この記事は、初心者向けのまずこれシリーズ第9回の補足記事です。大きなサイズの配列を扱うプログラムを作る必要がある、という方向けにもう少し内容を補足しています。

※ただし、説明の都合上、ループ処理やグラフについて知っているとより役立てていただけるかもしれない内容になっています。
配列はある一種のデータタイプのデータを複数まとめて扱うのに便利なデータタイプでした。配列の配列は作成できないものの、他の多くのデータタイプをまとめて扱えるので、繰り返した処理の内容を残しておいたりするのに役立ちます。
しかし、際限なくデータをためられるかというとそうではなく、LabVIEWが使用できるメモリのサイズにも制限があるため、プログラムの書き方に注意を要する場面も出てきます。
この記事では大きなサイズのプログラムを扱う上での注意点と対応の一例を紹介しています。
LabVIEWがメモリ不足となる
LabVIEWはメモリの使用量に上限があるため、あまり大きなデータセットをプログラムの中で多用しているとメモリ不足のエラーが起きてLabVIEW自体が終了してしまったり、動作が遅くなったりします。
日本語のLabVIEWを使用している場合、これはつまり32 bitのLabVIEWのことですが、この場合にはPCの設定を変えたとしても3 GBまでしかLabVIEWは使用することができないようです。
特に気を付けなければいけないのが配列で、配列連結追加など使用している場合には特に注意が必要です。
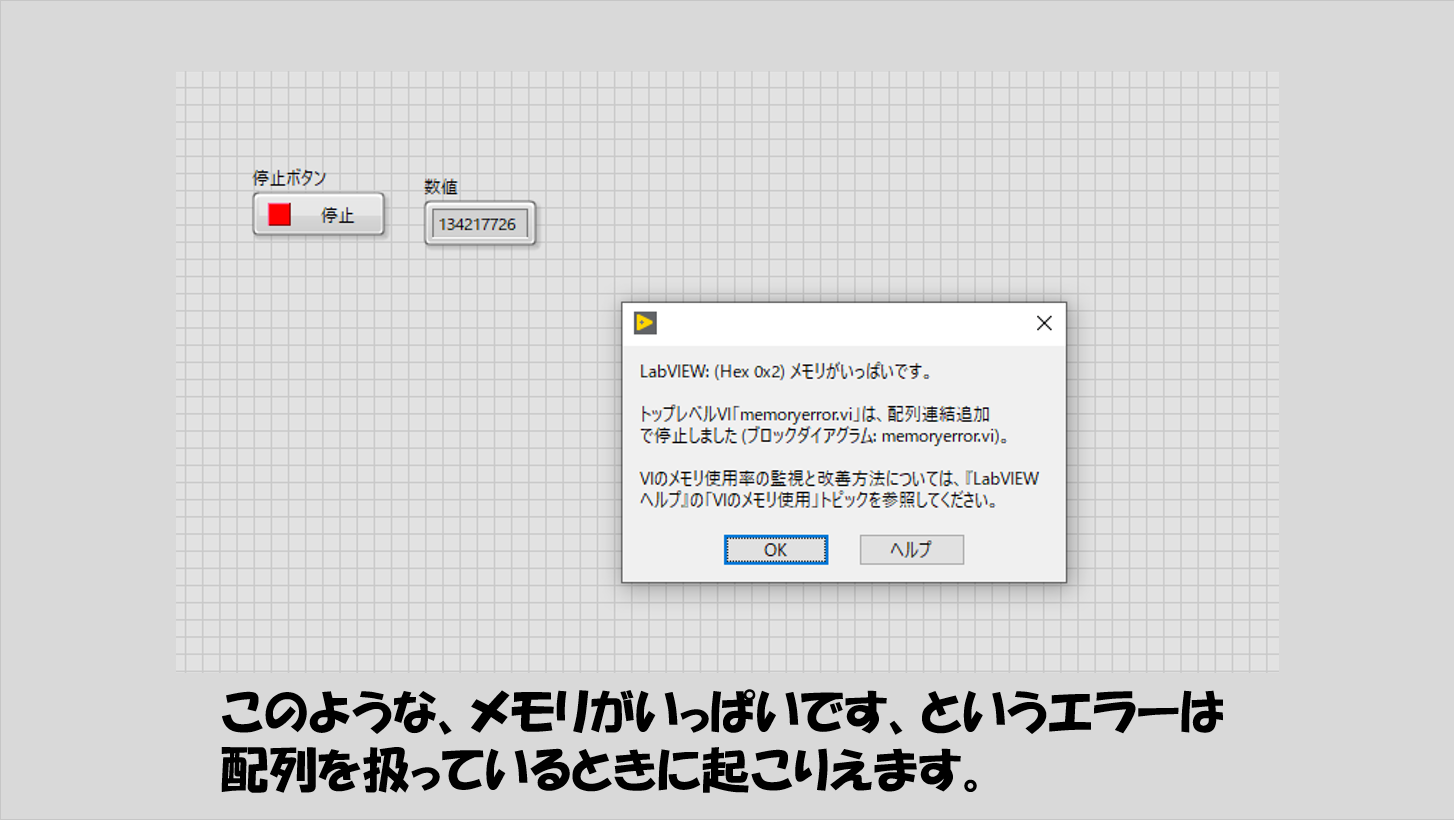
そもそもループの中で配列連結追加を使用するのが良くないとされていますが、その理由は配列連結追加を行うたびに新たな大きさの配列を確保しなければいけないことにあるようです。
例えば配列連結追加のように入力と出力で大きさが異なる配列となる場合、LabVIEWとしては出力配列用に新たなメモリ領域を確保する必要が出ます。言い換えれば、入力配列用の領域を使いまわすことができない、ということですね。そのメモリ領域を確保するのに時間をとられることも考えられます。
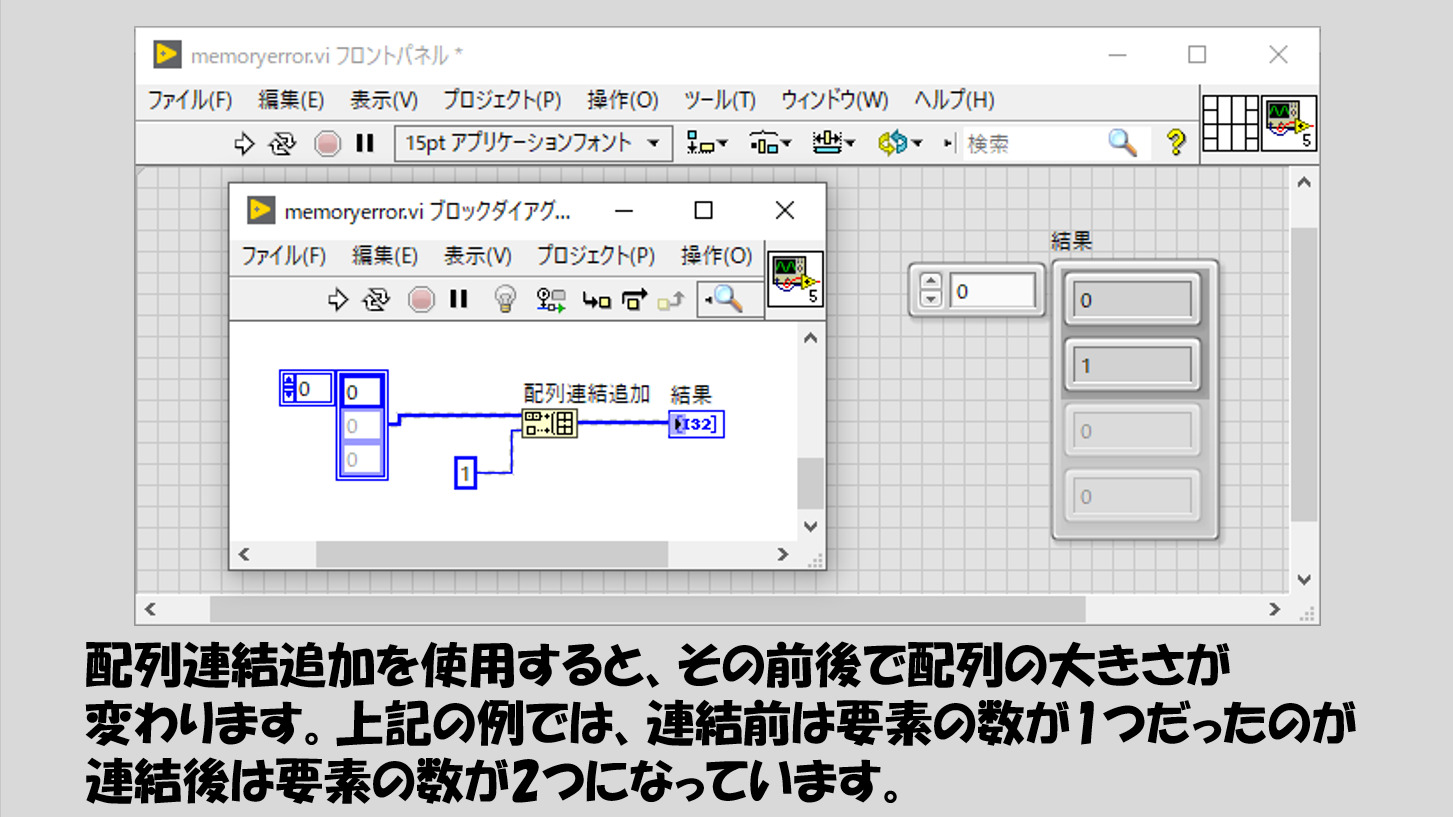
[配列連結追加の前後で配列のサイズが増えることを説明する図]
逆に言えば、使いまわせるような構造に書き換えればこの弱点はなくなると考えられます。
配列を使いまわす
なので、この弱点を克服するために、初めから欲しい配列の大きさ分メモリを確保しておき、その配列に対して実際に配列に入れたい値を置換する方法が有効になります。
こうすると、配列は毎回同じサイズとなるので、LabVIEWは新しいメモリ領域を確保しなくてよくなり、プログラムの動作も早くなります。
考えられるプログラムの一例を載せます。

このように、最初配列初期化で望みの大きさの配列を確保しておいて、実際の値とは配列置換の関数で置換します。
なお、上記の例ではNaNという要素の配列をあらかじめ作っています。このNaNはNot a numberの略で、データタイプとしては数値なのですが、具体的に何か0とか2とか97とか意味のある数字を表わしません。
これの何がいいかというと、グラフに表したりする際にプロット点としては認識されなくなる点です。この辺りは、グラフの使い方が分かってくると意味が分かるようになるかなと思います。まずこれシリーズでまだグラフについては見ていない場合には、とりあえずこんな書き方があるんだということを覚えておけばいいと思います。(グラフについては以下の記事で扱っています)
また、繰り返し処理を既に知っている場合には、ループの反復端子などを用いて置換する場所をずらし、商&余りの関数を用いてやることで古いデータから順に更新していくといった、循環型の配列の使用もできるようになります。
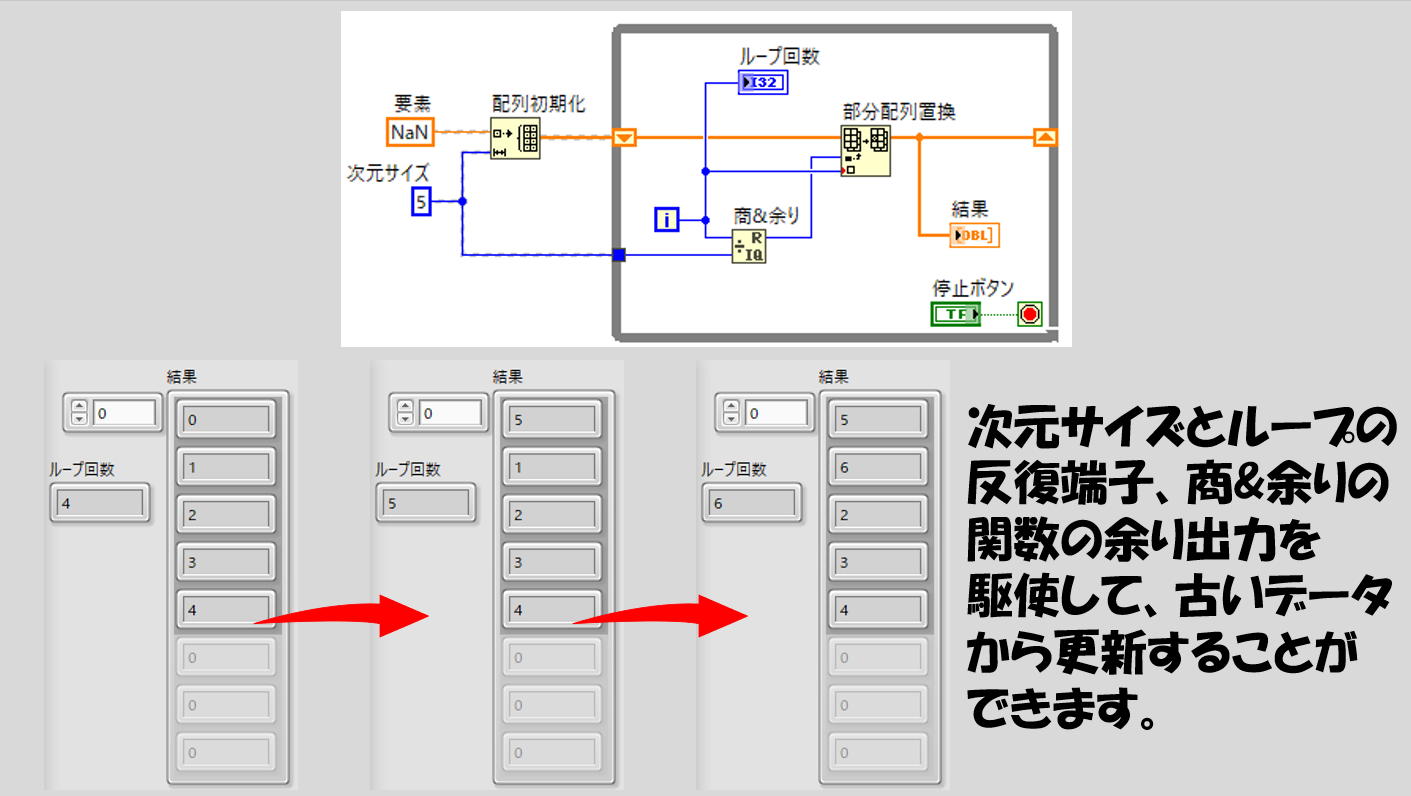
配列の中の要素の順番も大切なんだ、という場合には別の工夫をする必要がありますが、順番は関係ない、あるいは毎回ある一定数のサイズの要素がたまったらごそっとその配列を処理する(その一定数が毎回溜まる時点でその時点での配列の要素はすべて新しい要素しかない状態)という場面では上記の方法が便利です。
処理速度にも注目する
プログラムの動作が早くなると書きましたが、実際に配列連結追加を使用した場合と配列初期化で配列を用意しておいてから置換する方法ではプログラムの実行速度にも明らかに違いが出ます。
配列連結追加を使用した場合と、用意した配列を置換する方法で実行速度を比べてみる以下のようなプログラムを組んだとします。
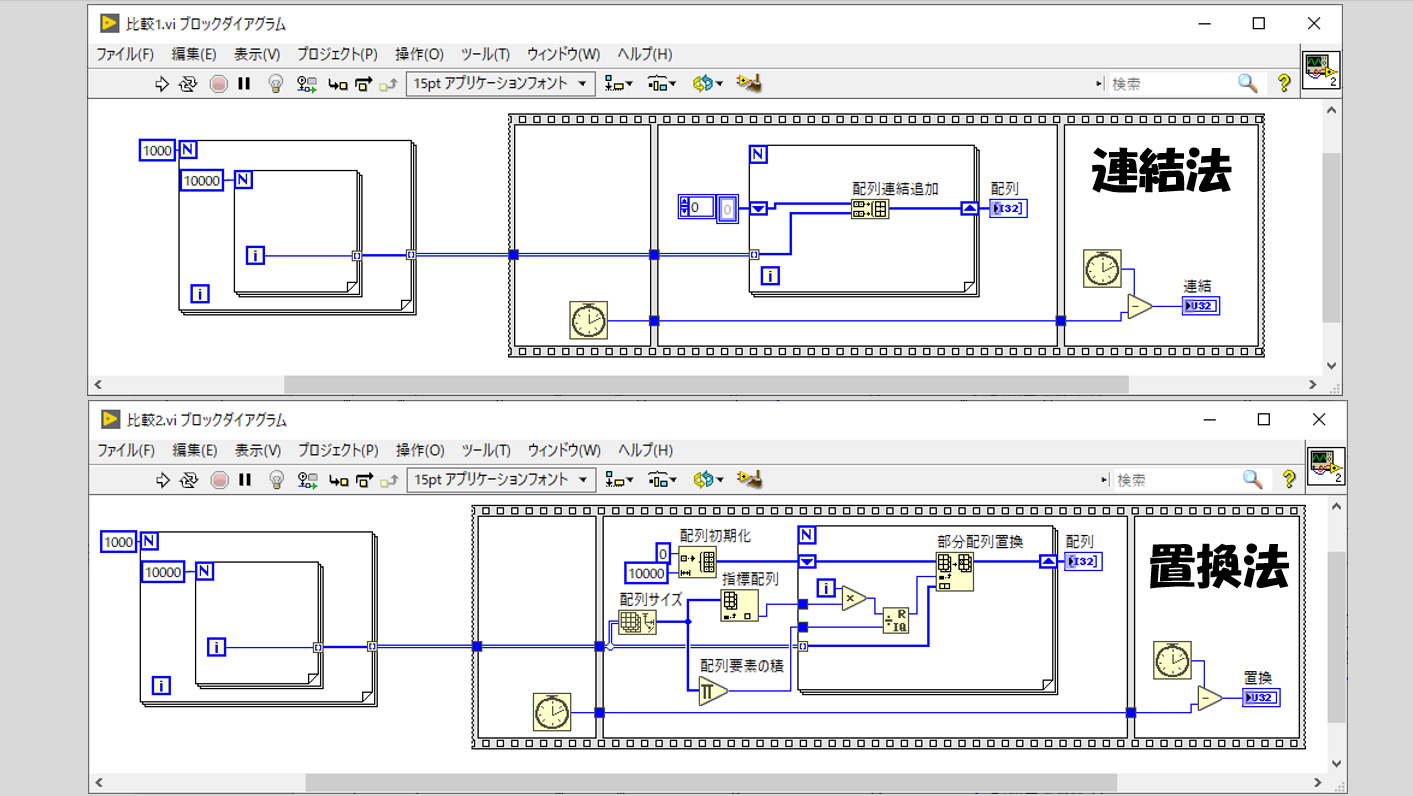
このプログラムは、ストップウォッチのようなティックカウントと呼ばれる関数を使用して対象のコードの処理時間を測るものとなっています。対象のコード、とはそれぞれのフラットシーケンスストラクチャ(映画のフィルムのような、枠が3つあるもののこと)の真ん中に来ているものですね。
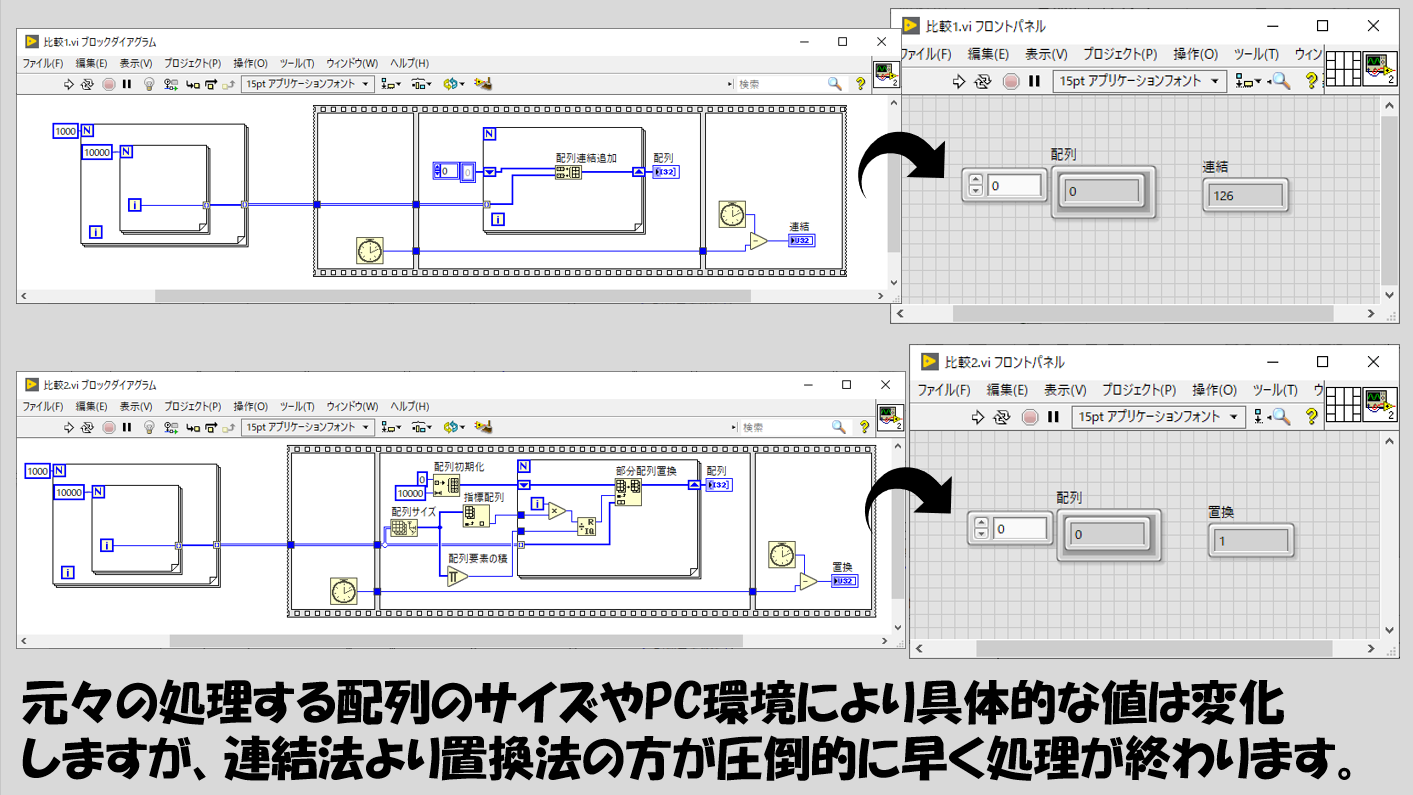
二つの方法はどちらも最終的には同じ結果を得ます。これらのプログラムを実行すると、配列を置換する方法は圧倒的に早く終わることがわかります。
もちろん、元々の配列の大きさや使用PCの負荷の状況などで具体的な値は実行の度まちまちになりますが、それでも置換法は圧倒的に早いです。
ただ、上のプログラムを見てもわかる通り、置換する方法は得てして配列連結追加を一つ使う方法よりも(見た目は)複雑になりがちです。
延々とプログラムを繰り返さないことがわかっている状態でかつプログラムの実装をシンプルにしたいということであれば配列連結追加を気をつけて使うのでもいいと思うのですが、その場合でも工夫の仕方で処理速度が変わるので最後にその例を紹介します。
何のことはない、配列連結追加の連結の仕方の順番についてなのですが、新しい要素を下に追加するのか、上に追加するのかで処理時間がこれまた大きく変わります。
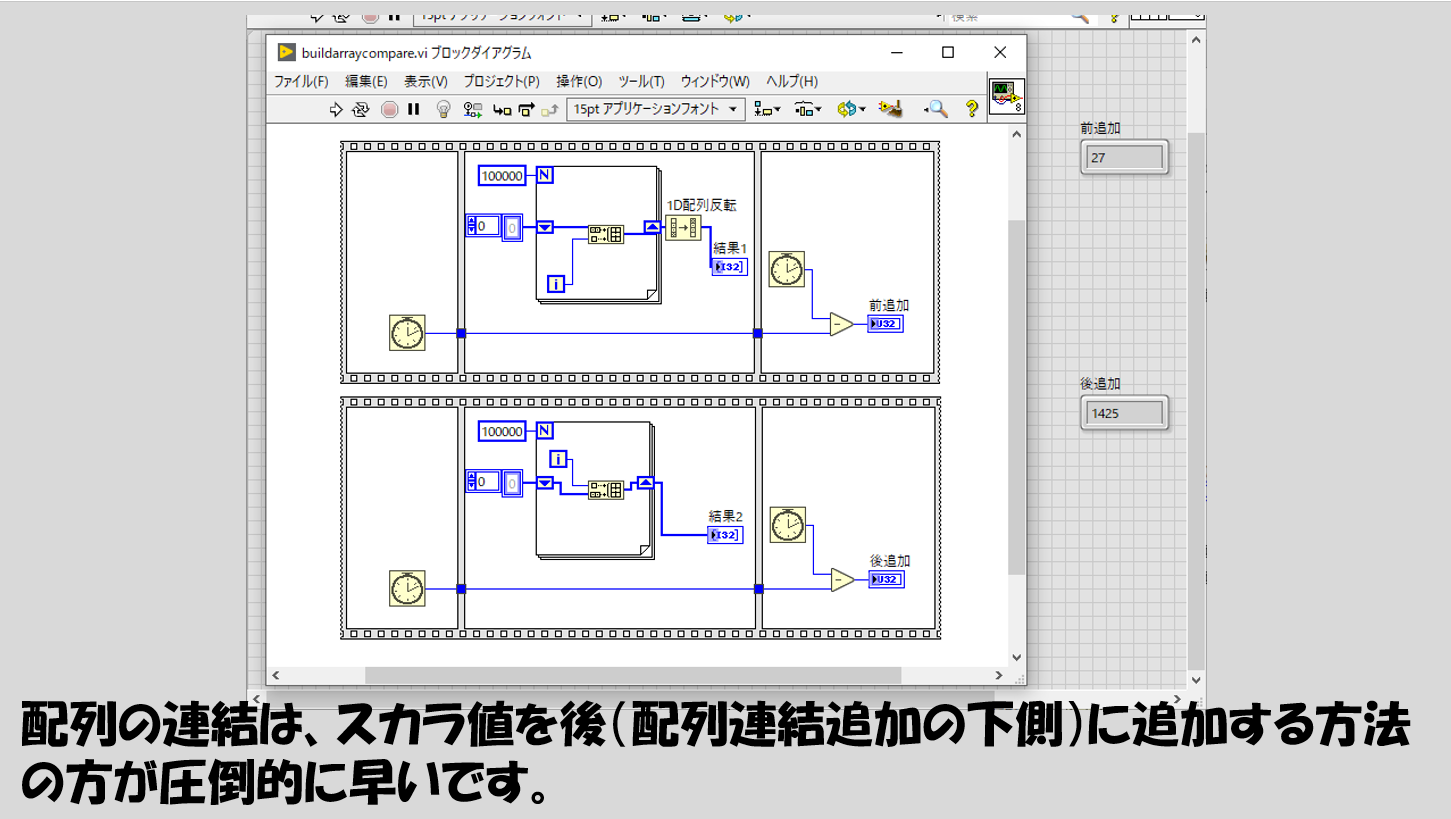
上のプログラムの実際の流れはForループやシフトレジスタの意味がわかっていないと理解できないですが、結果1と結果2はどちらも同じ結果となります。ですが、処理にかかる時間は、新しい要素を下に追加する組み方の方が圧倒的に早いことが分かります。
LabVIEWのプログラムで、組み方によって劇的に処理速度が変わるワザの中でもこれは知っていると知らないとで大違いなので、ぜひ今後参考にしてみてください。
配列初期化でメモリ領域を用意しておくことの弱点としては、用意したメモリサイズが上限となることです。とはいえ、あるプログラムを組んだ際に、際限なくデータを増やしたいという場面はそんなになく、「この部分の配列はこれくらいのサイズの配列だ」ということが予想がつく場合が多いと思います。
とにかく、配列を用意しておいて置換するという組み方はメモリの使い過ぎを防ぐだけでなく、実行速度にも明らかな差を生むことになるため、何かプログラムで配列を使いまわせるような場面があったら工夫して使いまわせないか意識してみることで効率を上げられるので、そういったことも意識してプログラムを書くことを心掛けられるといいと思います。
そしてもし今回の記事で「繰り返しってなんだ?」「シフトレジスタってどういうもの?」という疑問が出たら、ぜひ以下の記事も読んでもらえると嬉しいです。
ここまで読んでいただきありがとうございました。
コメント