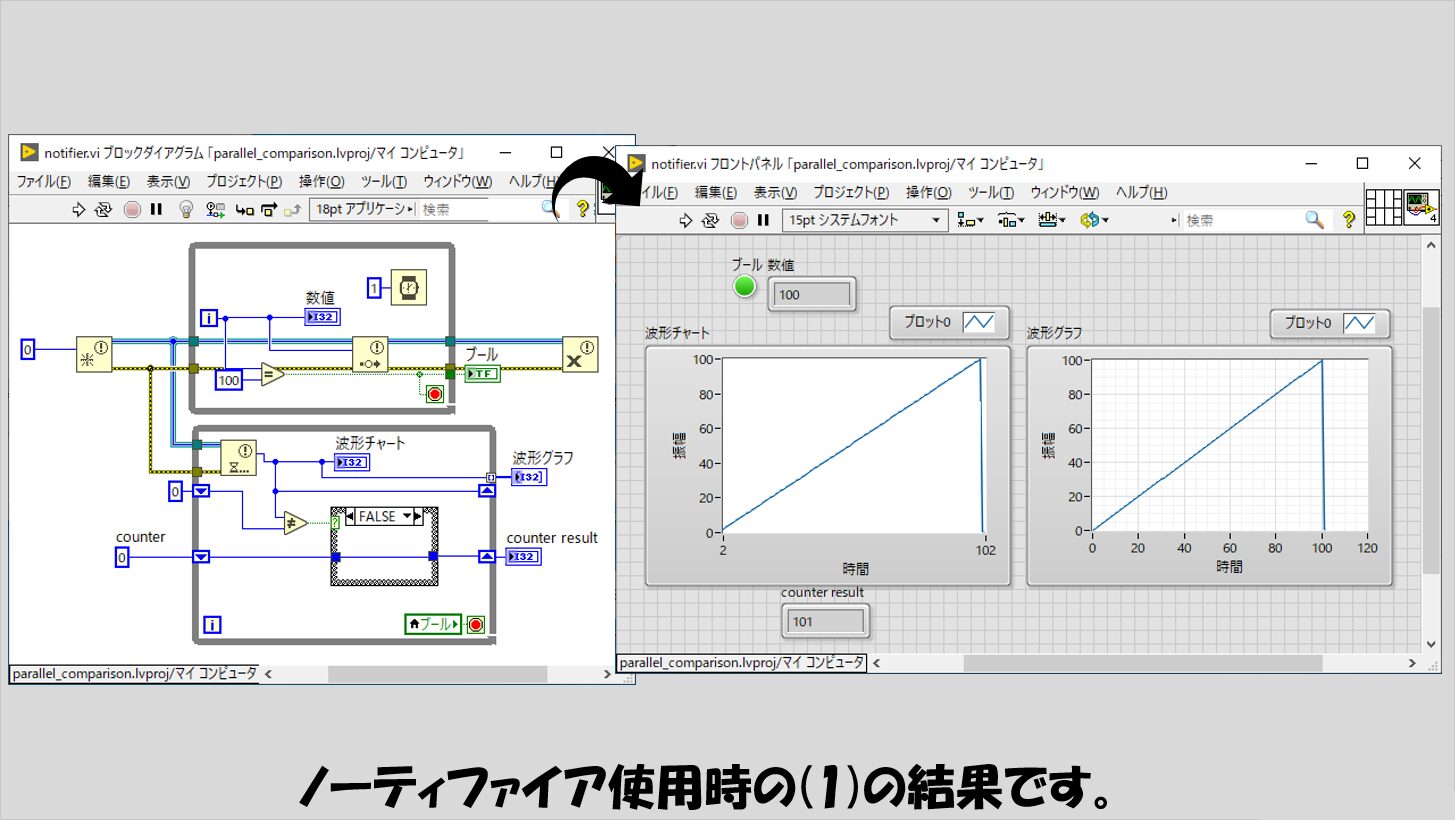
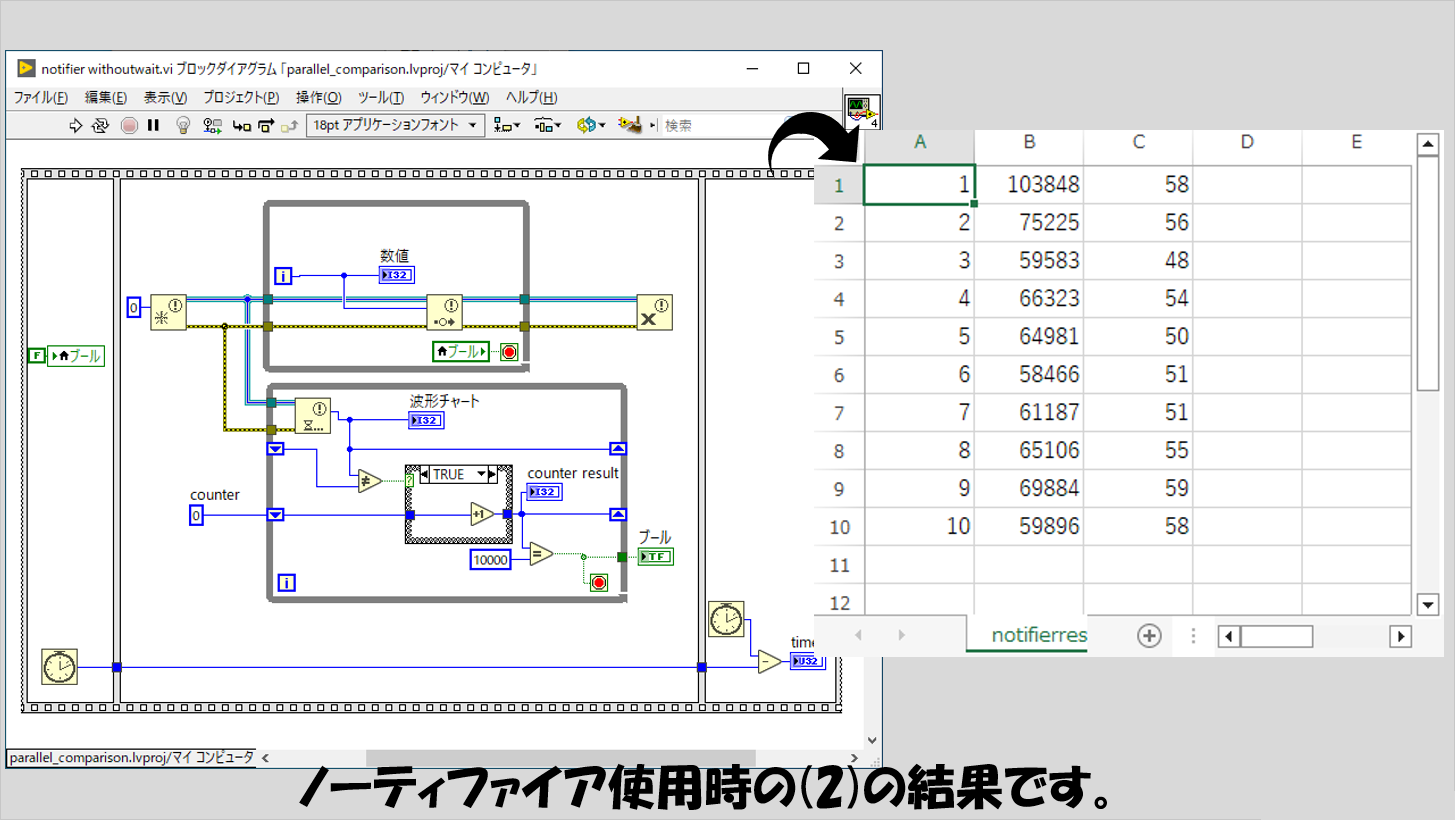
ノーティファイアの場合
(1)についてはあまり特筆することはなく、キューと同様な結果になっています。
(2)については、キューと比べるとB列の数字も全体的に大きく、C列を見ると全体的に時間がかかっていることがわかります。
複数のループに同時に最新値を送ることができる点でキューとは明確に使い方が分かれていますが、早さについてはキューの方が有利だ、と言えそうです。
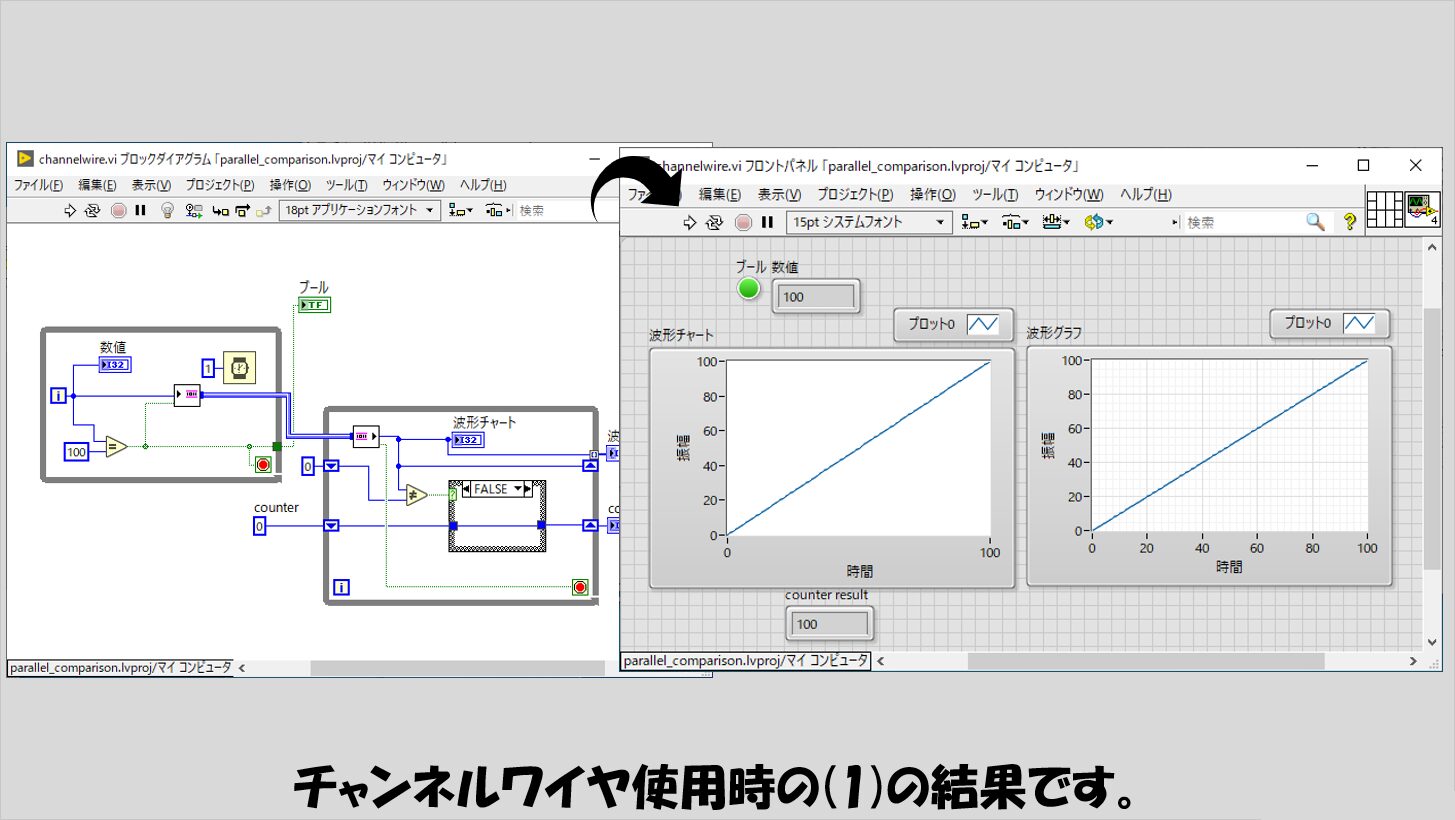
チャンネルワイヤの場合
キューに取って代わることを目指しているであろう、チャンネルワイヤについても実験しています。
(1)の結果は以下の通りで、キューと同じですね。
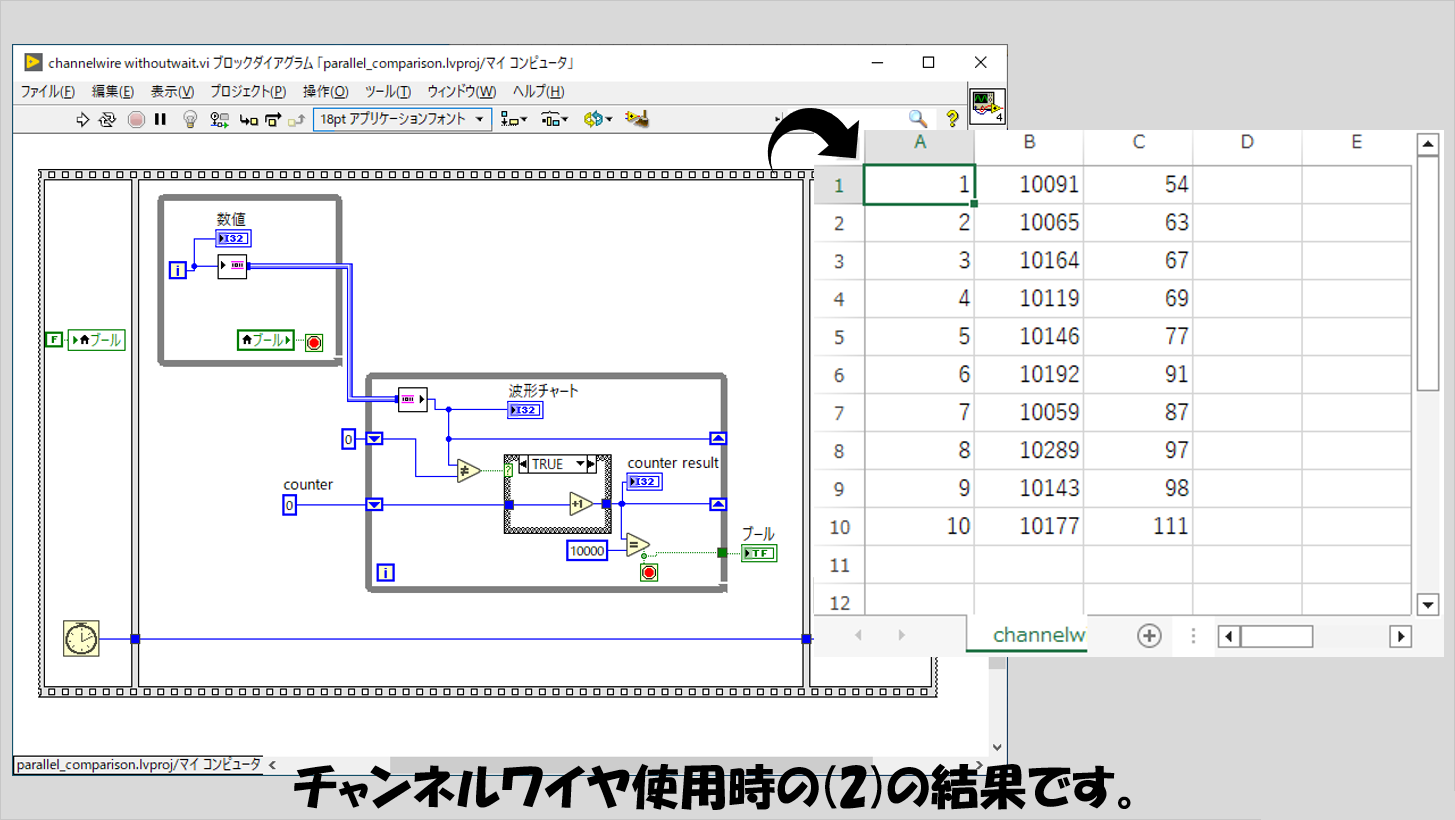
ただし(2)の結果を見ると、C列を比べてみても、キューよりは時間がかかっているということが言えそうです。
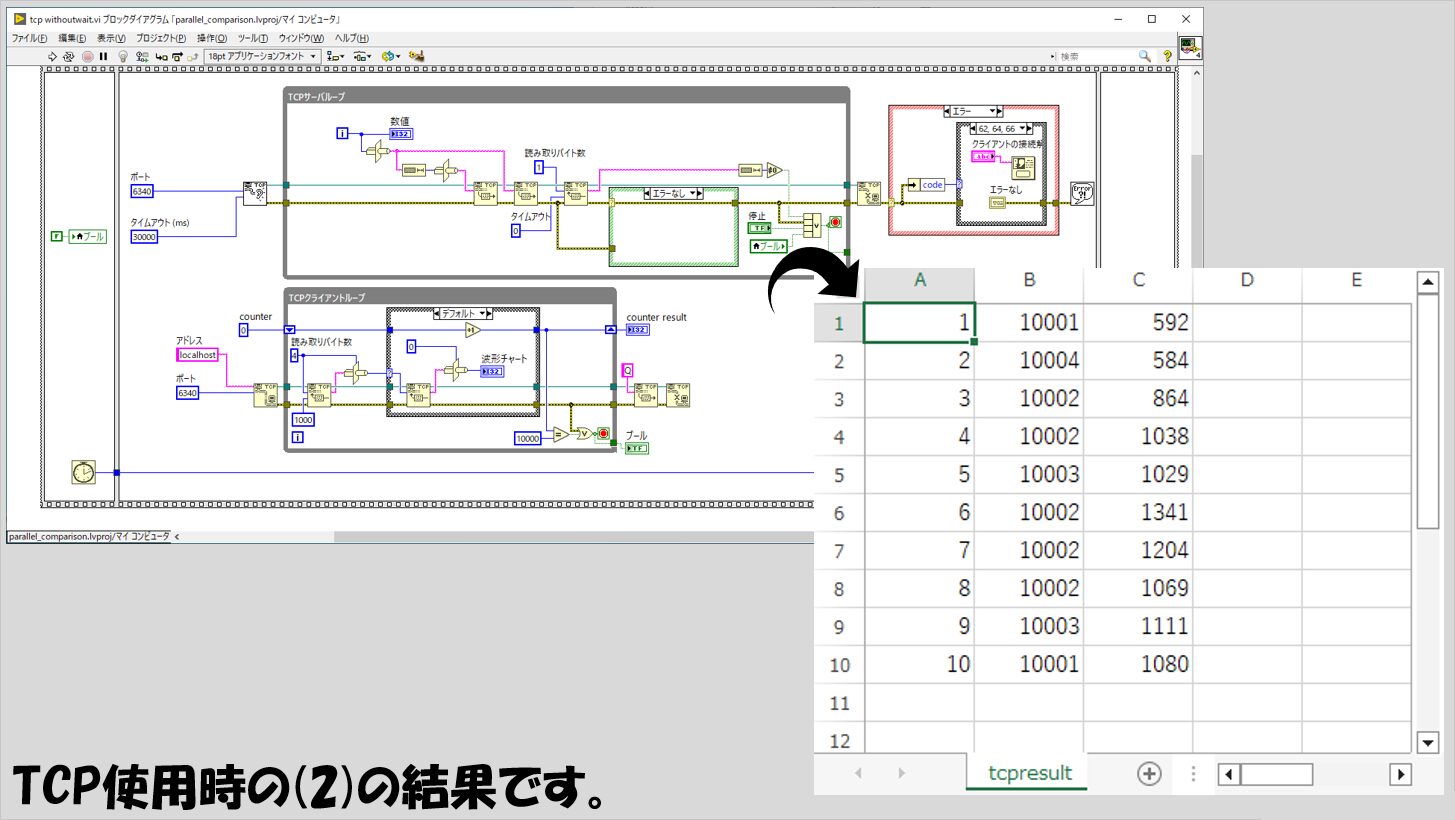
TCPの場合
最後がTCPの結果ですが、(1)についてはこれまた特筆することは特にありません。
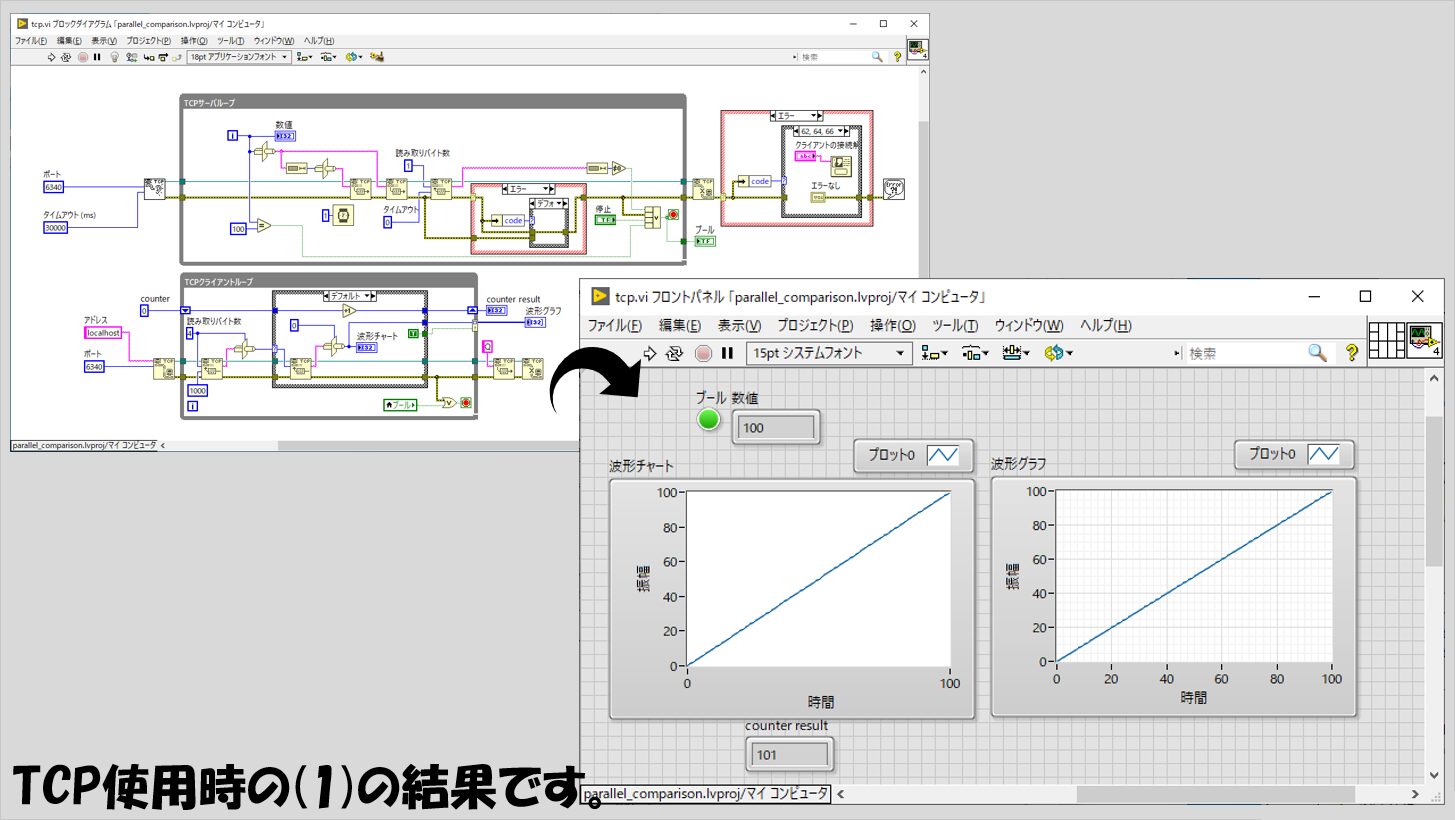
(2)について、プログラムの書き方のせいもあるとは思いますが、B列のばらつきが他の方法と比べて少なく、C列についてはプロパティノードに次いで時間がかかっていると言えます。
結果のまとめ
では、それぞれの結果をまとめてみます。
(2)の検証の、B 列とC列の結果をひとつの表に示しています。
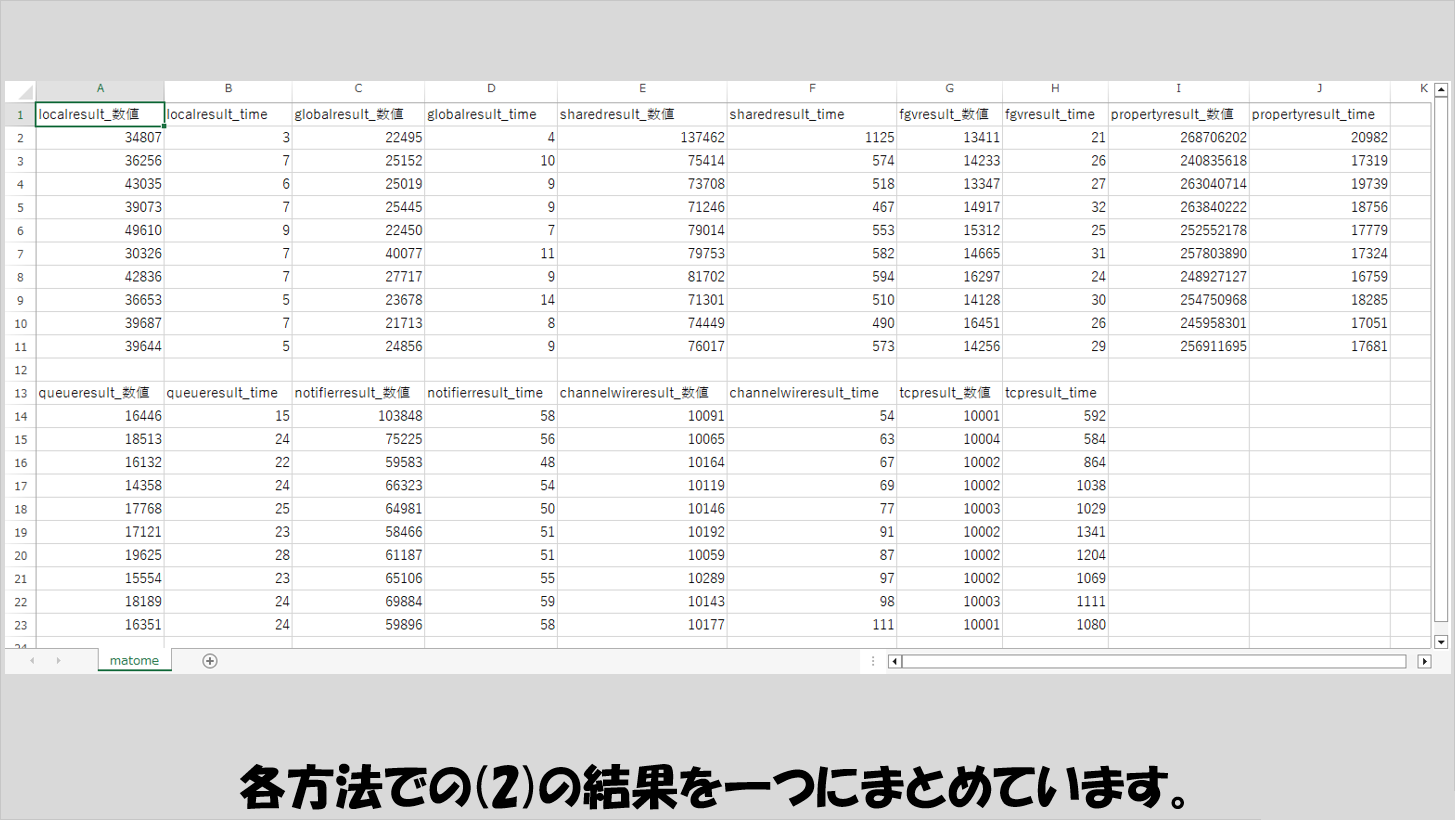
ここから傾向として言えそうなのは以下のようなことになりそうです。
まずは、プロパティノードで値プロパティを使用してデータを読み取るという方法は基本的に最悪手になるということです。
また、ローカル変数は無駄もあるもののデータの受け渡しを行わせる速度としては他の方法よりも有利になっているということも言えそうです。
・・・結構色々な方法で調べたとはいえ、傾向として確からしいことが言えるのはこれくらいでしょうかね。
実用上、並列ループ間でデータを受け渡す際の同期通信については、どんな場合でもキューを使用していれば、パフォーマンス上困ることはそこまでないと思います。
とはいえ、何らかの事情でキューを使用するのが難しい(あるいは実装が大変になる、非同期通信が適している、等)場合、他の選択肢をとるにしても、プロパティノードを使用するのは基本的に避けるべきだということを覚えておくのがいいと思います。
本記事では、ループ間でデータを渡すためのいくつかの方法のパフォーマンスを比較した結果を紹介してきました。
方法によって処理速度や効率が大きく変わるため、より適切な方法を選ぶことが大切だということを頭の片隅に入れて、プログラムの設計に役立ててもらえればうれしいです。
ここまで読んでいただきありがとうございました。
コメント