この記事で扱っていること
- 画像認識プログラムを作る方法
を紹介しています。
注意:すべてのエラーを確認しているわけではないので、記事の内容を実装する際には自己責任でお願いします。また、エラー配線は適当な部分があるので適宜修正してください。
機械学習、ディープラーニングという技術が発展し今や世の中の様々なアプリケーションに使われていますが、LabVIEWであってもこれらの技術の力を利用したプログラムを作ることができます。
本記事で紹介している画像認識のプログラムでは、画像のどこに何があるかを認識させることができます。
本格的に実装するとなると、例えばTensorflowを使用して学習、モデルを作成するといったLabVIEW以外の知識も必要になりますが、もっと手軽に実装したいという場合には既に世の中にある公開されているモデルを活用するという選択肢があります。
というわけで、本記事では特別な知識をあまり必要としない状態で画像認識のプログラムを実装する一例を紹介します。
学習モデルのカスタマイズについては触れないのでご了承ください。
また、関数の仕様の都合上、Vision Development ModuleというLabVIEW用の有償アドオンソフトを使用しかつLabVIEWは64 bitである必要があります。
どんな結果になるか
フロントパネルには、画像表示器と対象となる画像ファイルのパス、そして画像認識のためのモデルを学習しファイル出力したpbファイルを指定するパス制御器を置いています。
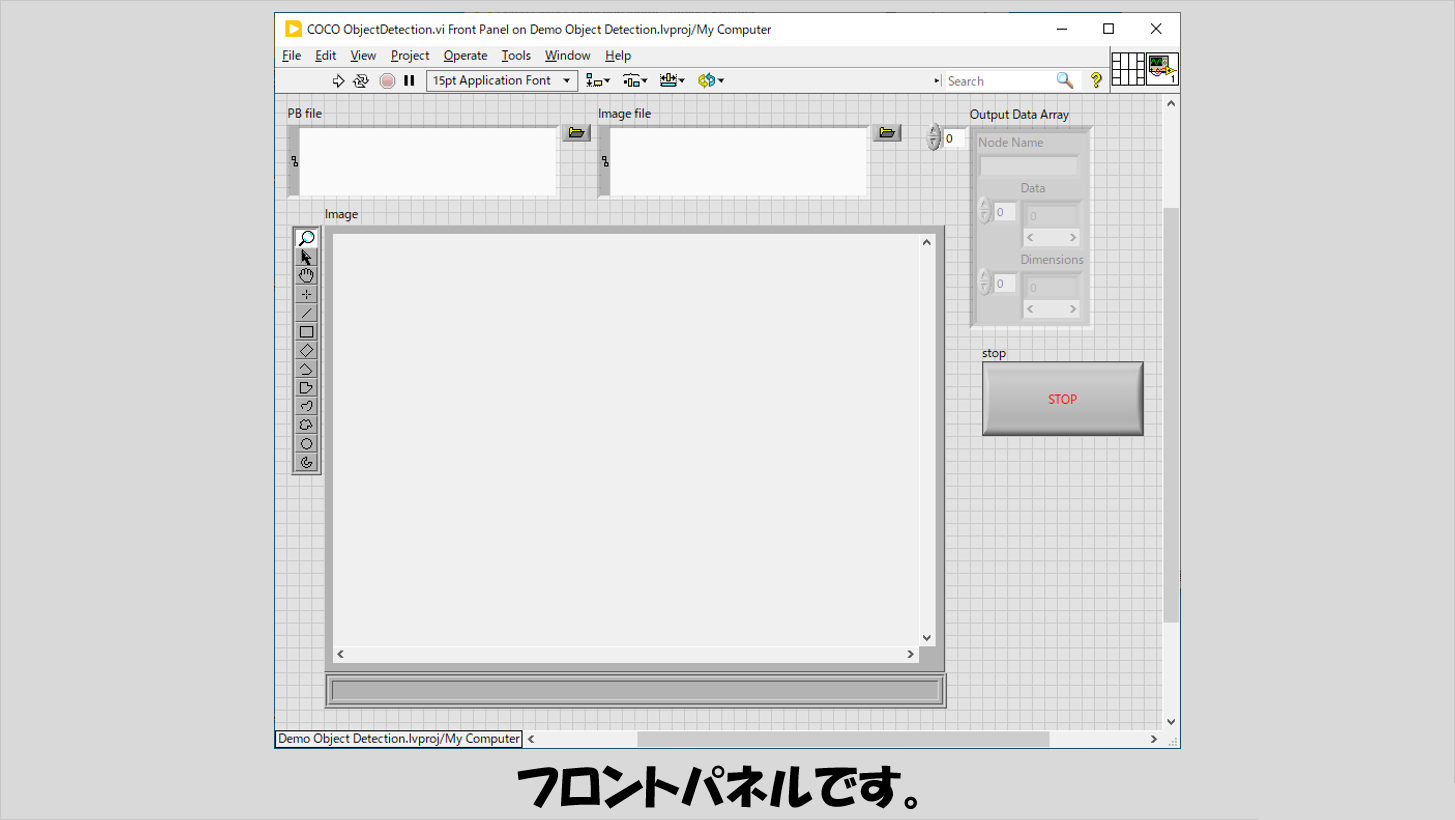
プログラムを実行し、対象とする画像を選択することで、その画像のどこに何が映っているかを枠とともに表示できます。
下の画像は表示が少し小さいですが、左はcat、右はそれぞれの人物に対してpersonと表示されています。

プログラムの構造
まず前提として、今回使用する学習済みモデルのファイルを入手する必要があります。
本記事の例では、以下のサイトから入手しました。
具体的には、ssd_inception_v2_cocoを使用しています。項目を右クリックして「リンクのアドレスをコピー」とし、ブラウザのURLの欄に貼りつけすればtar.gzファイルが入手できるので、これを展開します。
tar.gzのファイルは、Windows 環境であれば、コマンドプロンプトから
tar -xzf <ファイル名>で解凍できると思います。
解凍したフォルダの中にあるfrozen_inference_graph.pbを今回は使用します。
つまり、プログラム実行時にはこのpbファイルをフロントパネルのPB fileのパス制御器で指定することになります。
LabVIEWのプログラムの作りはイベントストラクチャを使用しており、画像ファイルパスを指定するとその都度画像認識処理が実行されるようにしています。
Whileループに入る前に読み込んでいるファイルは、以下で説明するような、ラベルの情報を含んだテキストファイルです。
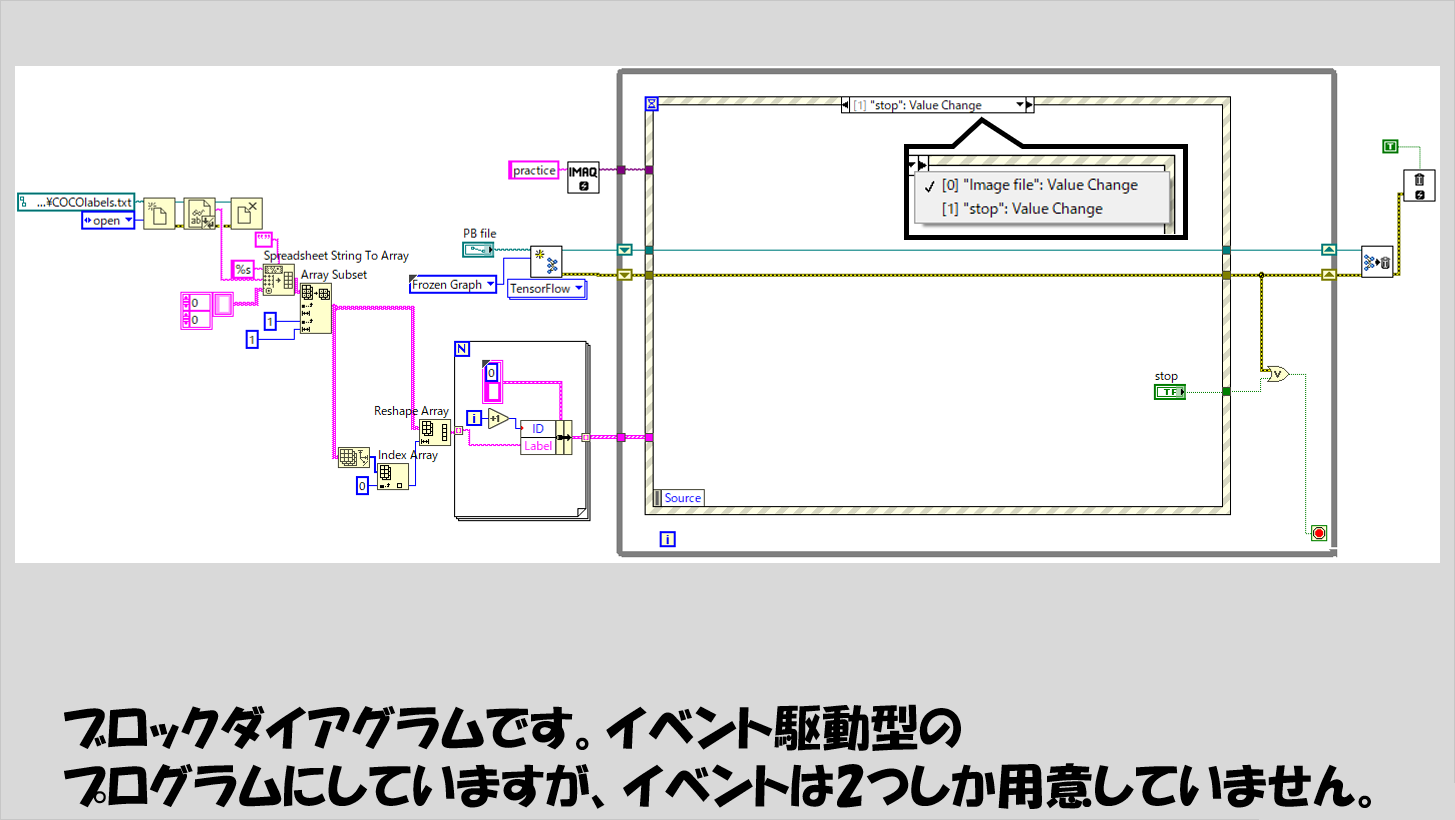
ディープラーニングのプログラムにおいては、結果として得られるのは数値の配列であり、これを「この画像にはネコが写っている」とか、「ここにヒトが写っている」などといった物体等の名前で表現するには、数値を名前(正確にはラベル)に変換する必要があります。
そのための準備として、「どの数値はどのラベルに対応するか」という換算のための情報が必要となりますが、ラベルの情報は大元のimagenet1000の情報を参考にできます。
https://gist.github.com/yrevar/942d3a0ac09ec9e5eb3a
例えば上記のgithubのページにある情報を1行目から1000行目まで丸々コピーしテキストファイルに保存してCOCOlabels.txtなどという名前で保存しておきます。
このテキストファイルの中のラベルの情報を一行ずつ読み込んで、プログラムの後半で使用できるようにします。
下の図では、テキストファイルとしてこのCOCOlabels.txtを読み取り二次元配列にした後、読み取った配列から「IDとラベル名」の組み合わせの一次元配列を作っています。
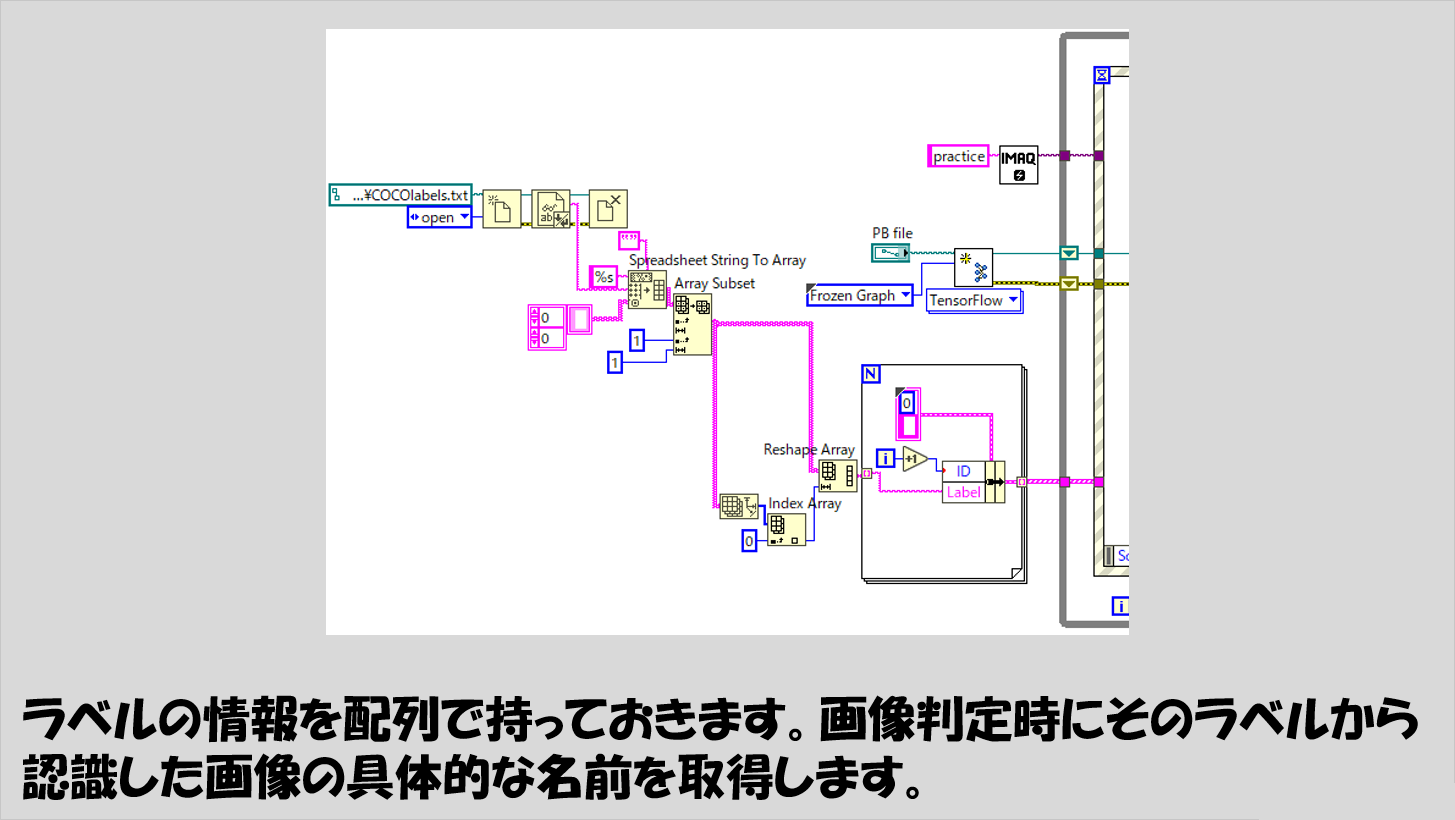
イベントストラクチャにあるイベントのうち片方は停止ボタンを押した際のイベントであり、イベントストラクチャを入れたWhileループを停止させるだけなので説明は省略します。
Image fileの値変更イベントとして以下の図のような処理を書いています。
Inputノード名はimage_tensor、Outputノード名は上から順にnum_detections、detection_classes、detection_scores、そしてdetection_boxesです。
これらの名前は、今回の記事で紹介しているモデルに対しては使用できますが、モデルに依ってノード名が変わるので注意してください。(ノード名の確認にはTensorboardを使用できます)
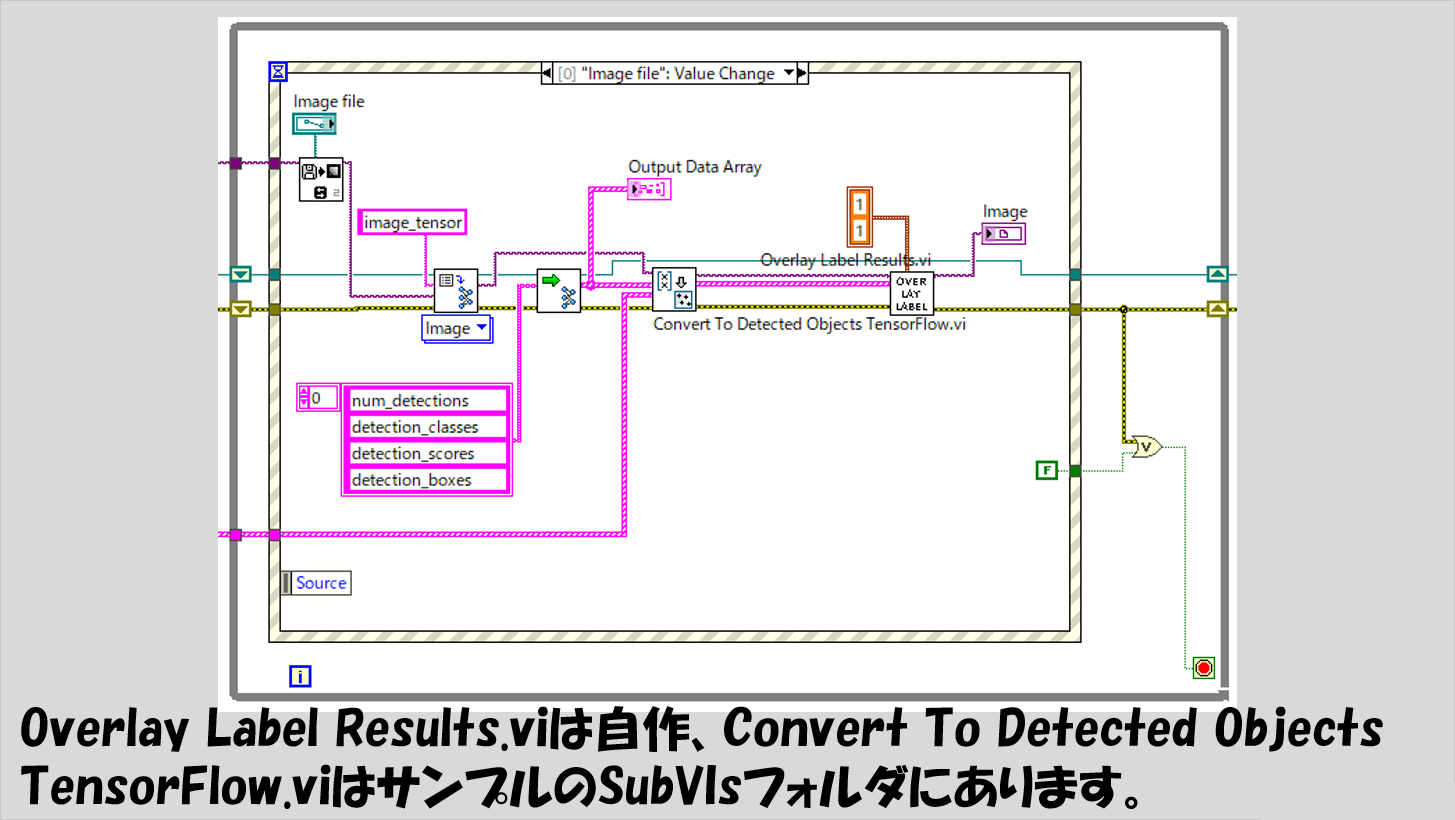
なお、Convert To Detected Objects Tensorflow.viというのは関数パレットに表示される関数ではないですが、C:\Program Files\National Instruments\<LabVIEW version>\examples\Vision\Deep Learning Object Detection\SubVIsにあるのでこれを使用できます。
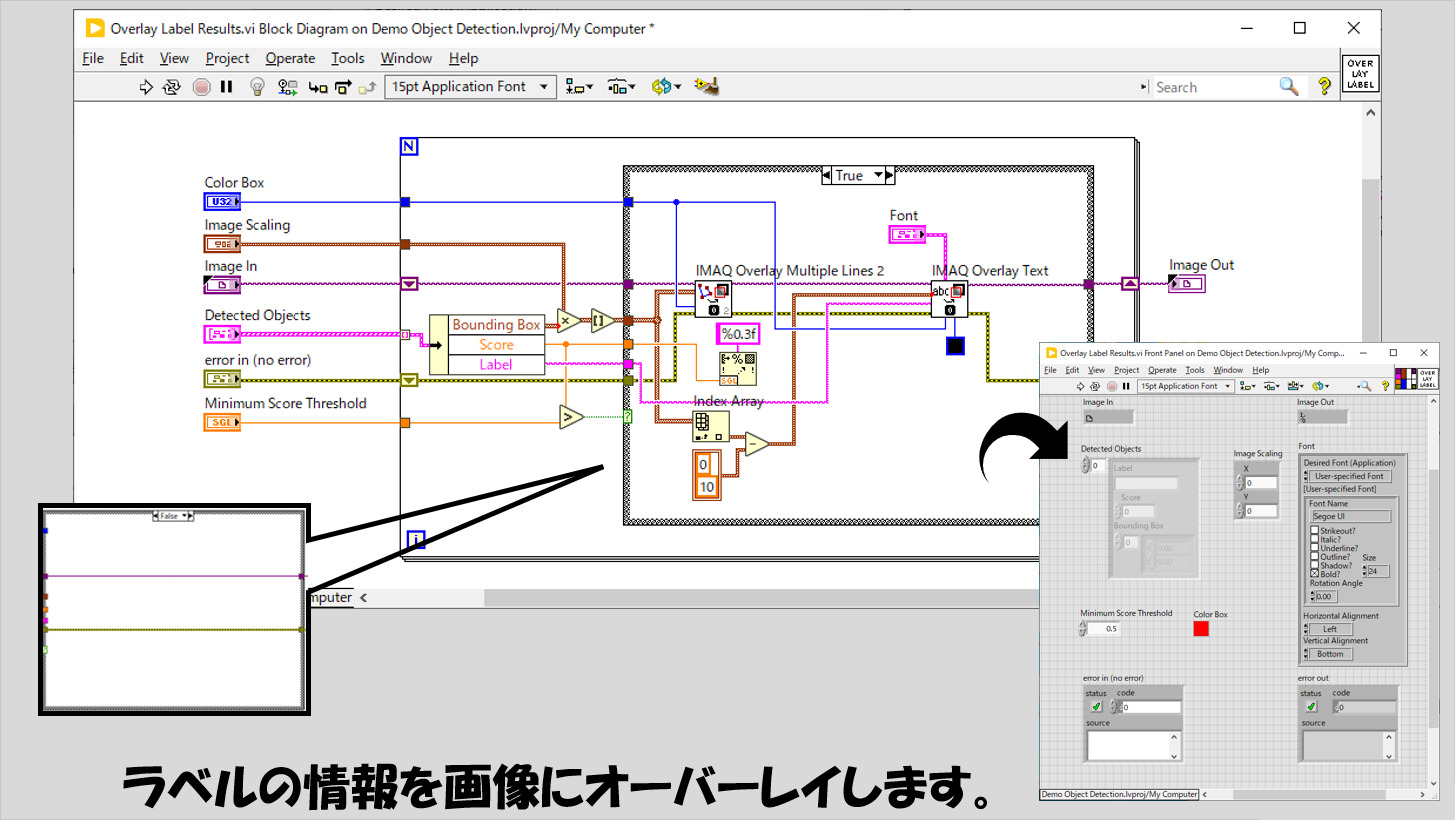
もう一つある、Overlay Label Results.viの中身は以下のようにしています。
Detected ObjectsのクラスタはConvert To Detected Objects Tensorflow.viから出力されるものをそのまま使用していますが、今回はクラスタの中のScoreは特に使用していません(そのためMinimum Score Thresholdは0としています)が、もし認識精度の低いものは除外したいということであればこのMinimum Score Thresholdを調整してください。
カメラ画像に対して画像認識をさせる
上記で紹介したプログラムは、既に撮影した画像を対象としていましたが、当然その場で撮影して取得している画像に対しても適用することができます。
LabVIEWにおけるカメラ操作の関数(Vision Development ModuleではなくVision Acquisition Softwareという別の有償アドオンソフトウェアにある)を使い慣れた方は特に問題なく実装できると思いますが、一例を以下に紹介します。
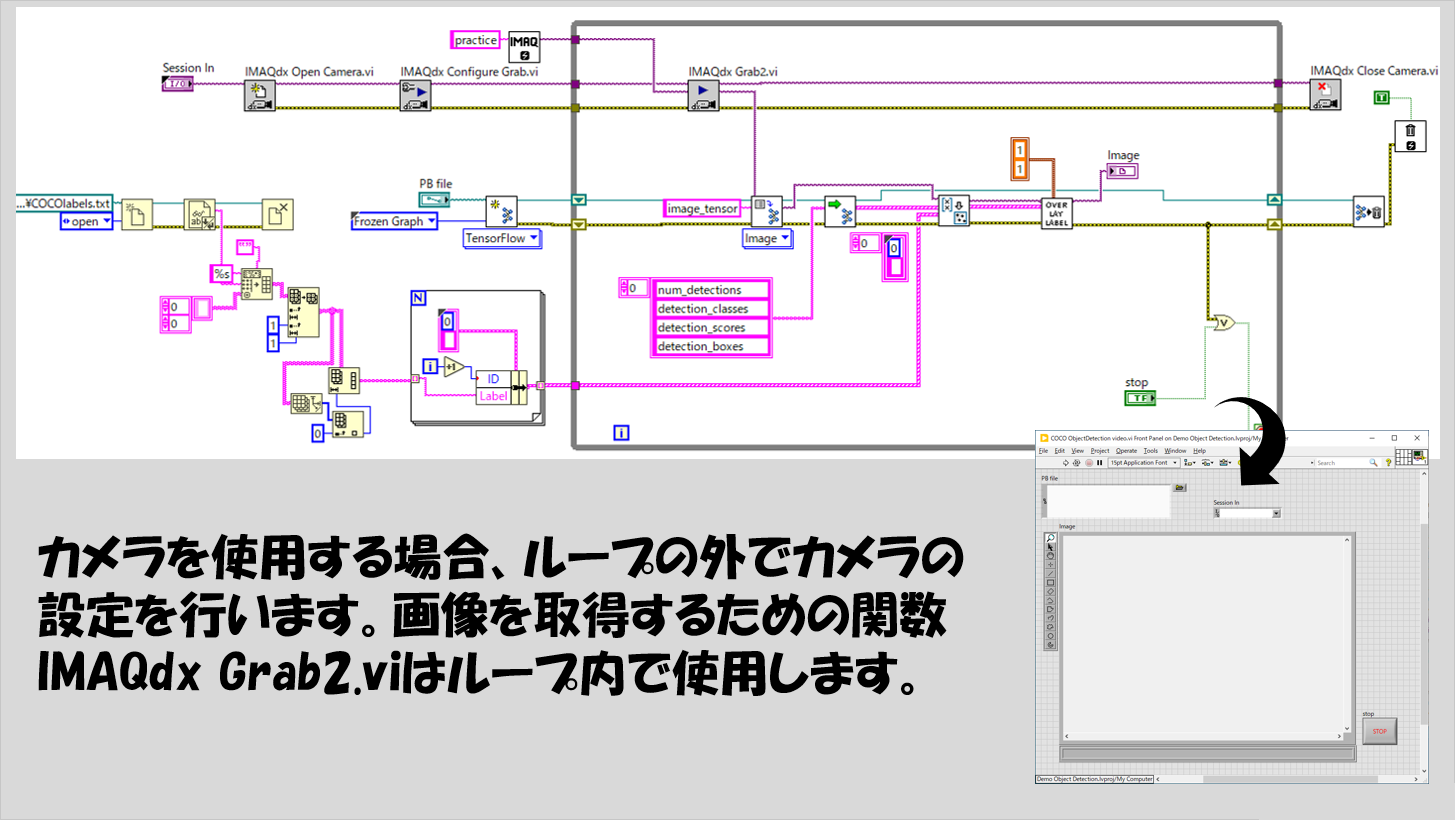
画像認識に時間がかかるため、画像取得の動作(IMAQdx Grab2.vi)を邪魔したくない、ということであればWhileループを分けてキューで画像データをやり取りするプログラムの方がベターです。
ただし、キューを使用する場合にはImageのリファレンスデータではなく、Imageを一度配列に変換したデータをエンキュー、デキューするようにしないと思った通りの動作ができないので注意してください。
本記事では、画像認識プログラムを作成する方法を紹介しました。
一からディープラーニングのモデルを作るとなると専門の知識が必要になったりなかなかハードルが高いですが、既にあるモデルを活用することで、導入のハードルはだいぶ下がると思います。
当然、そのモデルの構築の過程で学習された種類のみしか分類できないなどの制限はありますが、まずはディープラーニングの力を活かしたいという場合に試す際の参考になればうれしいです。
ここまで読んでいただきありがとうございました。

コメント