LabVIEWを触ったことがない方に向けて、それなりのプログラムが書けるようになるところまで基本的な事柄を解説していこうという試みです。
シリーズ23回目としてLabVIEWの並列処理を活かすのに必要なキュー関数を扱います。
この記事は、以下のような方に向けて書いています。
- ローカル変数など以外でデータの受け渡しはどうするの?
- キュー関数の仕組みが分からない!
- キューの利点と注意点を知りたい
もし上記のことに興味があるよ、という方には参考にして頂けるかもしれません。
なお、前回の記事はこちらです。
変数ではない方法で値を共有する
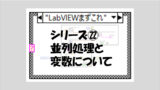
前回、二つの変数を紹介していました。それぞれの役割としては
- ローカル変数:同じVI内で値を共有する
- グローバル変数:異なるVI同士で値を共有する
さらにまだ紹介していませんが変数と名前が付くのは他にもあり、
- シェア変数:異なるPC間で値を共有する
- 機能的グローバル変数:グローバル変数に「機能」を持たせる
といったものが挙げられます。まだ扱っていないこれらの変数はローカル変数やグローバル変数とは異なり使用頻度は多いと思います。(そのうち取り上げると思います)
さて、値を共有する方法としてローカル変数やグローバル変数がありこれらを紹介した一方で、多用しない方がいいという話を前回していました。では、これらを使わずに例えばループ間で値を共有するにはどうすればいいかという話になってきます。
そのための、非常に強力なプログラムの要素として「キュー」や「ノーティファイア」といったものがあります。これらを覚えることで、LabVIEWで書けるプログラムの幅がさらに広がっていきます。
今回はキュー、次回はノーティファイアについて取り上げていきます。
キューとは
キューは英語でqueueと書いて「並ぶ」という意味があります。その名の通り、キューはデータを並ばせておくような動作をします。
それとループ間での値の共有とどう関係があるのかイメージを持ってもらおうと思います。キューというものをLabVIEWで扱うとは、下の図のようなチューブを用意するものだと思ってください。
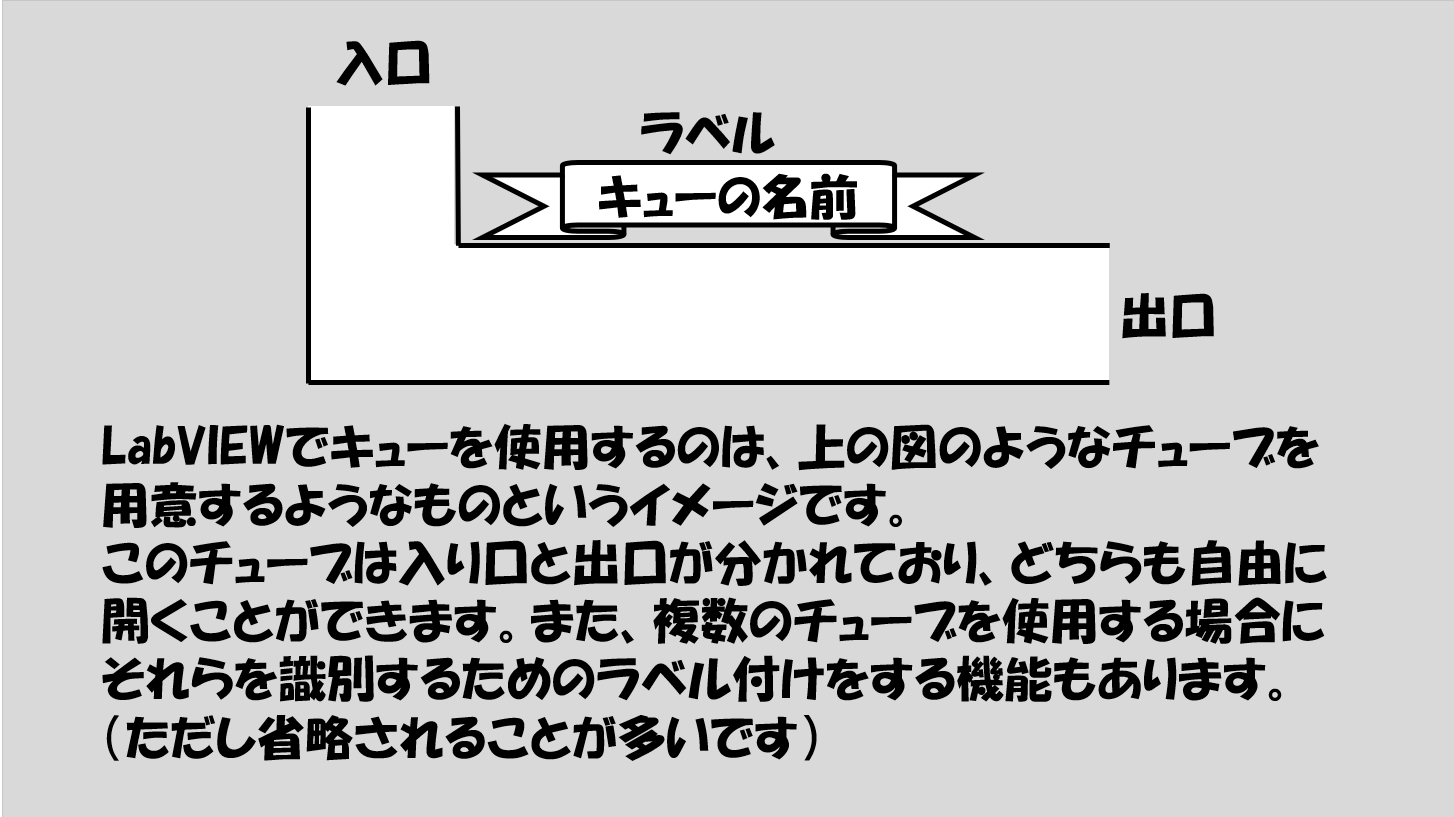
チューブには入り口と出口があります。また、ラベルを付けて複数のキューがある中で明示的に特定のキューを指定することができるのですが、プログラムの組み方によっては省略できます。
さて、もう勘のいい方はわかったかもしれませんが、複数のループで値を共有するとは、このチューブの入り口をあるループから、出口を別のループからそれぞれ制御する状態を指します。
ではこのチューブを扱う利点を見ていきます。
値を共有するといっているくらいなので、このチューブに値を次々といれていきます。ここでいう値というのは何でも構いません。数値でも文字列でも、数値の配列やクラスタなども扱えます。大雑把に、定数を作れるデータタイプであれば何でも、と思ってください。(一方でダイナミックデータは定数を作れないのでキューで扱えません)
まず最初に、Aという値を入れたとします(値と呼んでいると曖昧なので説明の都合上文字列を例にとります)。そして次に、Bという値を入れました。イメージとしては以下の図のような状態です。
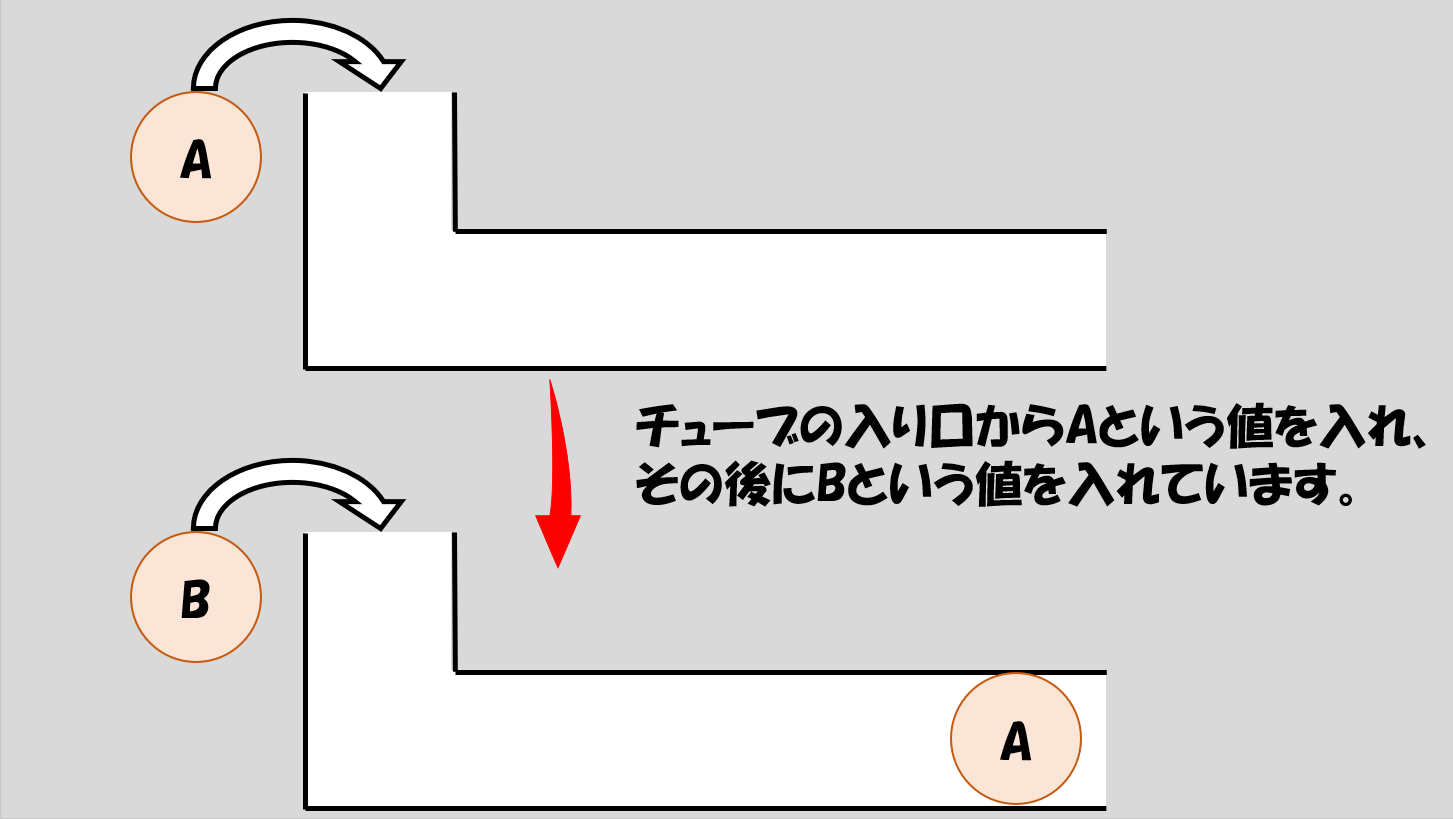
この時点でチューブには二つの値が入っていますが、順番が決まっているのがわかるでしょうか?入れるところが上からなので、この場合、確実に「Aが最初、Bが次」という順番が決まっていることが分かると思います。
もう一つ、Cという値を入れてみます。その後、チューブの先をカパッとひらいて、Aを取り出します、するとこのような状態になるはずです。
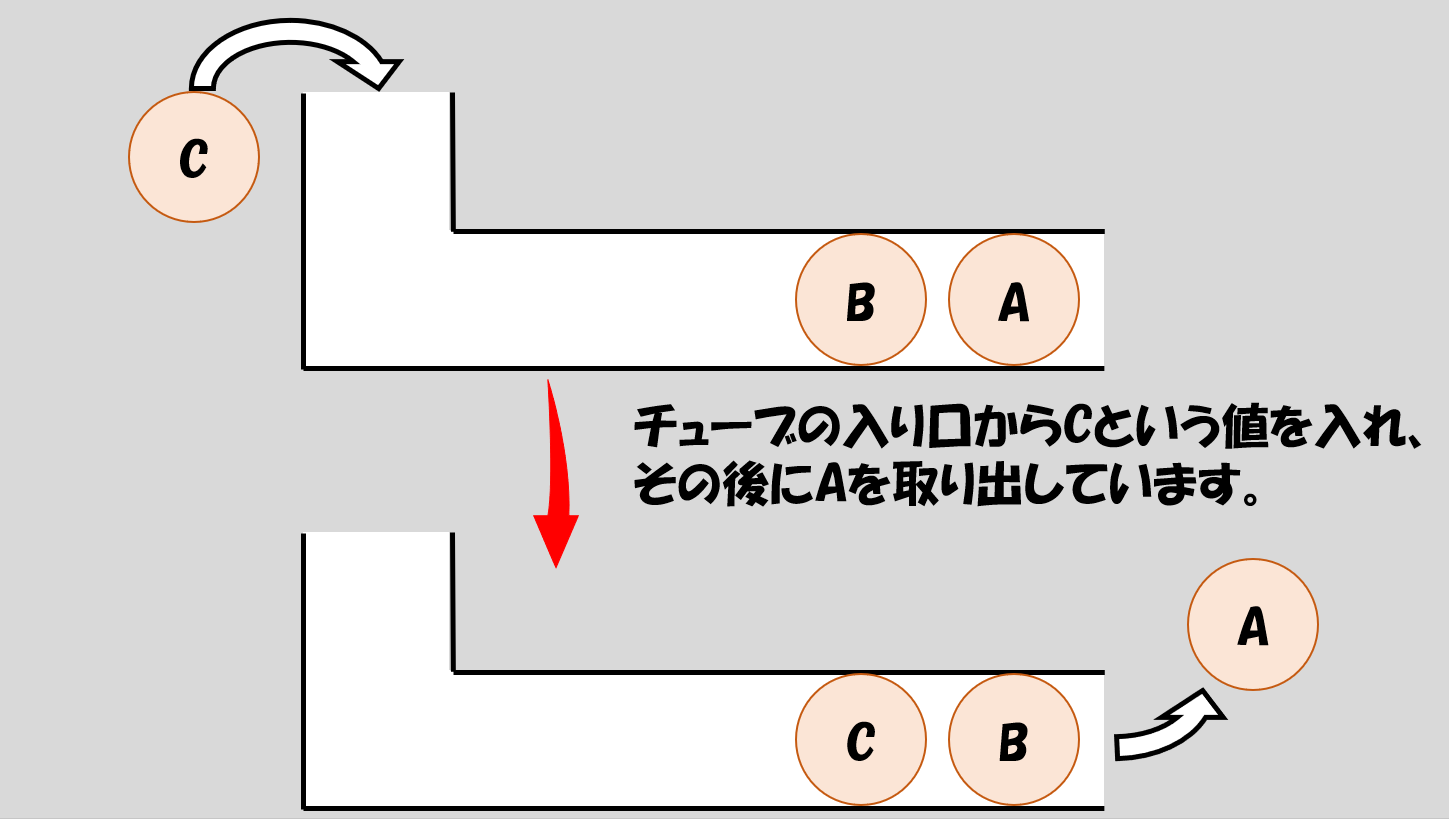
大切なことは、Aより前にBが取り出されることはない、ということです。図を見たら明らかですよね。
実は以上でキューの仕組みの概念の説明は終わりです。特に難しいことはなかったと思いますがいかがでしょうか?これをそのままLabVIEWプログラムに落とし込みます。
今の説明の動作を実現するには、3つの動作が必要です。つまり、
- キューを用意する
- キューに値を入れる
- キューから値を出す
なんだかファイルIOの操作と似ていると思った方、その通り、ファイルを用意して読み書きして、という動作に似ています。ファイルIOではファイルを閉じるという操作がありましたが、キューについても似たような操作があり
- キューを解放する
と呼ばれます。これら4つがキューの基本的な使い方になります。
LabVIEWでキューを使用する
では実際にとても簡単な例を以下に示しています。これらは、関数パレットでファイルIOの下、同期というパレットの中のキュー関数というパレットに全て含まれています。
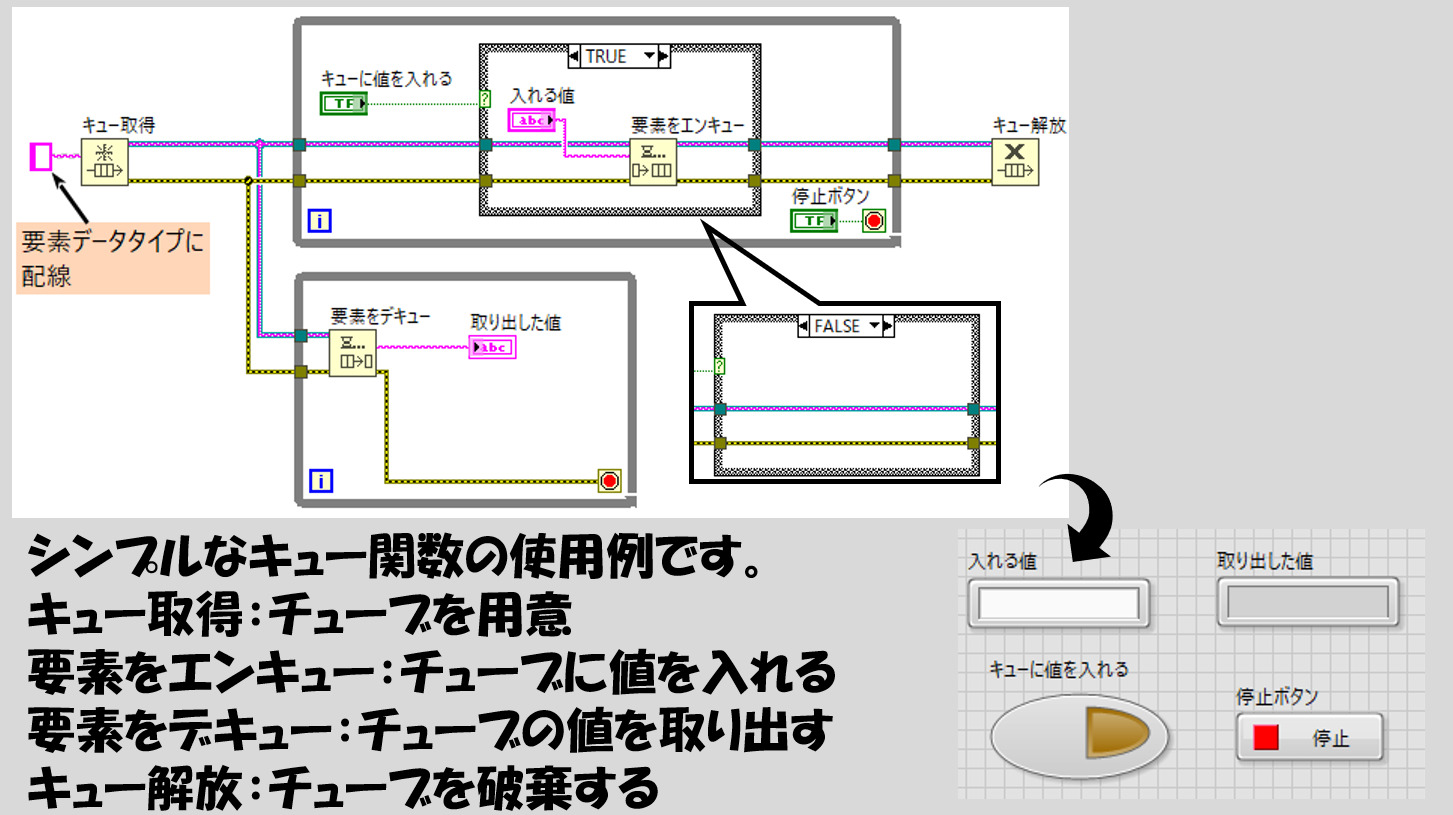
最初に、キュー取得という関数があります。先ほどの例でいうところの、「チューブを用意する」のがこの関数です。この関数には、データタイプを指定します。チューブの例で言うところのAやBといったデータが文字列だったので、文字列の定数を要素データタイプという入力に配線しています。
次に、このキュー取得の関数の右上から出た太いワイヤが二つのWhileループにわたり、上側では要素をエンキュー、下側では要素をデキューという関数に配線されていることがわかります。この太いワイヤは、「このチューブに対しての操作ですよ」という情報を伝えています。
要素をエンキューとは「チューブに値を入れる」動作をします。先ほどのイメージで言うところの、AとかBというデータを入れるイメージですね。
一方で、要素をデキューは「チューブから値を取り出す」動作をします。チューブの先からAとかBというデータを取り出すイメージですね。
とにかく、これで「ループ間でデータを共有している」ことになっています。上側のループで得られた何らかのデータ、これを上側のループで処理することもできますし、要素をエンキューでキューの中に入れて、下側のループの要素をデキューで取り出せば、同じデータを下のループでも扱えるようになっているわけです。
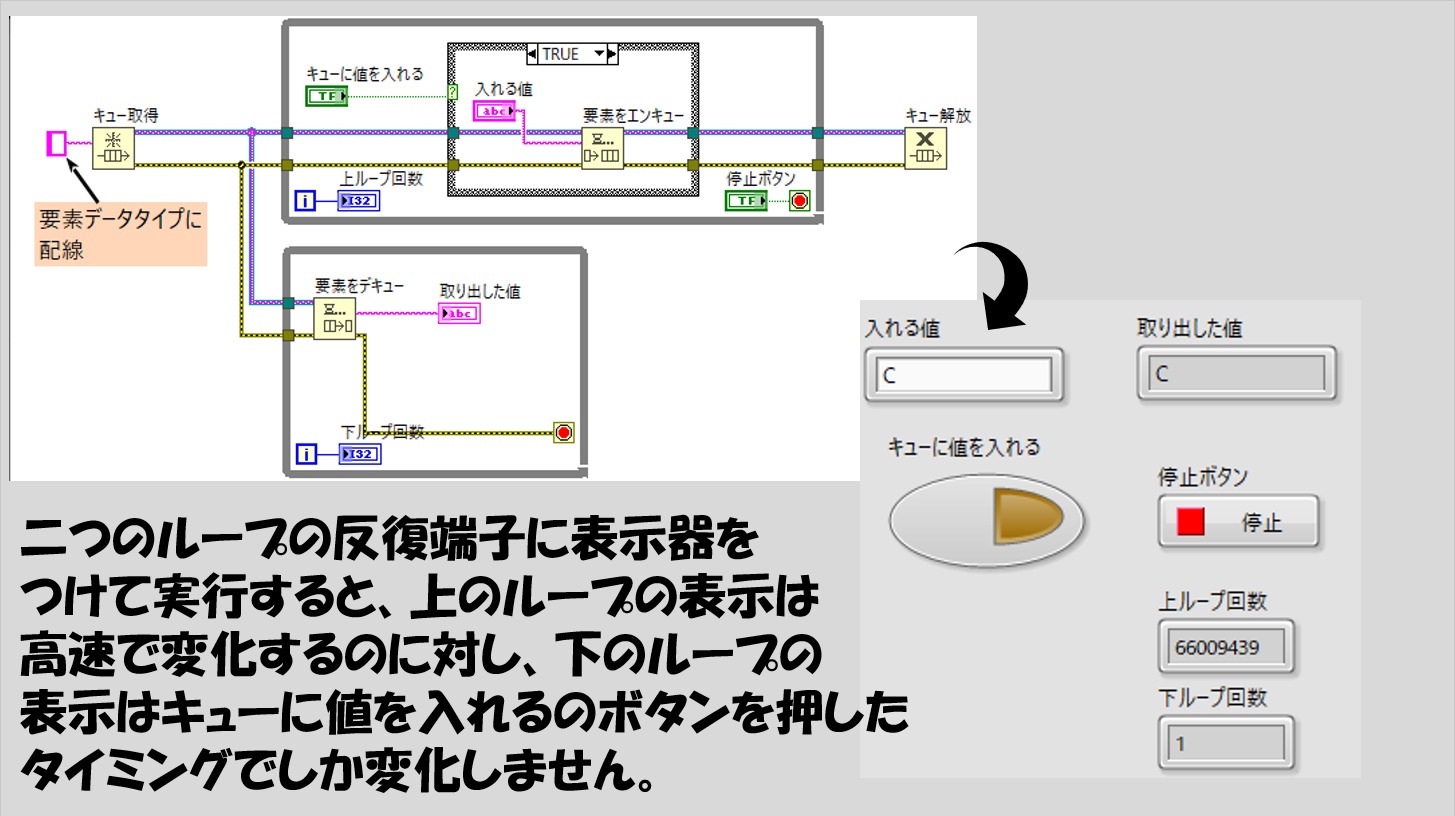
試しにこのプログラムを実行してみます。「キューに値を入れる」というブールボタンをラッチ動作としているので、「入れる値」という文字列制御器に何か値を入れ、ブールボタンを押すと取り出した値の部分に同じ値が出ることが確認できます。
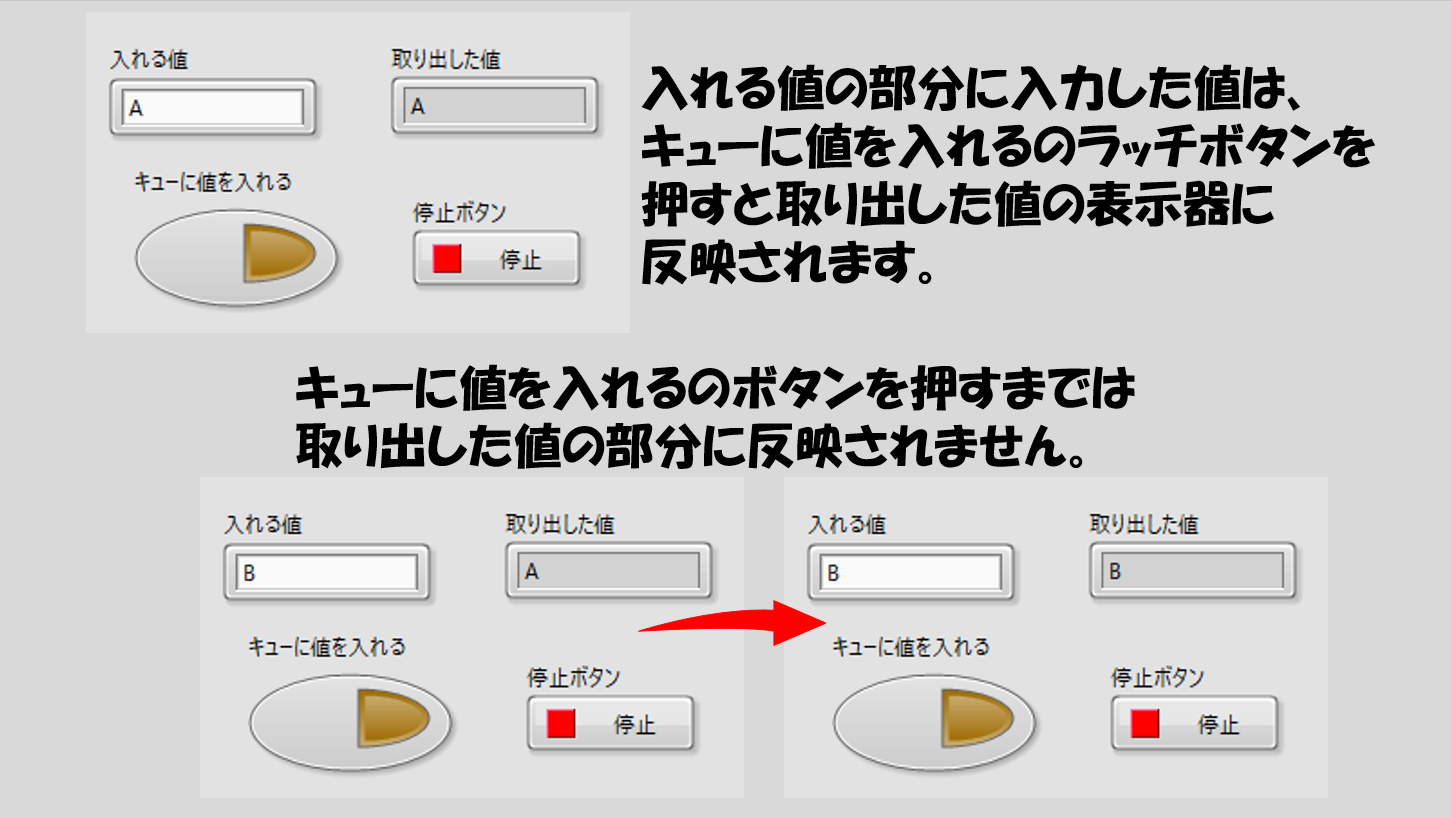
この仕組みがキューの基礎です。エンキューしたらデキュー側から取り出せる、そのため二つのループでデータを送信、受信するような動作を実現できます。
なお、要素をデキューの関数はタイムアウトの設定ができますが、デフォルトではタイムアウトをしないように無限に待機するので、要素がエンキューされる(あるいは後述するようなエラーが起こる)までは一切動作しません。必要な時にしか動作しないのはイベントストラクチャを彷彿とさせますが、無駄がないプログラムとなります。
ここから一歩踏み込んで、チューブの例で見たような、順番が保証されている様子も確認してみます。分かりやすくなるように、プログラムを書き換えてみます。
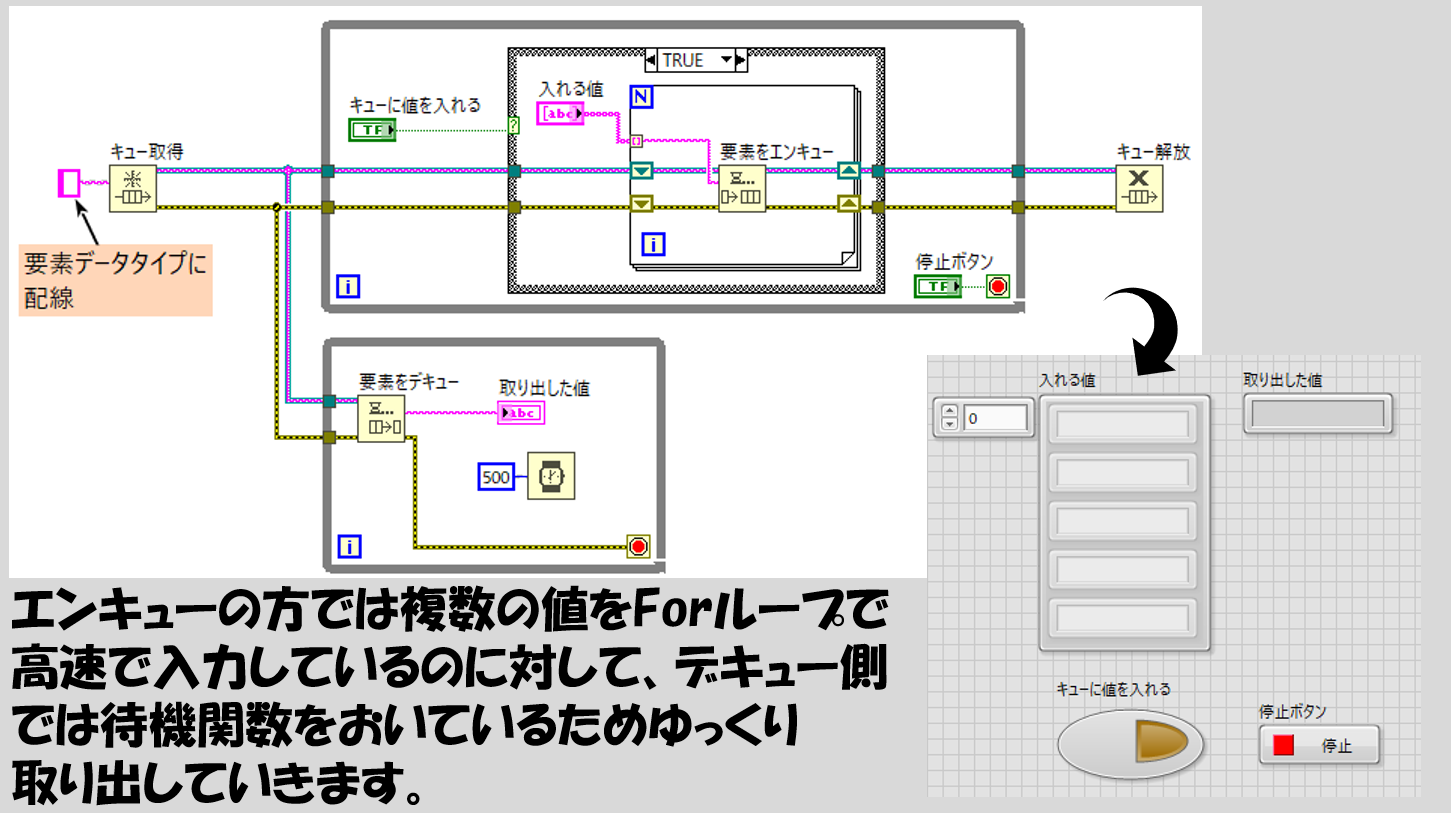
このプログラムを実行し、入れる値の文字列配列に適当な値を何個か入れてキューに値を入れるのボタンを押すと、配列の上から順に取り出した値の部分に表示されることが確認できると思います。ただしこの書き方の都合上、配列の要素0の値は一瞬で消えて次の要素1の値が出るので、要素0の値がちゃんと取り出せているかも見るには実行のハイライトを使用するといいと思います。
さて、二つのプログラムを紹介してきましたが、プログラム終了時の動作について気になるところはないでしょうか?
上側のwhileループは停止ボタンを押して止めることになります。下側のループはエラーが配線されているだけなのですが、これで実際にプログラムが終了するのですが、あれ、要素をデキューしていた方のWhileループはいつの間に止まったんだ?と思うかもしれません。
実は、下のWhileループはキュー解放の関数の実行によって停止しています。簡単に説明すると、キュー解放によってキューそのものが破棄されるため、そもそも要素を取り出すという動作が意味をなさなくなります(取り出す「元」が破棄されたからですね)。そのため、要素をデキューの関数からは「自分が今まで要素を取り出していたキューが見当たらなくなったけれど?」という感じでエラーを出すわけです。
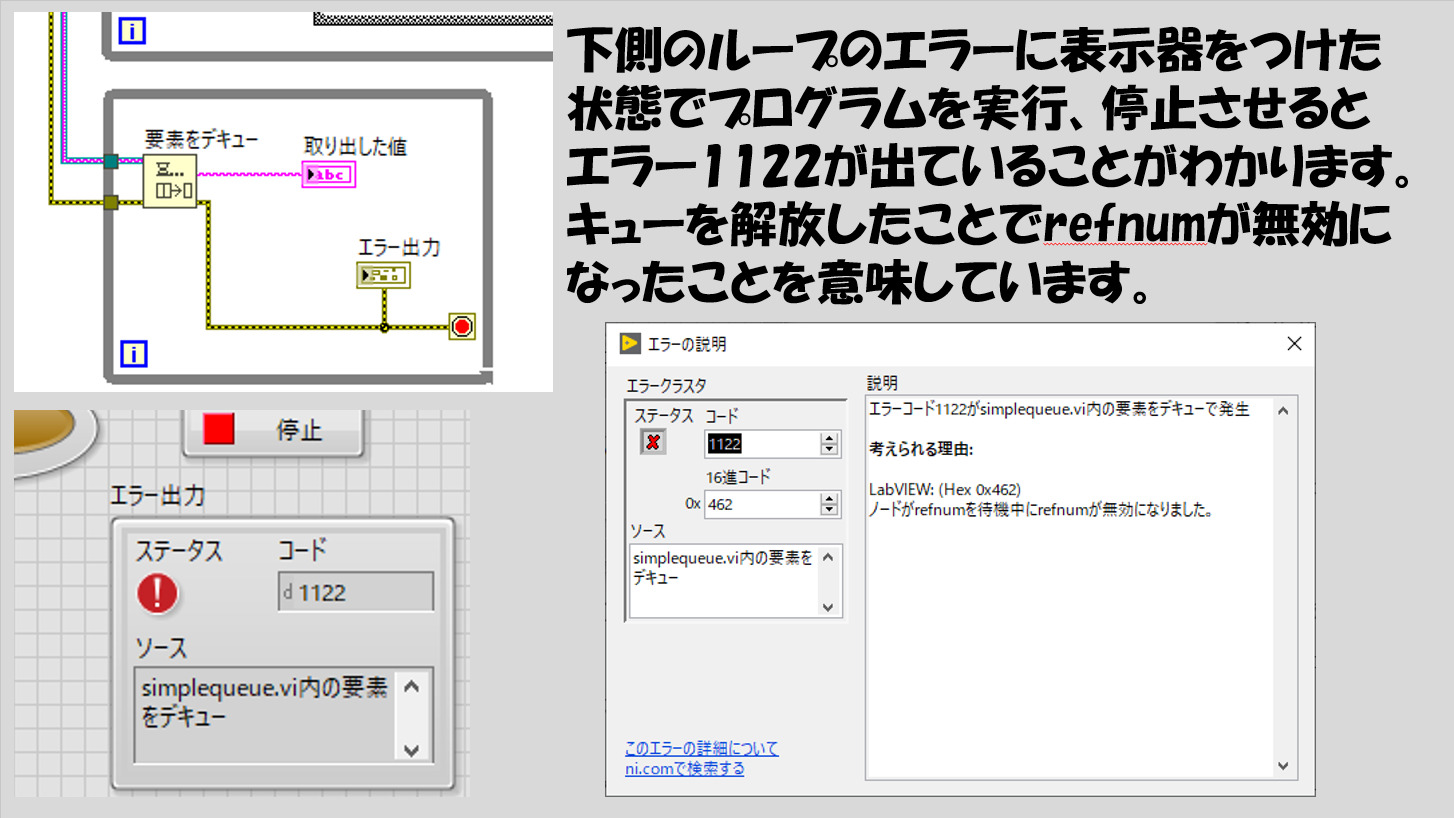
エラーが出たことで、エラーワイヤからはエラー=TRUEの情報が出てこれが下のWhileループの条件端子に伝わり、ループが止まります。そのため、この下のWhileループはエラーによって止めるという方法をとっています。
エラーをわざと起こすのに抵抗があるかもしれません。が、このような止め方もキュー関数使用時にはアリです。エラーが出ても、プログラムの流れとしては問題ありません、むしろ進んでエラーでループを止めるように組んでいて、「意図通りに動いている」ことは間違いないです。
キューの使い方を工夫する
ただし、この書き方をすることによる弊害もあることがわかります。それは次の二点で、
- 上側のループが止まりキューを解放した時点で実はキューにまだ要素が残っている場合にそれらの要素はデキューされないまま消滅する
- エラーによってデキュー関数が終わる場合、最後に出てくる値は「デフォルト」の値になっている
という問題が挙げられます。これらの対処方法も見ていきます。
まず、キューのデータが消滅してしまうかもしれないという問題です。
キュー解放でデキューの関数からエラーを出させて下側のWhileループを止めたはいいものの、上側のWhileループでキューに入れていた要素全てが下側のWhileループでデキュー処理されているとは限りません。仮にキューの中にデキューされていないデータが残っていたとしても、キューが解放されれば使われることなく消えてしまいます。
このようなことを起こさせないようにする工夫として、キューが空になってからキューを解放するという手法をとります。そのために便利な関数が、キューステータス取得関数です。
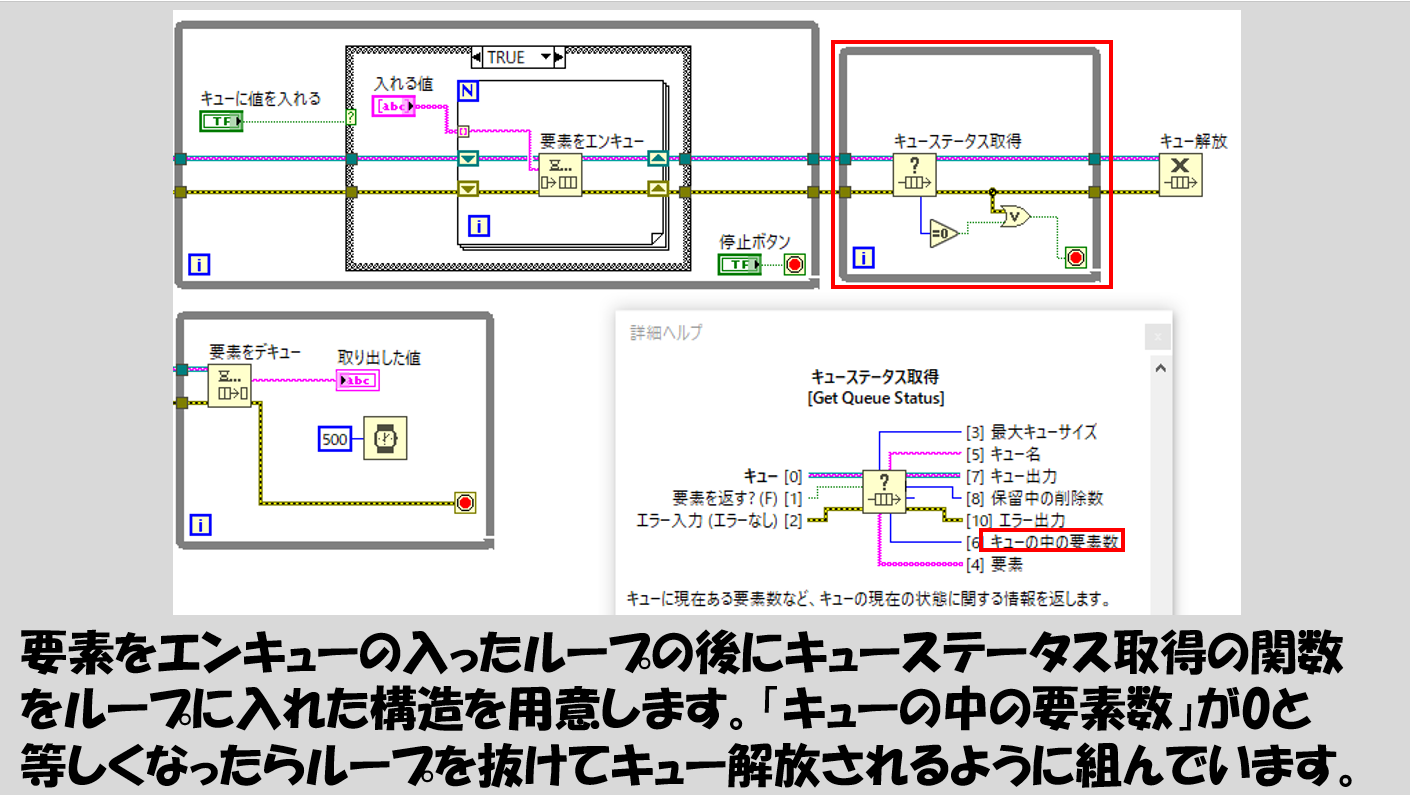
このような書き方をすると、上側のWhileループが終わって、その後の小さいWhileループに移り、ここで「キューの中に要素はまだあるかな?」ということを確認しています。
キューは、先ほどのイメージをつけたときの図のように、一度データを取り出すとチューブの中にその値は残りません。取り出してしまうからですね。そのため、チューブにもうデータを入れない状態としておいてから(上のWhileループが閉じて要素をエンキューがこれ以上実行されなくなってから)、チューブからデータを取り出し続けると(下のWhileループから要素をデキューでデータを取り出し続けると)、いずれチューブは空になるはずです。
すると、キューステータス取得関数の入ったWhileループでは「今キューに要素が何個残っているか?」を調べていて、それが0とイコールだったらこのWhileループが止まるようになっています。
これで、せっかくキューに入れたデータが消去されることなく全部使えるようになりました。しかし、プログラムを実行していると、もう一つの不都合があることに気づきます。
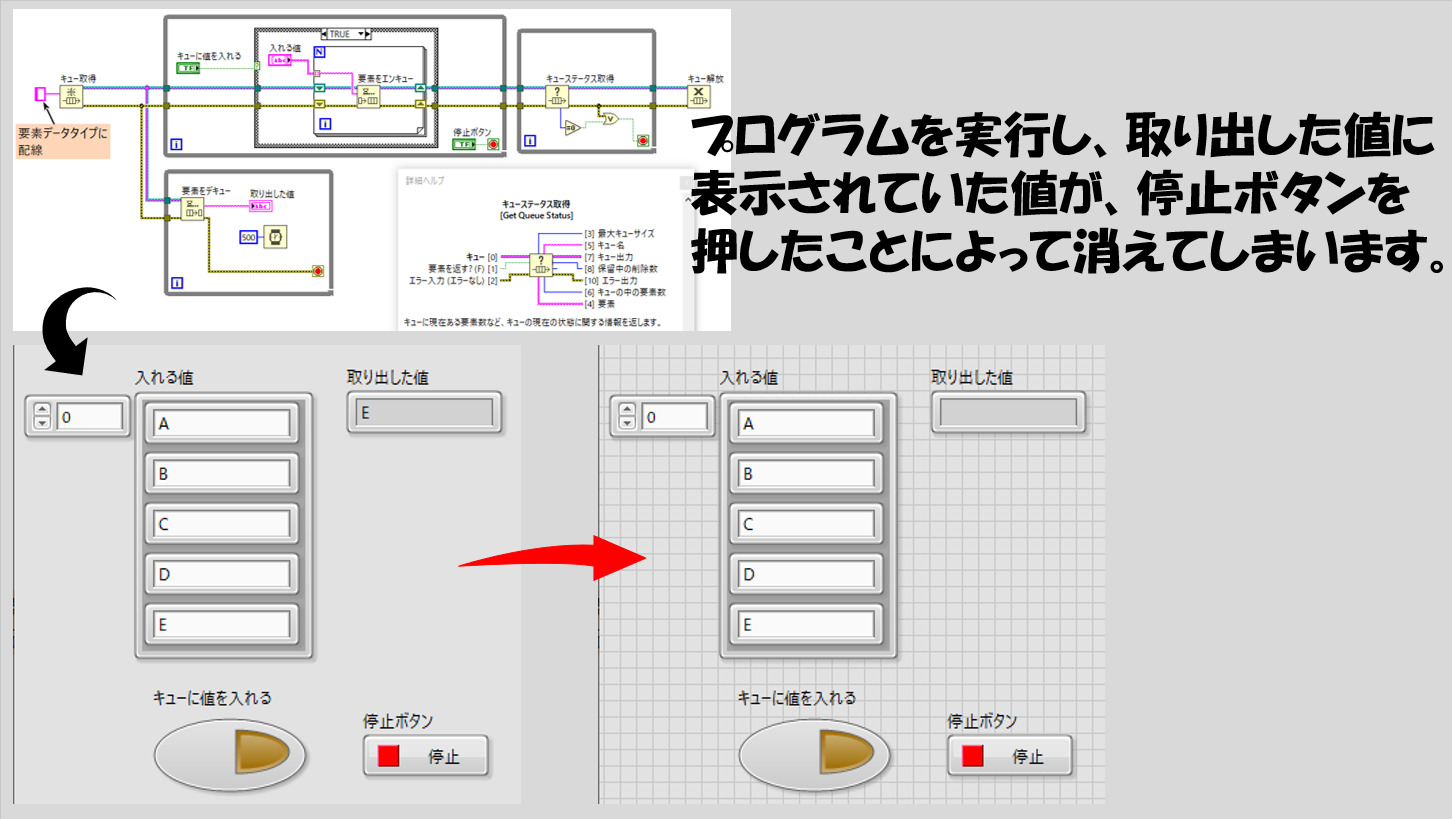
最終的にキューを解放してデキューの関数からエラーが出る際、キューの中は空になっているはずなので、デキューの関数の要素の出力からは本来何も出せないはずで、最後に取り出していた値が表示され続けているはずなのに、エラー出力時に何かしらの値を出す必要があるため、デキュー関数は「デフォルト」の値を出してしまうため、プログラム終了時には表示器にデフォルトの値が出てしまうということです。
ですが、このデフォルトの値は本来何の意味も持ちません。そもそも意図してエンキューされた値でもないわけで、必要ないはずのデータです。
例えば下側のループで、上のループから受け取ったデータを保存するようなプログラムを書いていたとします。この場合、デキューの関数が一番最後に出すデフォルトのデータは意味のないデータとしてファイルに書き込まれてしまいます。
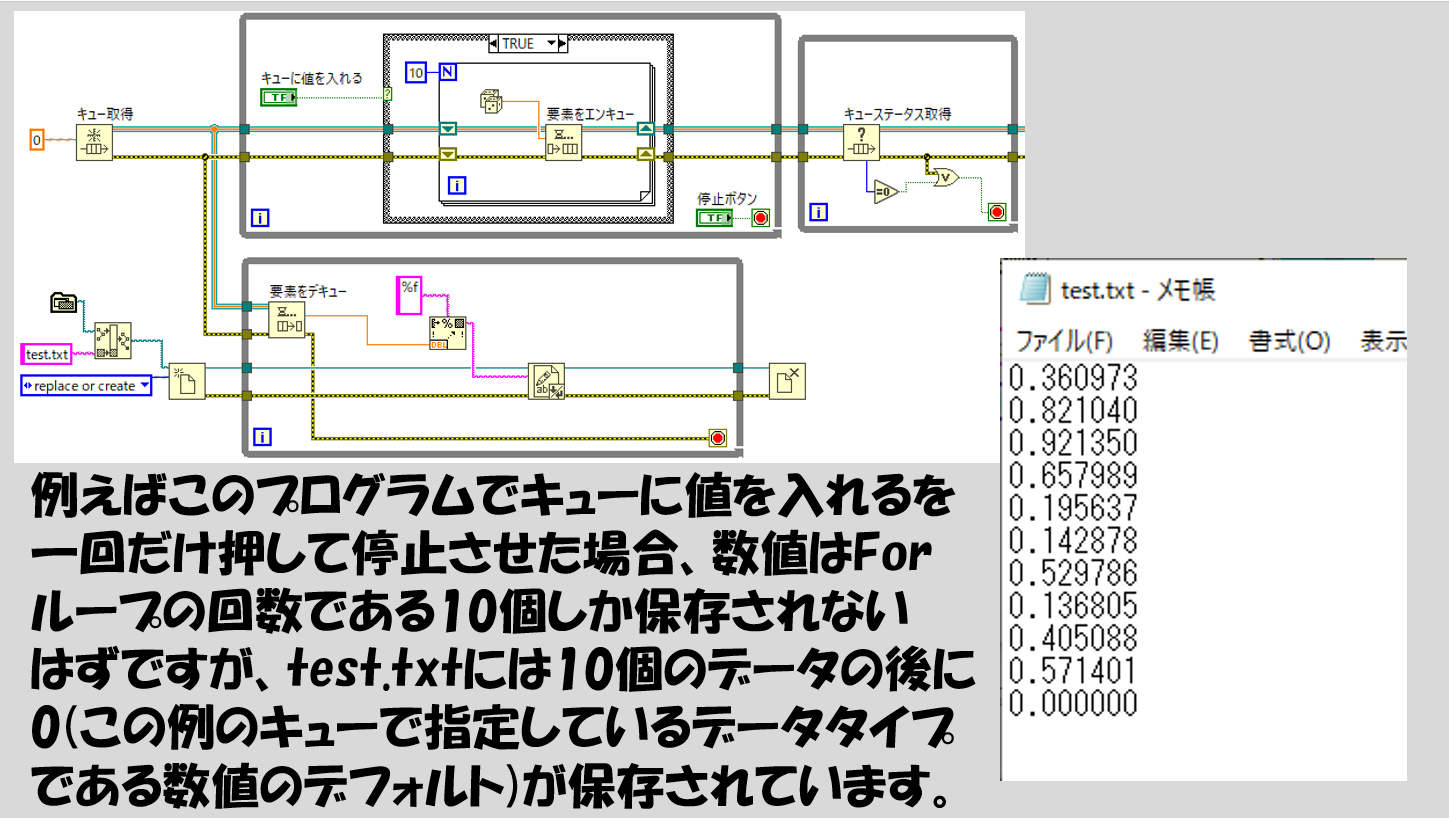
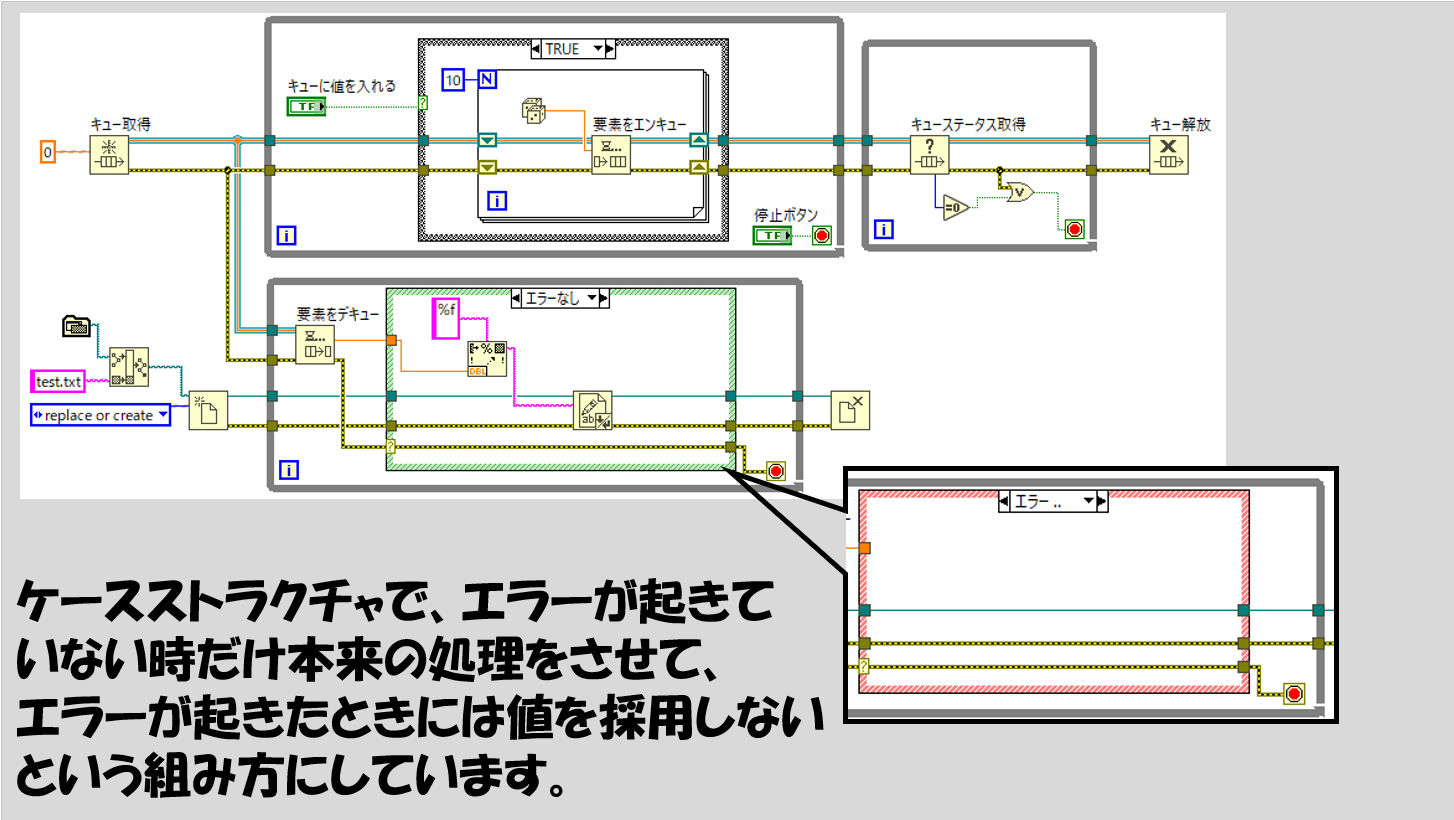
これを防ぐ簡単な方法は、ケースストラクチャを使用することです。下側のWhileループで本来したい処理はケースストラクチャの「エラーなし」で行わせて、一方で「エラーあり」の場合には特に何もせず、ただただエラー配線をWhileループの条件端子に渡すだけとします。
こうすれば、余計なデフォルトデータを扱わせることなく下側のループも終了させることができるようになるわけです。
これがキューを使ったループ間でのデータ共有の全貌です。上記の例ではキューで扱うデータタイプとして文字列や数値データを使用していますが、クラスタや配列など、他のデータタイプでももちろん対応できます。
さらに、キューは異なるVI間でもデータを共有できます。それは、キュー生成の関数の右上から出る太いワイヤで「このキューを使用しています」という情報を、同じVIの中だけでなく、違うVI同士でも共有することができるからです。キューというチューブを一つ作っておいて、あとはどのVIであっても(正しく組めば)同じキューを見てデータを入れたり出したりできます。
そのため、キューはローカル変数だけでなくグローバル変数の代わりにもなることができます。
キューの利点と注意点
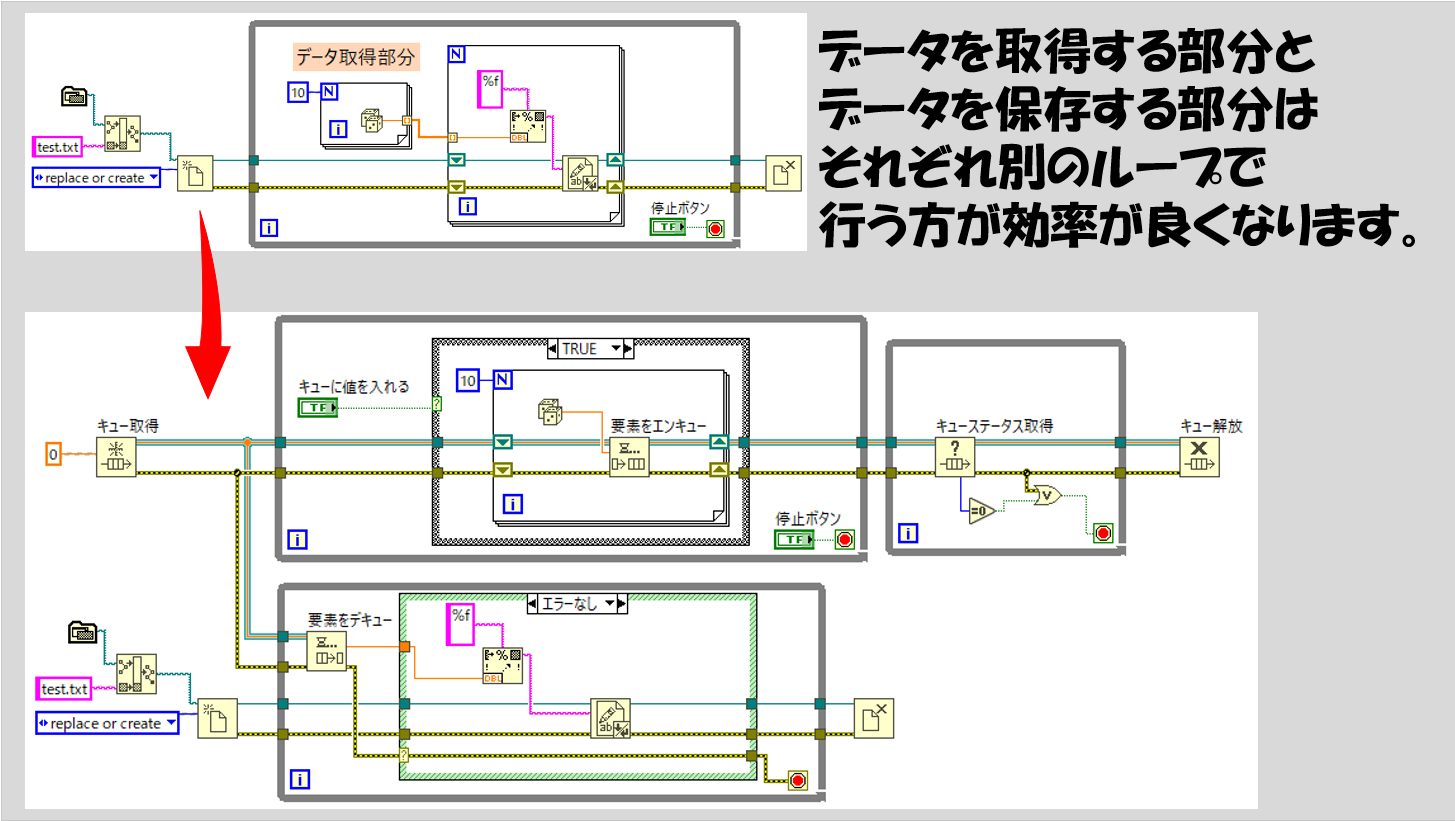
キューを使用したプログラムは非常に強力です。簡単にループ間でデータを受け渡せるというだけでなく、「それぞれのループをそれぞれの処理に専念させる」ことができるためです。
ループは、その中に入っているすべての処理を実行して完了してからでないと次のループに進めないという仕様がありました。つまり、一つのループにたくさんの処理が入っていると、それらを完了するのに時間がかかり、結果ループが思ったタイミングで回らなくなることがあります。
一方で、キューを使用すると、例えば要素をエンキューするループでは何かしらの値を取得することだけに専念して、これをエンキューし、要素をデキューするループではそのデータに何らかの処理を加えたりするということができます。分業ですね。
キューの性質について重要なことは、
- 要素を入れた順に、要素を取り出すことができる
- 要素を欠損する心配がない
といったことが挙げられますが、それぞれに対して注意点もあります。
- キューの順番を正しくコントロールする
- キューがいっぱいになる
チューブの例で紹介したように、キューは要素を入れた順番に出すことができます。逆に言えば、その順番でしか取り出せません。これは、First In First Out (FIFO)と呼ばれます。
ただしキューに入れる側で工夫する方法があって、「他の要素が既に入っているけれど優先的にこれを次に取り出すようにしてほしい」という操作を行える「先頭にエンキュー」という関数があります。その名の通り、値をキューの一番最後に追加するのではなく、先頭に追加してしまうため、デキューはこの関数でキューに入れたものを次に取り出します。
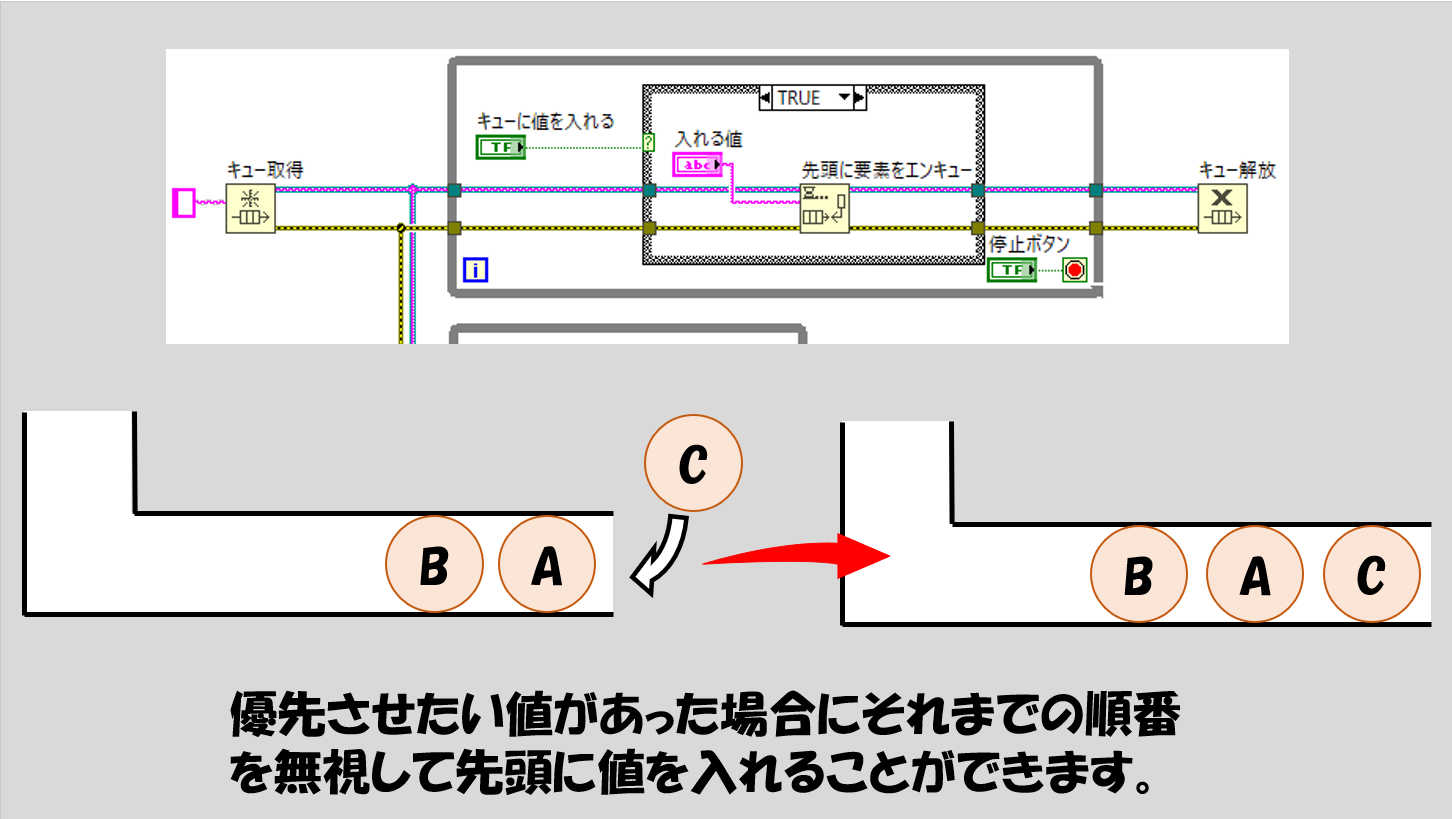
また、要素を欠損する心配がないという点があります。チューブに適切にデータを入れておけば、そのチューブを破棄しない限りデータはこのチューブにたまっていくだけでチューブの中で一部が消失することはないので、エンキューしたものは確実にデキューできます。
ただしチューブの大きさは無限ではありません。実際はチューブの大きさはキュー取得の関数で「サイズ」として指定できるのですが、あくまで有限です。
もし、エンキューとデキューがほぼ同じタイミングで行われるのであれば、キューがいっぱいになることはありません。入れたものをすぐに取り出せるためです。しかし、何らかの理由で、取り出す側よりも早く要素を入れる動作が続いたとします。すると、チューブの中にはデータがたまっていくことになります。
こうしてやがてチューブのサイズいっぱいいっぱいまでデータがたまってしまった場合にはどうするか?データは欠損しません。サイズがいっぱいになったとしても、チューブの中のデータを勝手に消してしまうことはないです。
ではどうなるかというと、「キューに空きが出るまで要素をエンキューの関数が止まる」という動作をします。要素をエンキューの関数はキューがいっぱいになると空きが出るまで要素を入れるのを待ち続けます。
確かにこの方法であればキューの中のデータを欠損することはありません。ただし、要素をエンキューのWhileループが滞ってしまうことになりかねません。
たとえば、要素をエンキューがあるループが1秒に一回一つのデータを入れているとします。なので、デキューされるのは「1秒ごとのデータ」になっています。
しかし、キューがたまると要素をエンキューのループは1秒に一回という実行ができなくなります。こうなると、エンキューされる要素はもはや1秒後のデータではなくなり、したがってデキューされるデータも1秒ごとのデータではなくなります。
それでもいい場合には問題になりませんが、たいていの場合これでは困ると思うので、その場合にはキューのサイズをもっと大きくする(その分メモリを消費します)か、デキューのループがエンキューのループよりも遅くなっている事態を解決するようにプログラムの見直しを行います。
データの欠損はある程度目をつぶる、ということであれば、「サイズがいっぱいになったら先頭にあったものを強制的に排出して空きを作る」という動作の要素をエンキュー(ロッシー)関数もあります。
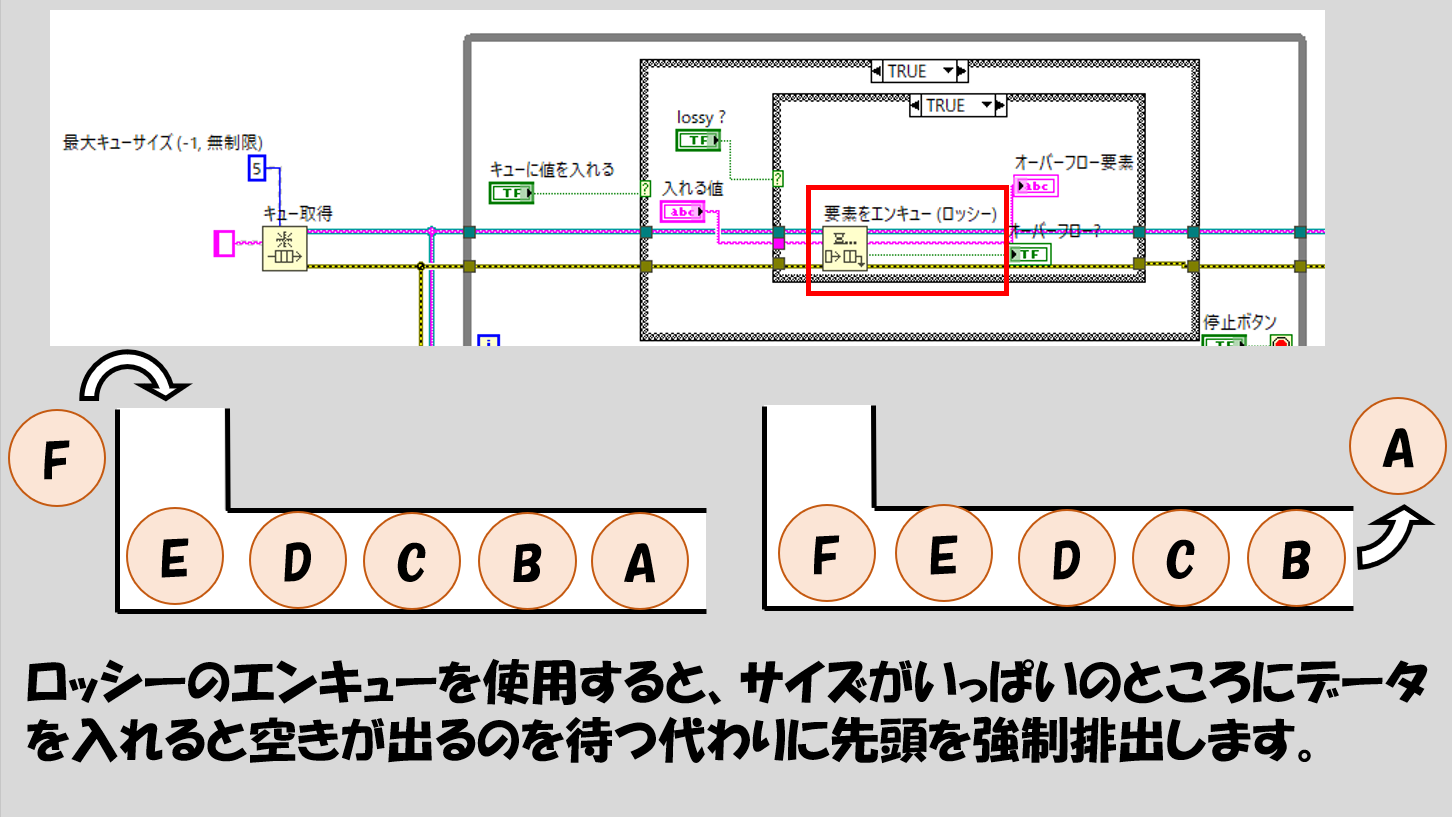
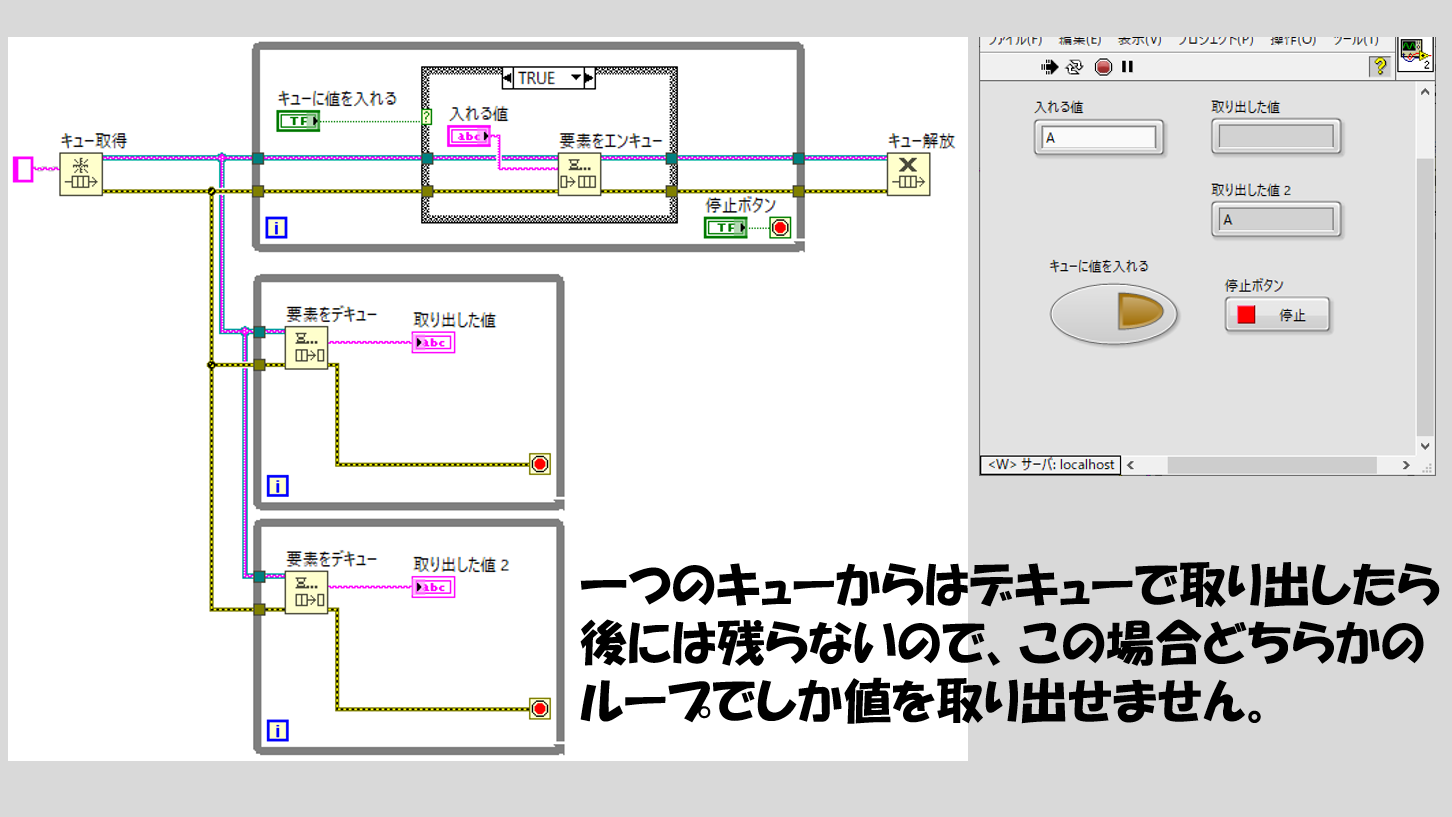
さて、ここまでキューの関数の利点と注意点を紹介しましたが、さらにもう一つ、重要なことがあります。それは、キューはその性質上、2つのループ間でデータを共有することはできますが、3つ以上のループでデータを共有することができないということです。
イメージのところで説明したように、値を入れて取り出すとキューの中にはデータが残っていません。他のループでデキューを置いたとして、他の部分で取り出されたデータは再度取り出すことはできないのです。
これを防ぐには、キューを2つ用意してデキューの際に二つともに値を入れるといった方法が考えられます。
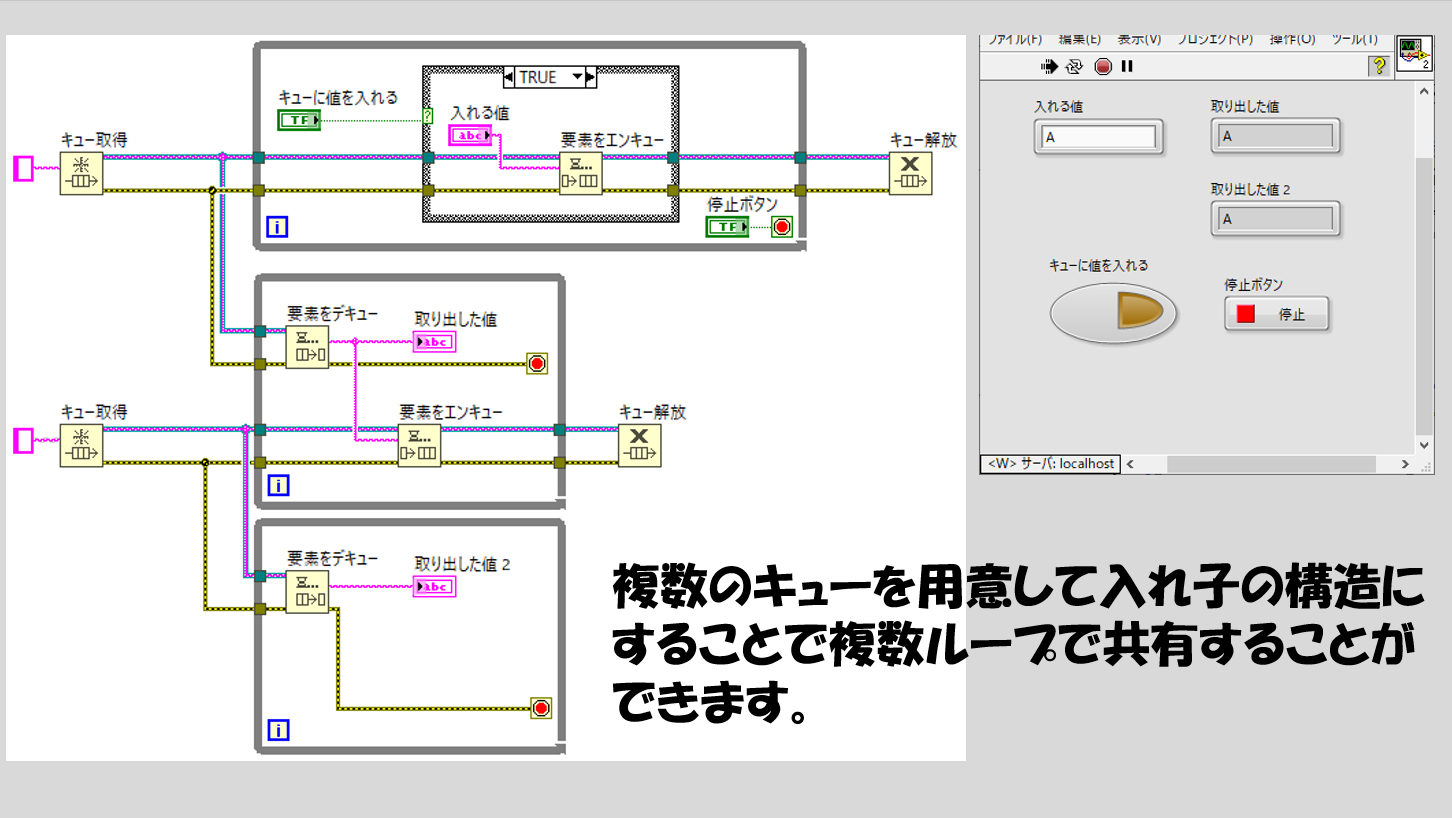
が、実は別の選択肢として「ノーティファイア」という関数があります。こちらは3つ以上のループでも値を共有できる関数として使うことができるようになっています。
「じゃあキュー要らないじゃん」となるかとそうではなく、ノーティファイアにも弱点はあります。
そこで次回は、ループ間でデータを共有する別の選択肢であるノーティファイアの仕組みについて紹介していこうと思います。
もしよろしければ次の記事も見ていってもらえると嬉しいです。
ここまで読んでいただきありがとうございました。
コメント