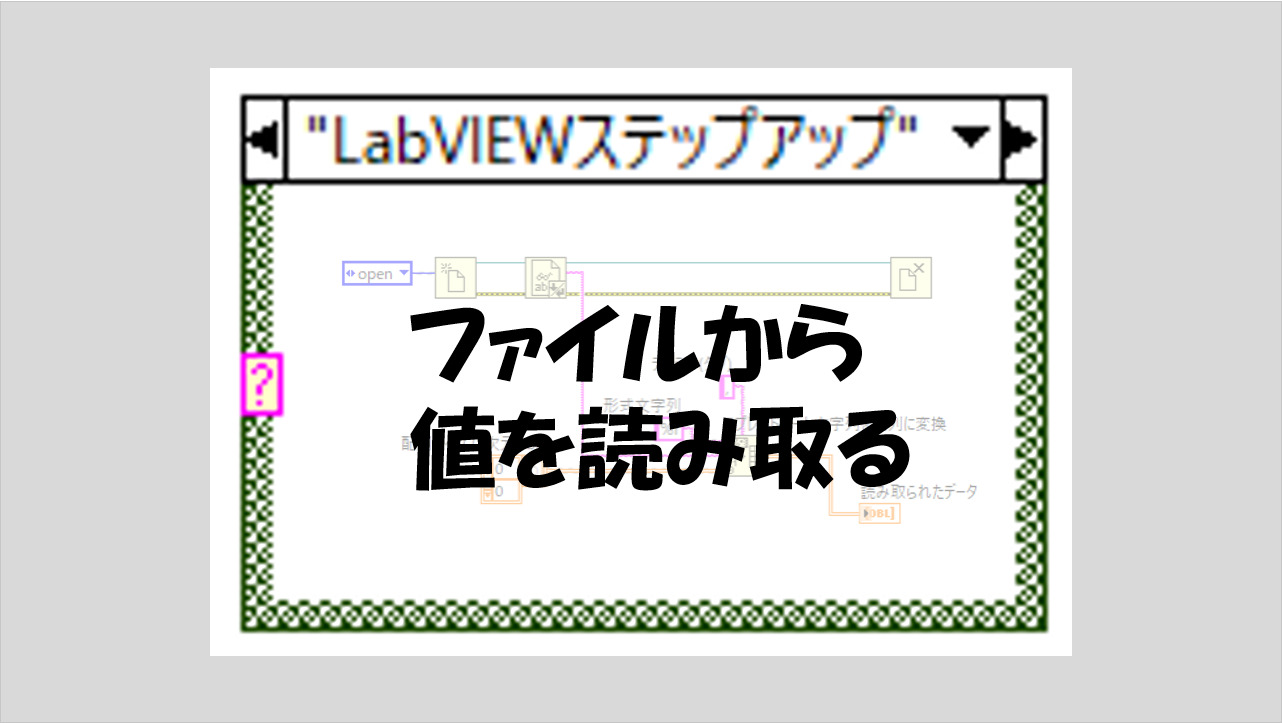
この記事は、初心者向けのまずこれシリーズ第7回の補足記事です。ファイル操作について書き込み(保存)だけではなく読み取りも行いたい、という方向けにもう少し内容を補足しています。

ファイルIOの操作については、LabVIEWでデータ計測などして得たデータを保存する、いわゆる書き込みの動作について行うことが個人的には多いのですが、もちろん読み取りも大事です。
ということでファイルIOの読み取り動作について紹介していきます。
(下記では専らテキストファイルを扱っています)
ファイルからのデータ読み取りの基本
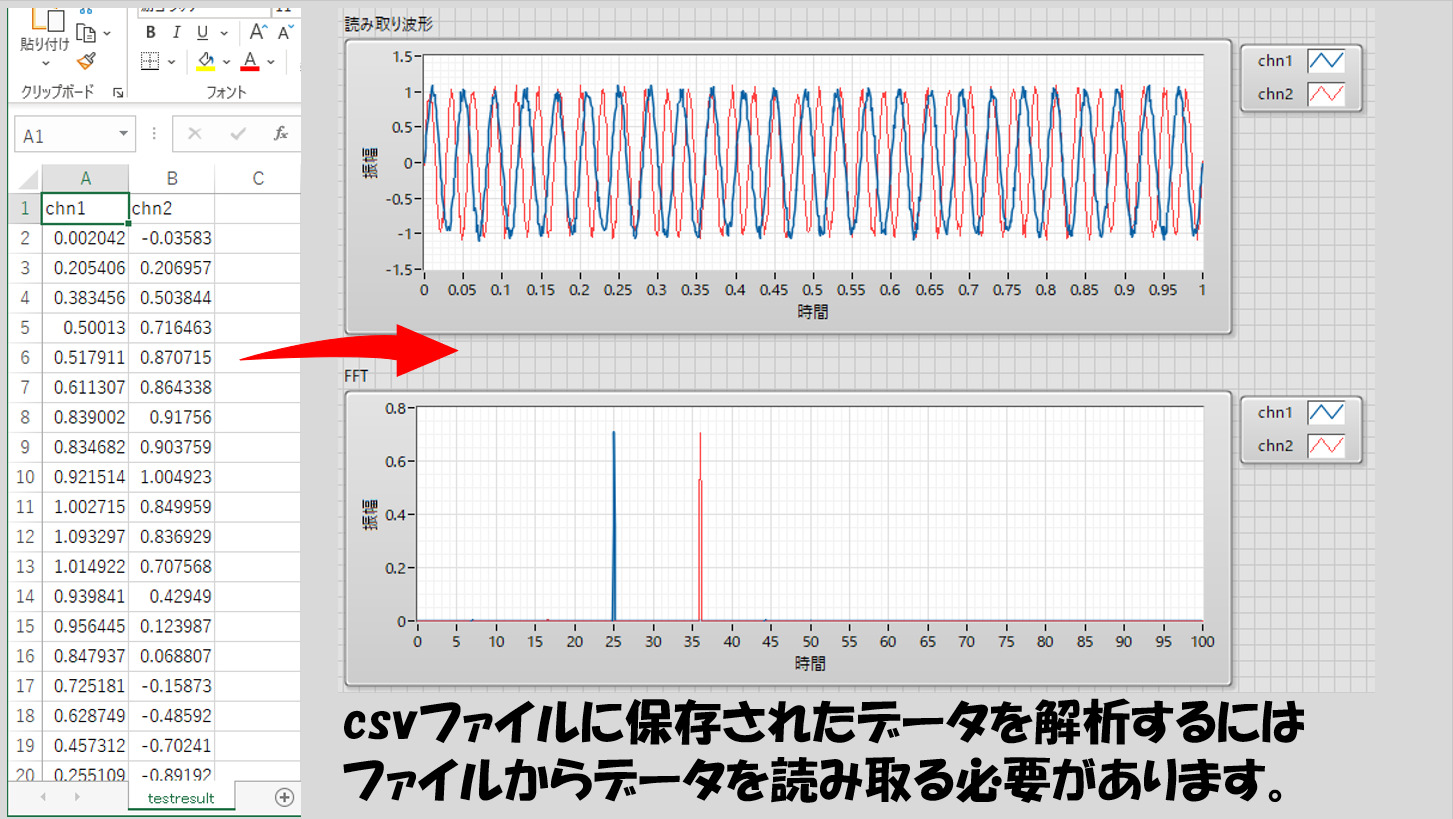
実際、プログラムの中でファイルを読み取るのはどういう場面で必要になるか、ですが、何かデータを保存したファイルがあり、その中身を読みだして解析するといったことが多いのかなと思います。
例えばLabVIEW以外のソフトウェアで取得したデータファイルがあり、それをLabVIEWで読み込んでFFTなどの解析を行う、といったような場合ですね。
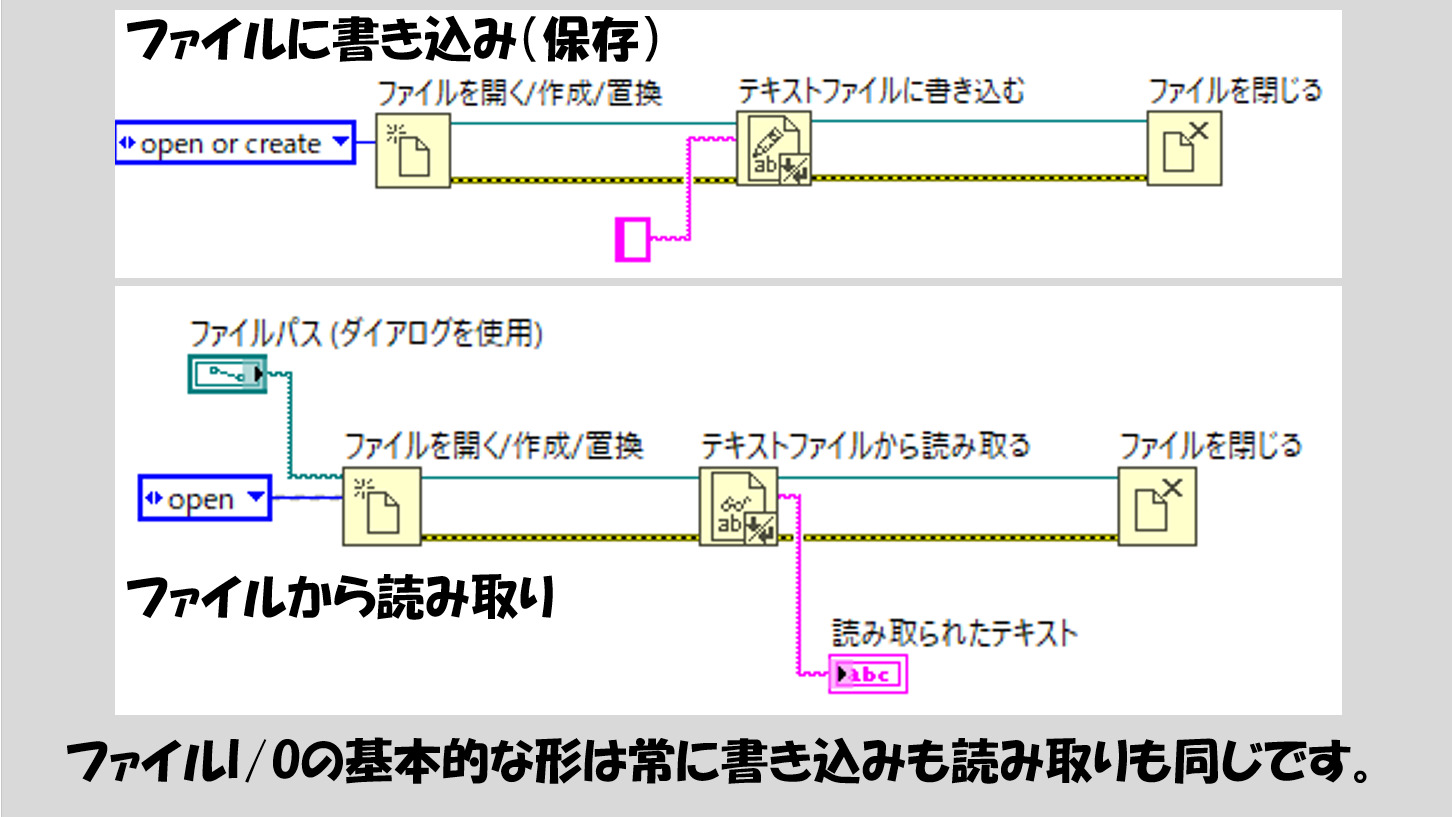
基本的な操作としてはファイルに書き込むときと同様、ファイルを開いて、読み取って、閉じるの関数を数珠繋ぎにするだけです。
せっかくなので、一番最初の画像のように、csvファイルの中のデータを読み出してLabVIEWで表示させる部分の流れを元にもう少し詳しくプログラムの流れを見ていきます。
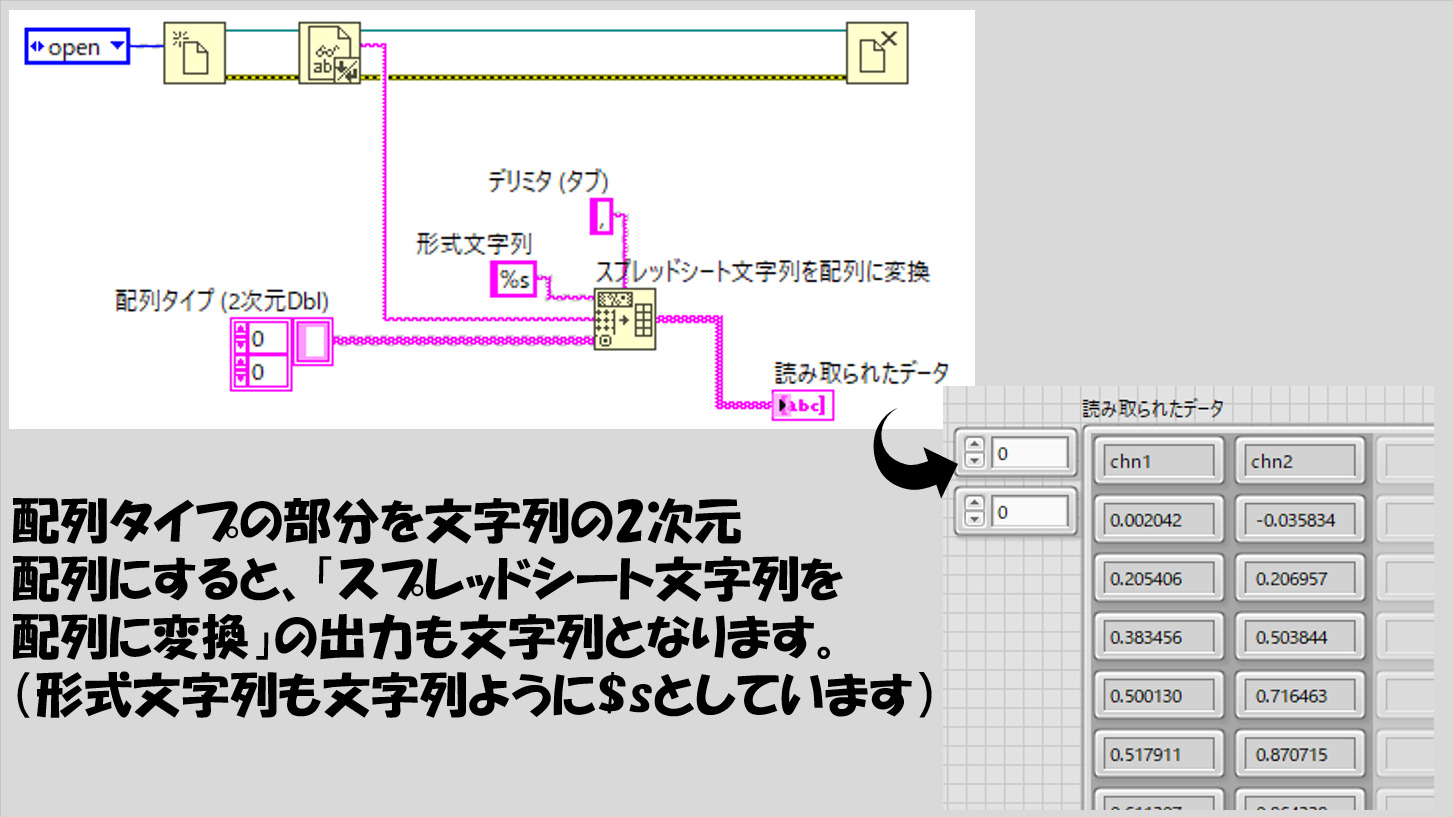
もちろんファイルの種類に依るのですが、例えばcsvファイル中に何チャンネル分かのデータが入っていた場合、読み取ったデータは配列として扱えた方が便利だと思います。今回の例も、2チャンネル分のデータがそれぞれの列に保存されている状態です。
読み取ったデータは、「スプレッドシート文字列を配列に変換」関数を使用することでcsvで保存されていた通りの並びで配列に変換することができます。
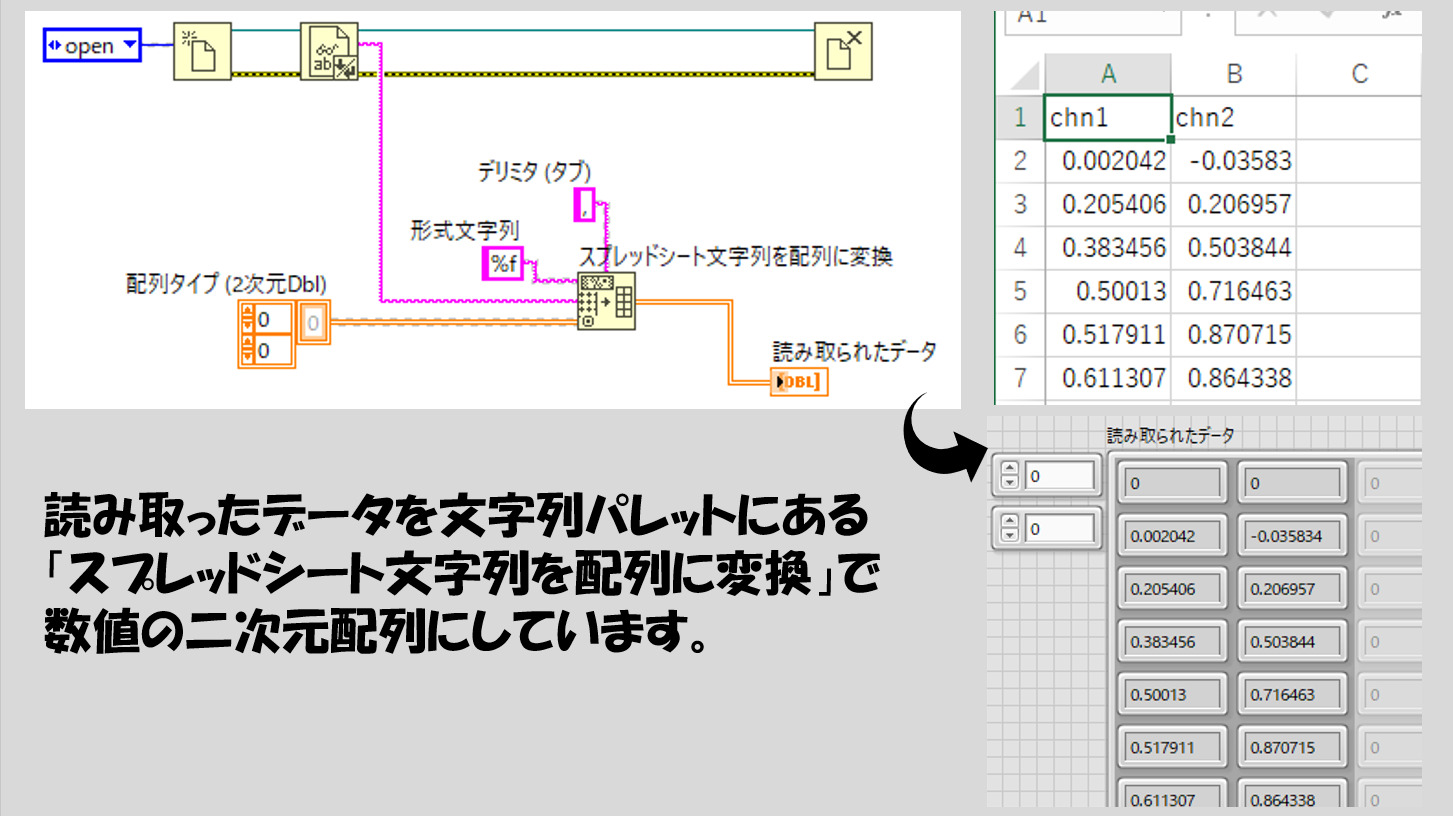
「スプレッドシート文字列を配列に変換」関数では、読みとりの際のデリミタを指定しています。ここで指定された区切り文字によって、読みとったファイルの中のデータをそれぞれの配列の要素として区分していることになります。csvはcommna separated valuesの略なのでデリミタはカンマ「,」ですね。
例えば読み取る対象のファイルが、一つ一つのデータの区切りをスペースにしているならデリミタにはスペース定数を、区切りをタブにしているならデリミタにはタブ定数を配線する、といった具合です。
また、形式文字列は細かい決まりはあるのですが、とりあえず数値として読み取るのであれば%fとしておけばいいです。(形式文字列の種類はこのほかにもたくさんあります)
さて、もともとのcsvファイルの中身と、LabVIEWで読み取ったデータ、一か所違うところがありますね。最初の行です。
今回例に出しているcsvファイルでは、ヘッダ情報としてチャンネル名(chn1、chn2)があります。ところが読み取られたデータにはこれがありません。それもそのはず、読み取られたデータは数値で指定して読んでいるため、数値ではないchn1というデータは正しく変換されていないのです。
もしこのヘッダ情報も読み取る場合には、最初文字列として読み込む必要があります。
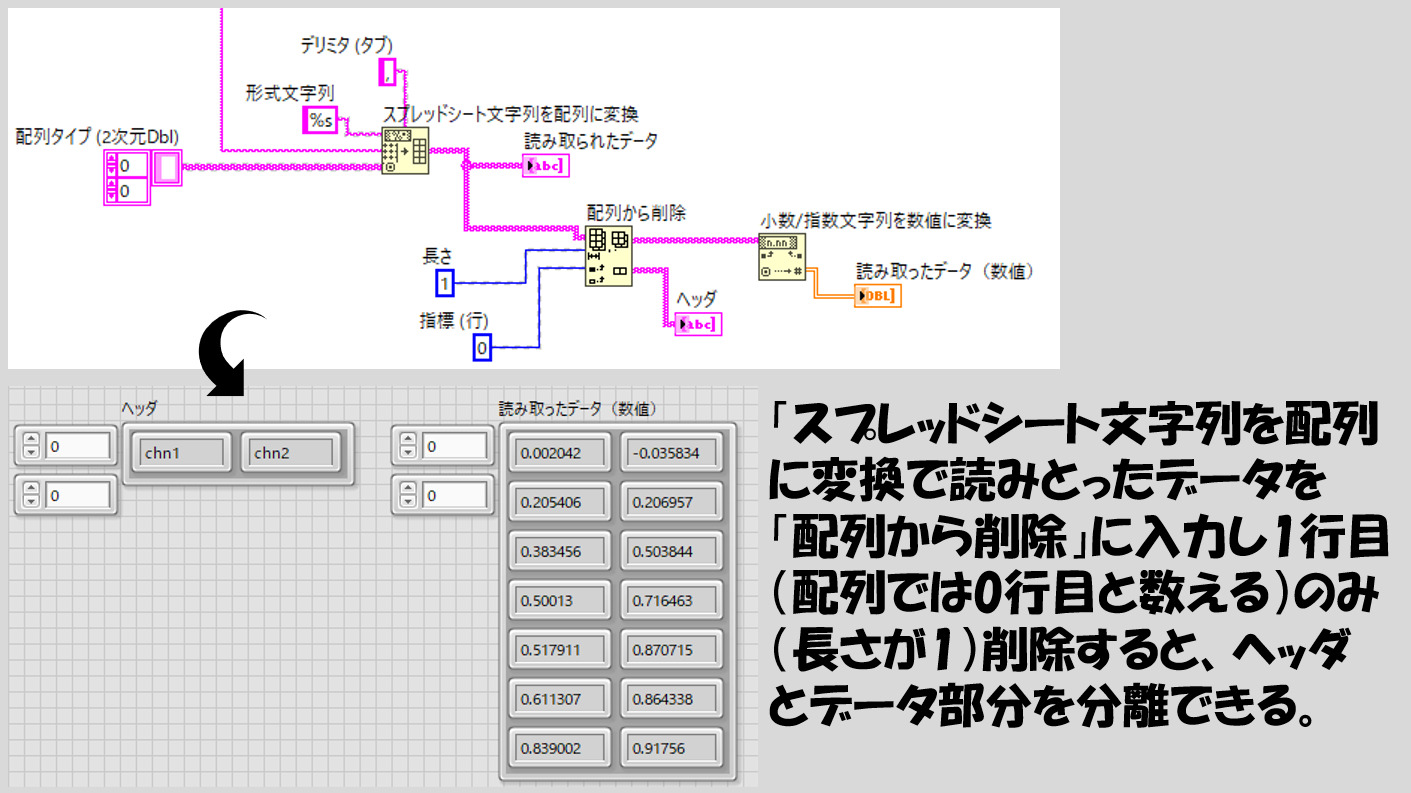
ヘッダの情報は、例えば後でグラフをプロットする際にプロット名にプログラム的にそのまま対応させることができます。しかし、別に必要ないということであれば、「スプレッドシート文字列を配列に変換」で最初から数値として読んでも構いません。(以降では、後々の説明のため、最初文字列として読み取った場合を例にとります)
どちらにしても、読み込めた後はもう配列操作なので、そこからヘッダの情報を抜き出したり、目的の列の値だけを取り出すなどは配列の関数で行えます。
こうして読み取ったデータを必要に応じて適切な形に直し解析の関数に渡して処理を行うことができます。
本記事ではファイルから値を読み取る操作の説明を目的としているため、解析の方法については説明はしませんが、例えば最初の画像のような結果を得るにはどのようなプログラムになるかの例を一応載せておきます。(意味が分からない、知らない関数がある場合には無視していただいて構いません)

大量のデータを読み取る場合には
ただ、たまにとても大量のデータを読み込んで処理したいといった場合がありえるかなと思います。その大量のデータを一度にLabVIEW側で読み出し配列に変換するとメモリ不足のエラーが起こるため、工夫が必要になります。
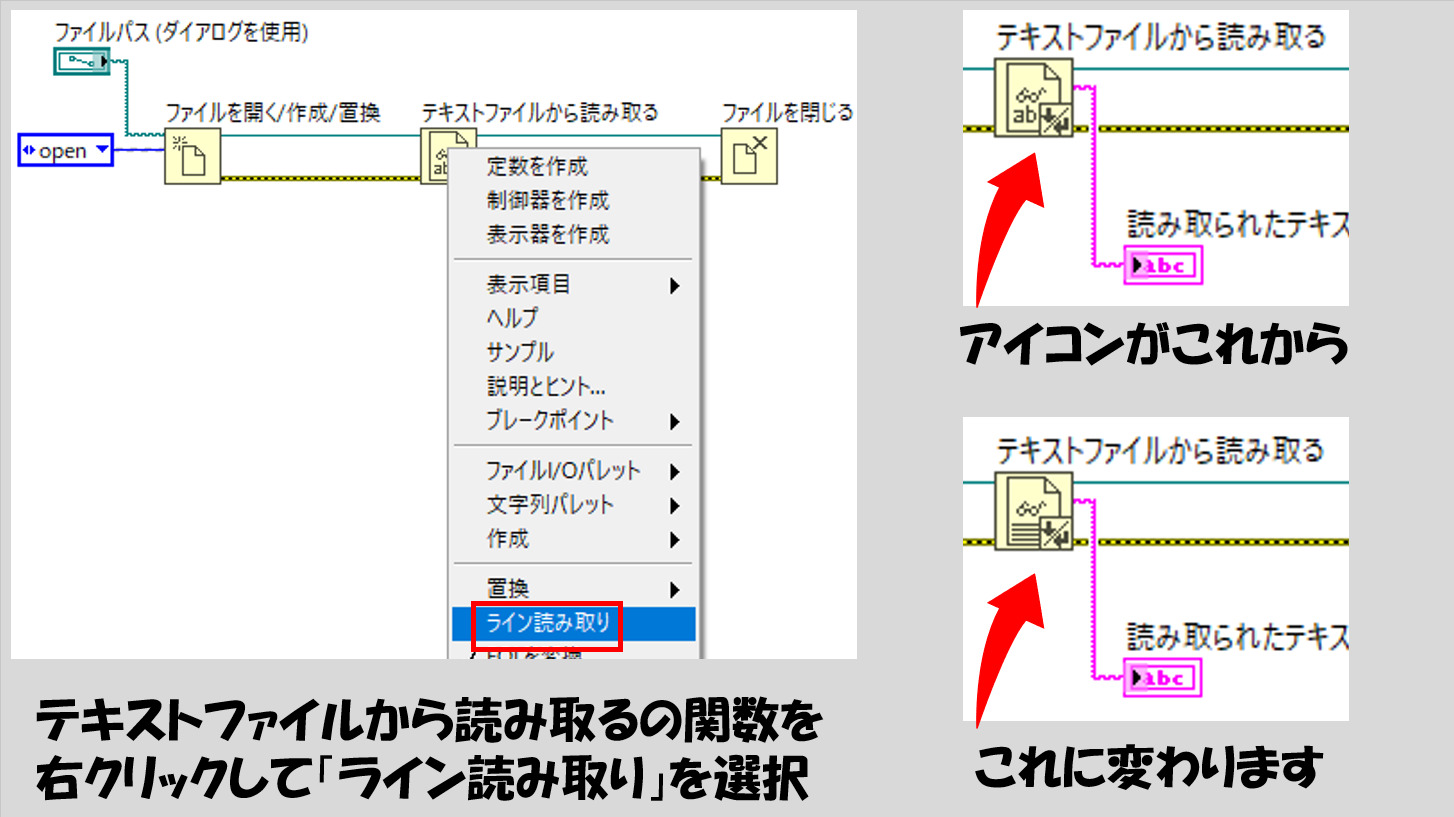
テキストファイルから読み取る関数の場合、1行ずつ読み取るということが可能です。そのため、処理の種類にもよりますが一行ずつ読んでいって目的の処理ができるようにする方法を考えなくてはいけないことがあります。
例えば、ファイルの中に入っている列方向のデータ全ての平均をとりたい場合にはこのようにすることができます。
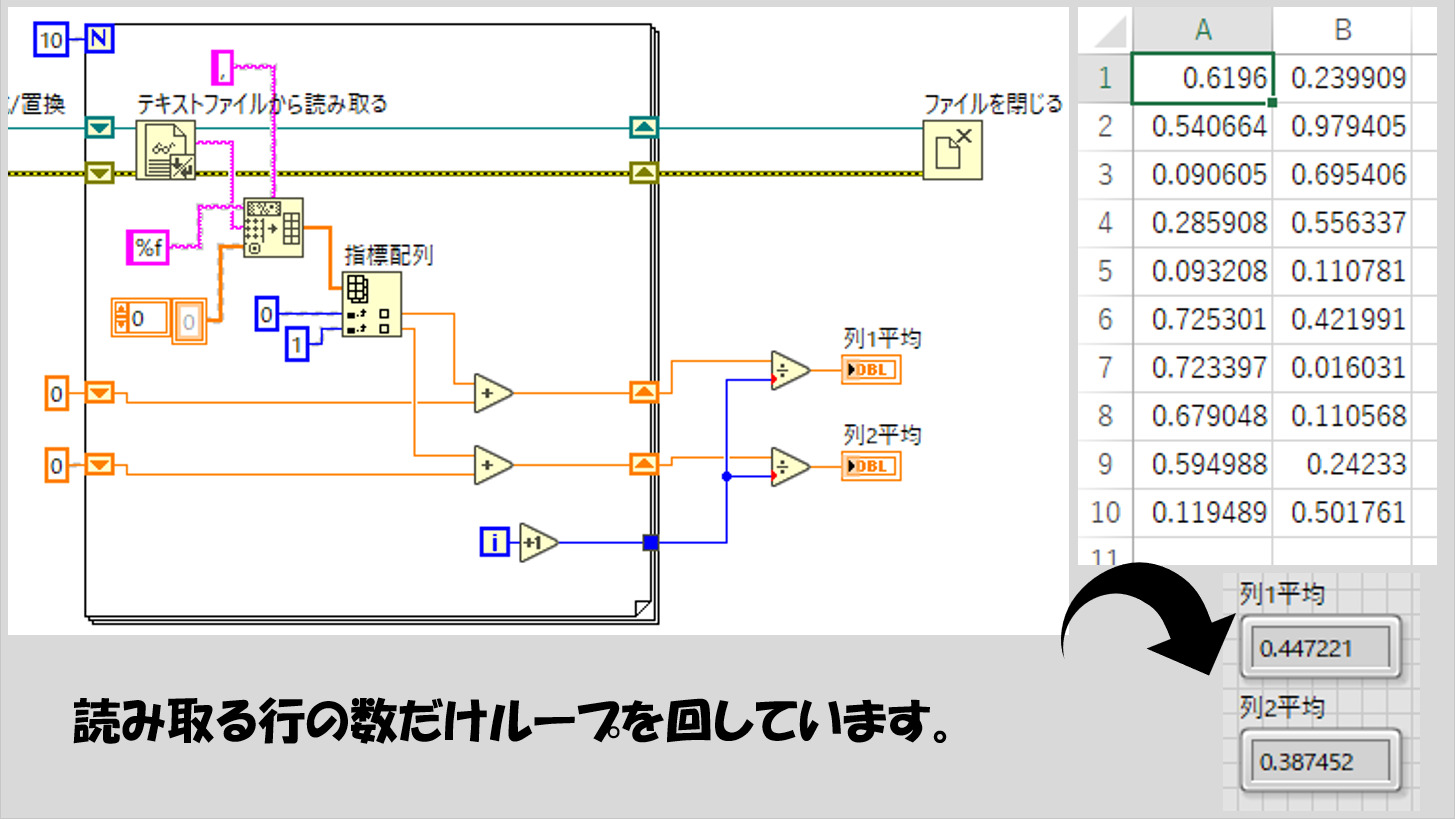
上の図は、結果との比較が分かりやすいように読み取るcsvの行数を10行と少なくしているのですが、何行であってもこの方法で読み取ることができます。
読み取る行数が分からない場合にはWhileループを使用して、読み取れる行がなくなったらファイルから読み取る関数がエラーを出すことを利用してWhileループを抜けるという組み方も考えられます。
ただしこの方法では、ファイルの最後の行の扱いによって読み取り行数のカウント(上記の例のカウント端子の結果)が1ずれることがあるため、平均を求めるような処理については不向きです。
特に行数を処理に使用せずに何行あるか分からないファイルから単に1行ずつ読み取るということであれば以下のようなイメージになります。
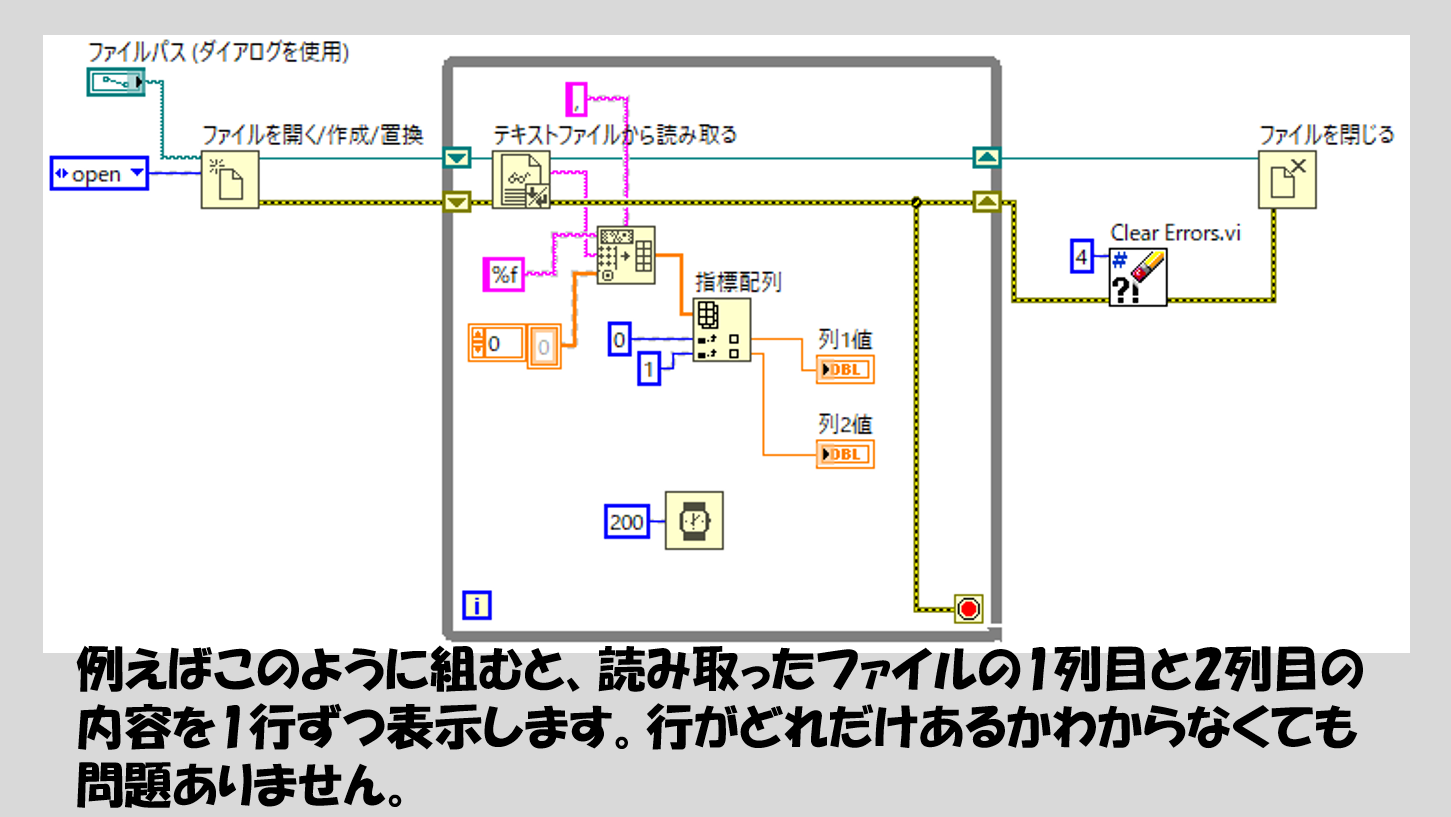
ループを出た後、エラークリアの関数を使用しています。この関数で、Whileループを止める要因となっていた、「もう読み取る行がないよ」というエラー(エラー番号4)をなかったことにしています。
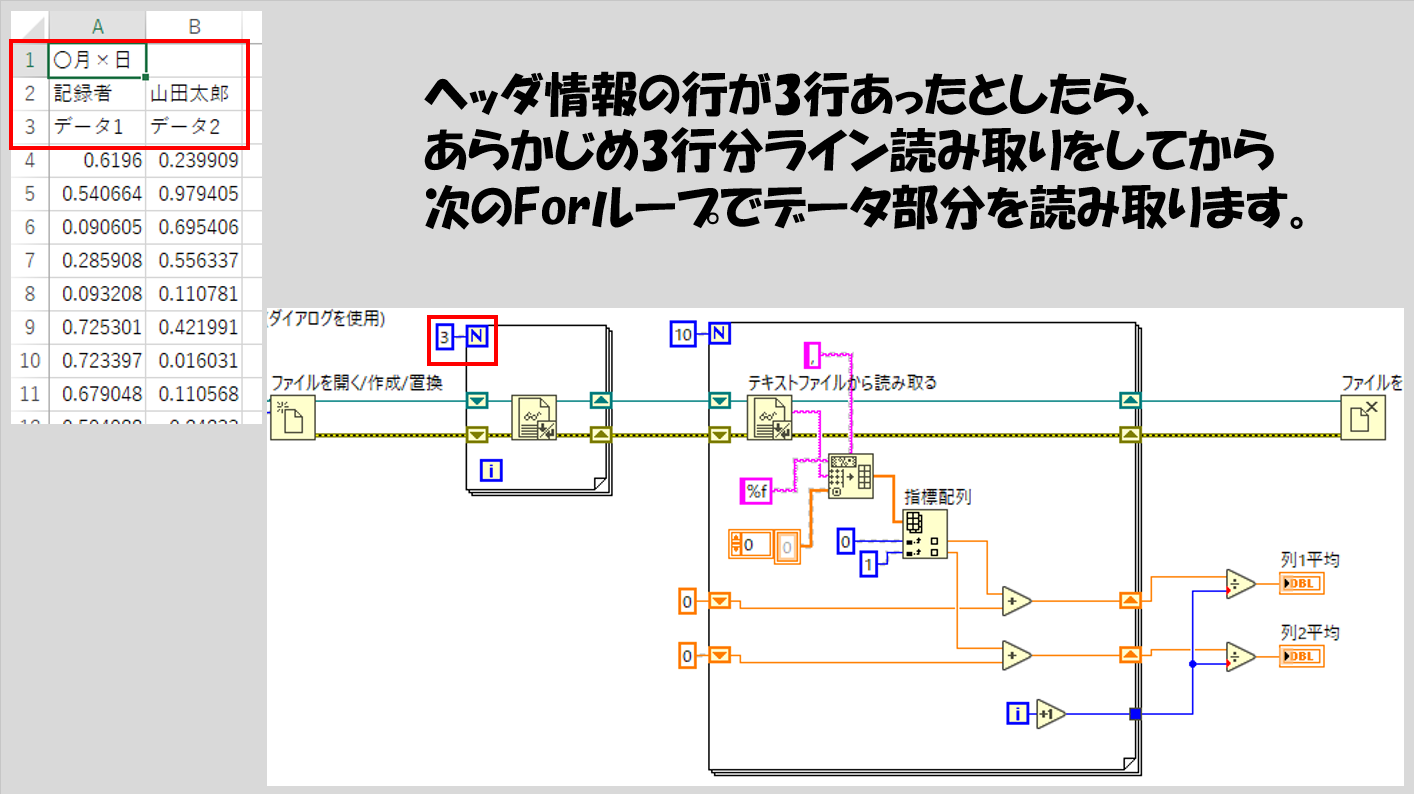
Forループを使用した例に戻りますが、上記の例はわざとヘッダ情報がないcsvファイルに対してのプログラムとしていました。
ヘッダ情報が複数行ある場合には、その分だけForループの前でライン読み取りをする方法が考えられます。ほとんどの場合、ヘッダ情報は何行入っているかはわかっているため、この部分にもForループを使用します。
ファイルからデータを読み出す方法は他にもあります。「区切られたスプレッドシートを読み取る」や「計測ファイルから読み取る」関数ですね。あれらは手軽といえば手軽ですが、カスタマイズがしにくくなっています。
ファイルの読み書き、どちらも似たような構造のプログラムで書けるので、この記事で上げたような使い方をまずは覚えれば、基本的な操作としては十分だと思います。
ここまで読んでいただきありがとうございました。
コメント