LabVIEWを触ったことがない方に向けて、それなりのプログラムが書けるようになるところまで基本的な事柄を解説していこうという試みです。
シリーズ9回目として複数のデータをまとまりで扱うために必要なデータタイプ、配列を見ていきます。
この記事は、以下のような方に向けて書いています。
- 配列って何?
- 配列って何に使うの?
- 配列の特徴を知りたい
もし上記のことに興味があるよ、という方には参考にして頂けるかもしれません。
なお、前回の記事はこちらです。
配列とは何かを知ろう
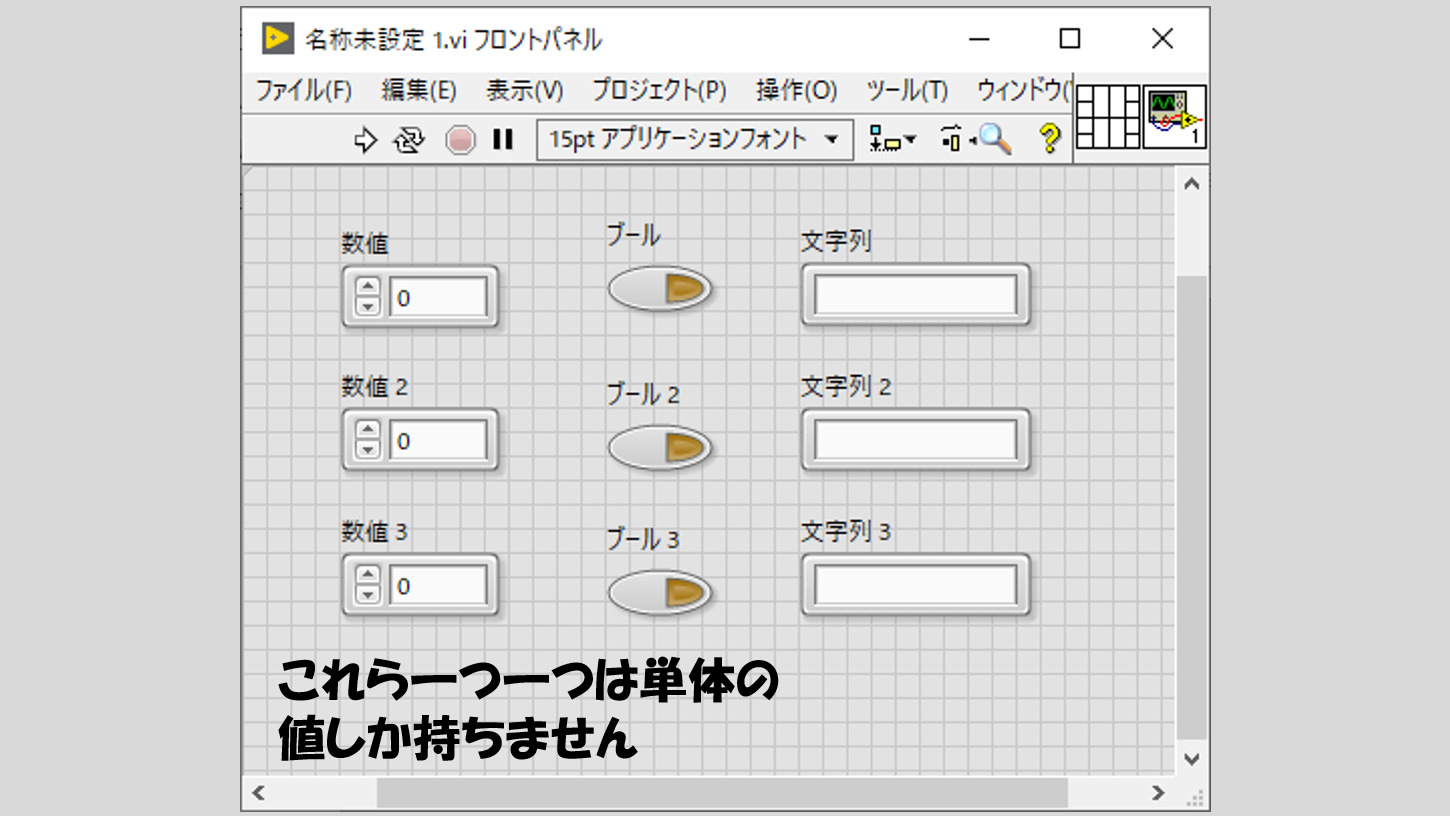
多くのプログラムは何かの処理を繰り返すという構造を持っています。そして処理を繰り返すということは、結果が複数得られるということになります。
これまでに扱ってきたデータタイプは、文字でも数値でもブールでも、単一の値しか持っていませんでした。では複数のデータを扱うにはどうすればいいか?そこで配列の登場です。
配列データタイプは数値、とか文字列、といったような「単純な」データタイプではなく、データのまとまりを表します。同じデータタイプのデータをひとまとまりに集めてそれらをまとめて管理しよう、というときに使用します。
そのため、データタイプごとに配列があります。「数値の配列」とか「文字列の配列」、といった具合です。
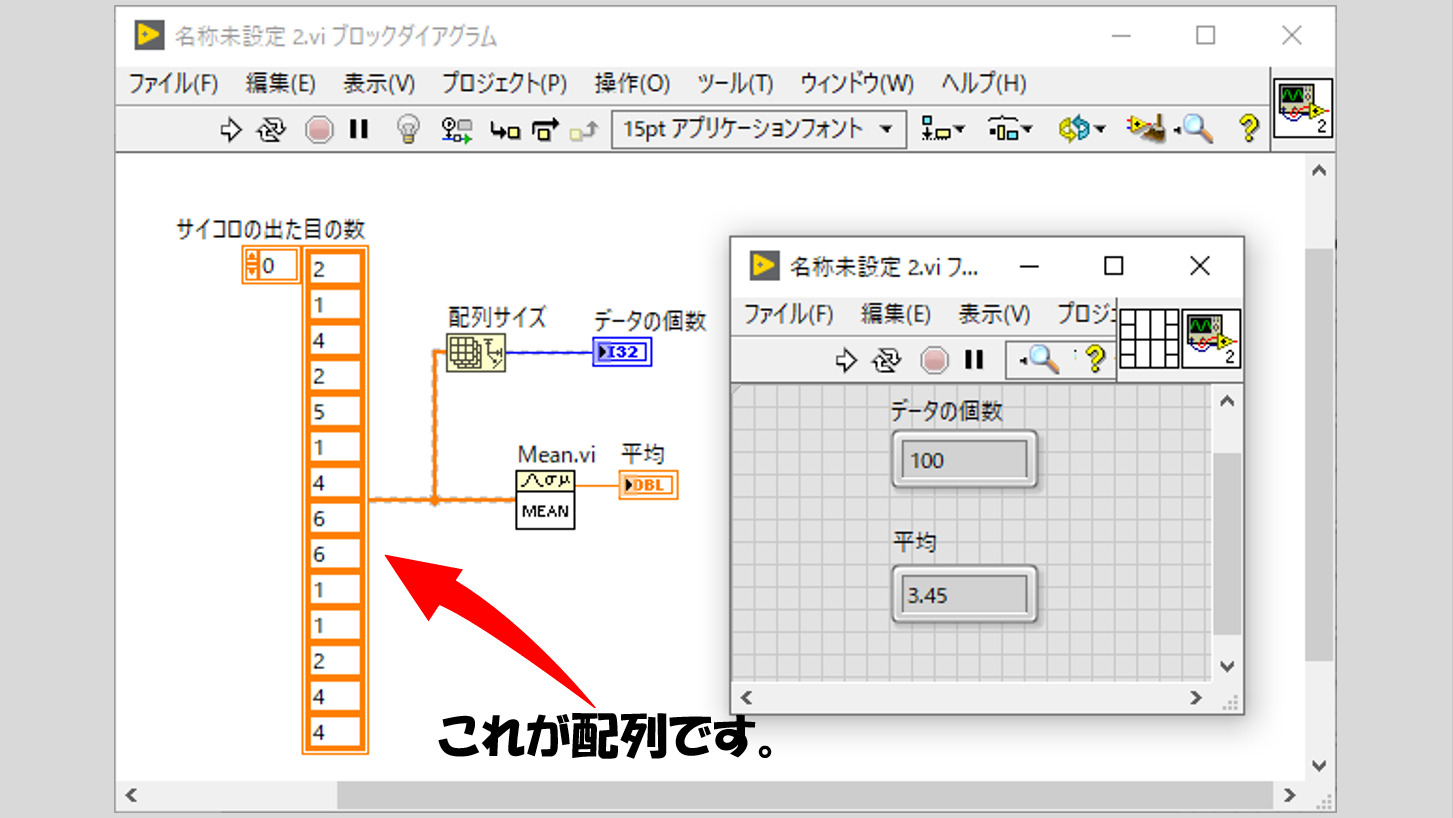
どのような時に使うか、もう少し具体的にイメージを持てた方が分かりやすいかと思うので、例えば数値のデータタイプで考えてみます。サイコロを振って、出た目の平均を出す、といったことを考えます。
このとき、平均を出す、といっているので例えば100回振ったのだとしたら、その100回分のデータを全て覚えておく必要がありますよね?

で、これらを合計して100で割れば平均が得られます。これをプログラムで行わせる場合であってもやはり100個の数値は残しておく必要があるのですが、それらの数値をどうやって管理するかが問題になります。
そんな時に配列の出番です。これらの数値をまとめてしまい、「数値の配列」に対して平均をとる関数があるので、その関数に配列を渡して平均を計算させる、といったイメージです。具体的なイメージをまずはお見せします。
当然、こんな例ではなくても、例えばデータを測定して得られた波形状のデータに対しFFTをかける、といったときにも配列を使用します。FFTをかけるにはその波形のデータのまとまりが必要であり、波形データは結局一つ一つの数値の集まりに過ぎないからですね。
こちらもイメージを下に示しています。
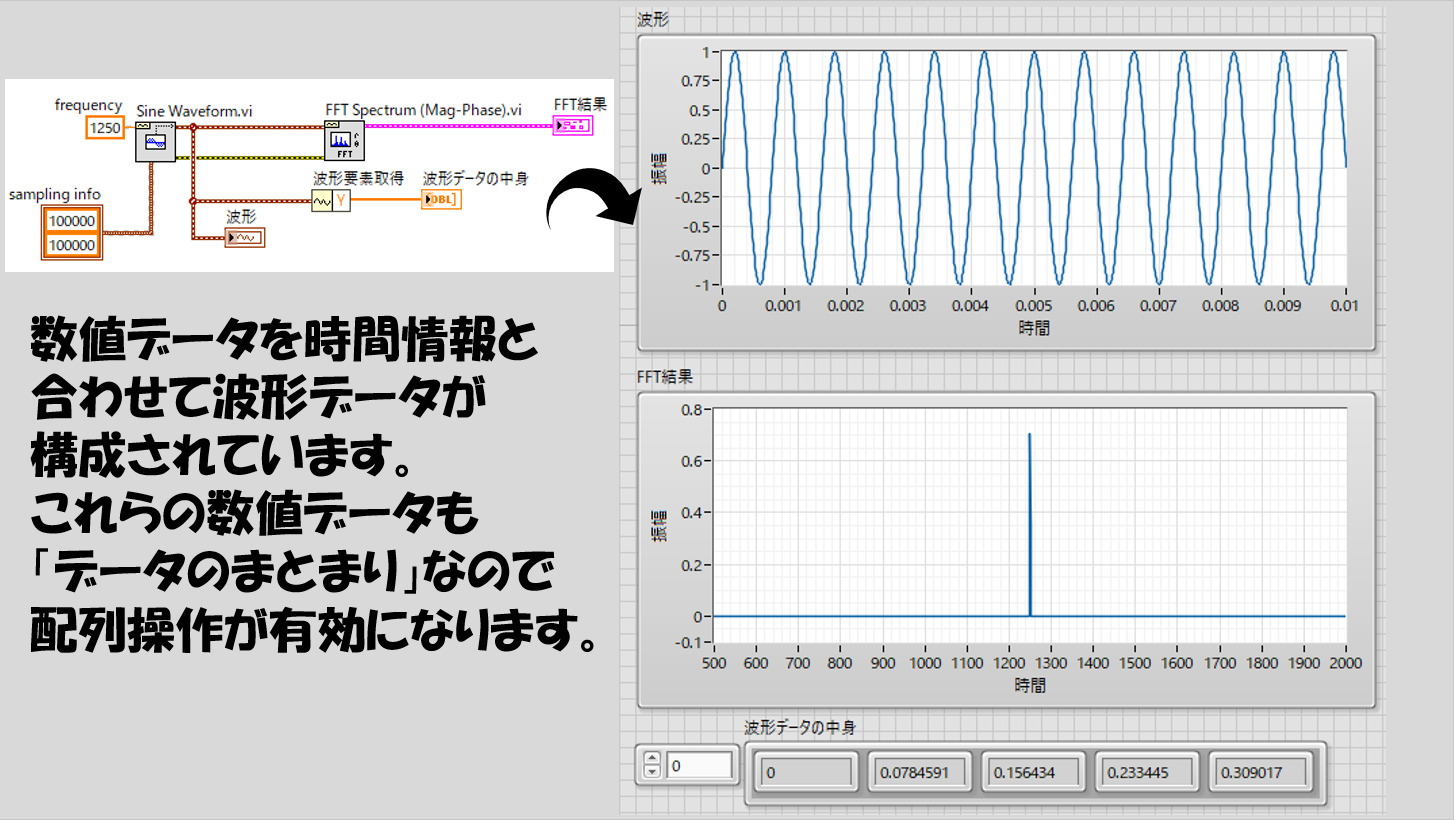
数値の例ばかり出していますが、どのようなデータタイプについても配列を使う場面は良く出てきます。
配列の作り方
さて、配列についてどんなものか、どういった場面で使用するか少しはイメージできたでしょうか?
配列に慣れるために今度は実際に配列を作ってみることにします。配列の作り方はどんなデータタイプでも共通なので、試しに数値(制御器の)配列を作ることを例にとります。
フロントパネルで、空の配列を用意します。次に、今回は数値の配列を作るので、数値制御器を一つ用意してこれをフロントパネル上に置きます。
置いたら、それをそのままドラッグアンドドロップで空の配列の部分に持っていくと、配列の枠組みが数値制御器を覆うように、内包した状態になります。これで数値(制御器の)配列の完成です。

他のデータタイプ、例えばブールや、文字列の配列も全く同じ作り方で用意できます。ブロックダイアグラムを見ると、配列はその中身のデータタイプの色になっています。

フロントパネル上で改めて数値の配列を見てみます。二つ数字が並んでいて、左側に0、右側にも0と書いてありますが、右側は少し暗い色になっています。左側に書かれた数値は指標番号と呼び、右側は要素と呼びます。
配列はたくさんのデータをひとまとまりにしているのですが、 例えば1000個のデータがまとまっていたとして、それらをフロントパネルにすべて表示するわけではありません。指標番号で「何番目のデータを表示させるか」を決めていて、その番号の具体的なデータが「要素」として表示されています。ただし、指標番号は0から数え始めます。
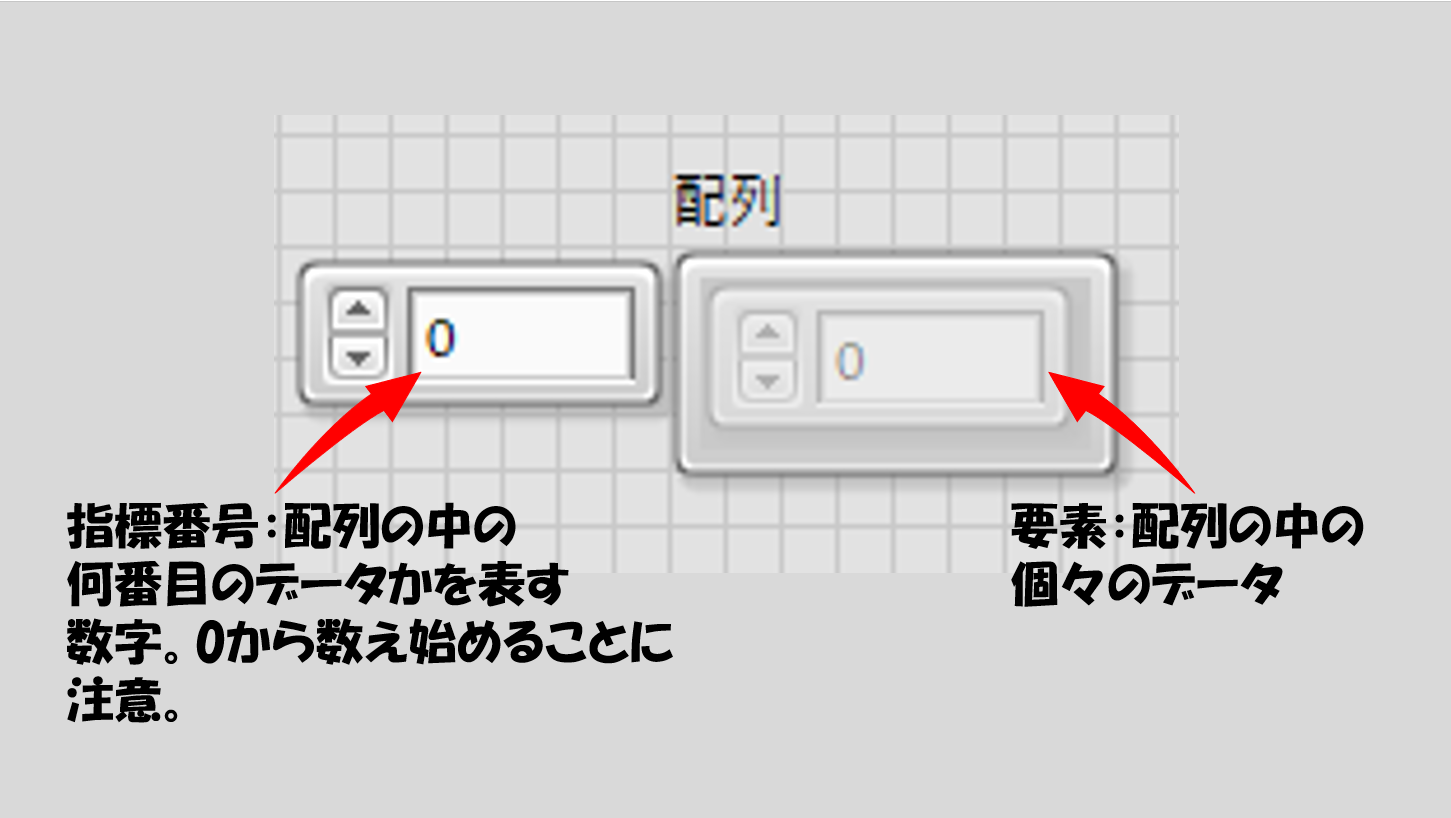
注意する必要があるのは、上の図で右側に表示されている0というのは「要素(としての値)が0」ということをまだ表していない、ということです。
要素がグレーの表示になっているのは、「ここに配列を付け加えられるけれどまだ要素として定義されていない状態ですよ」ということを表しています。
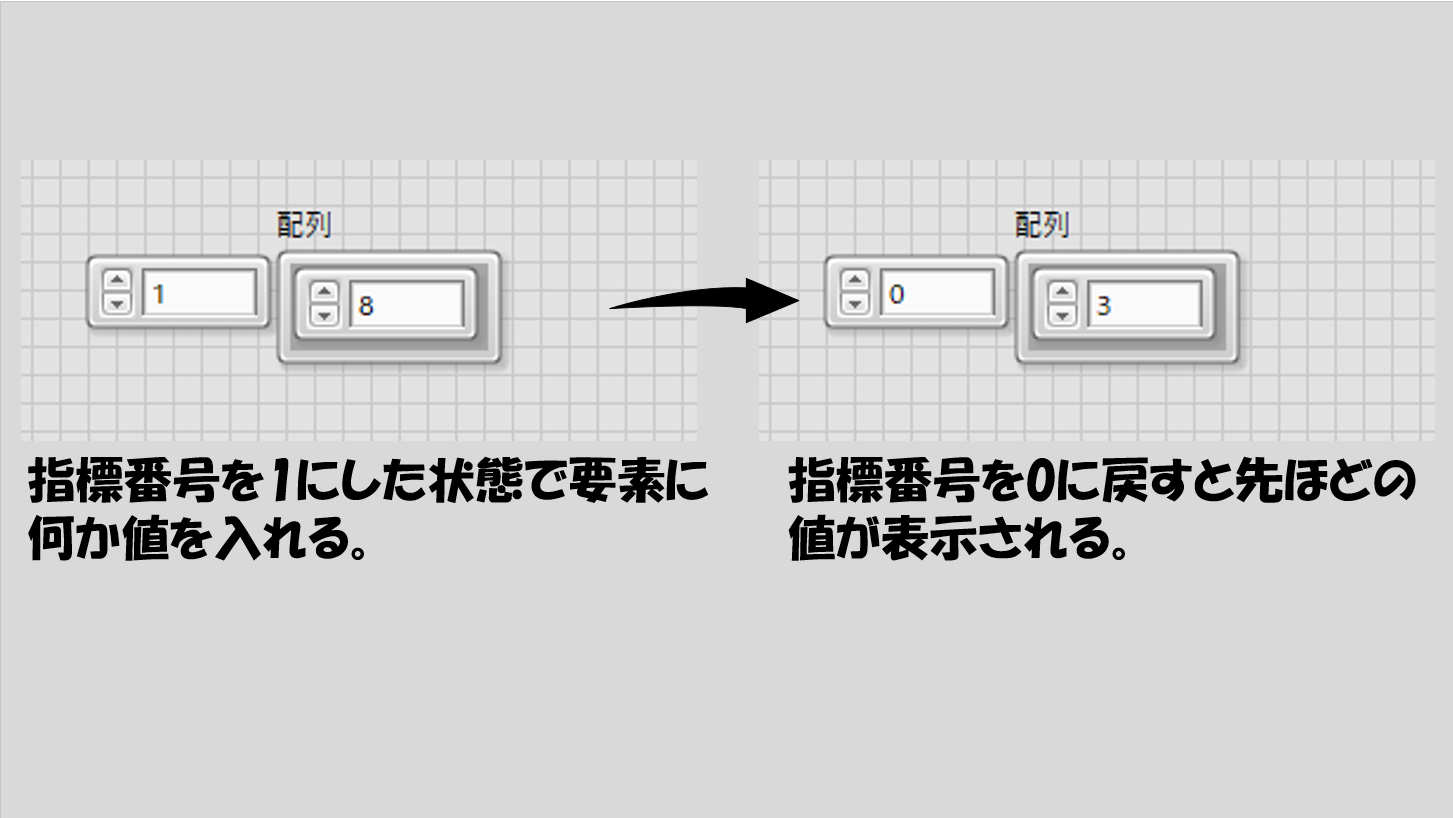
試しに、右側の0の部分をクリックして何か適当な数値を入れてみると、明るい色に変わります。この、明るい色になった状態を「初期化されている」(=値が定義されている)状態と呼んで、暗くなっている状態と区別します。
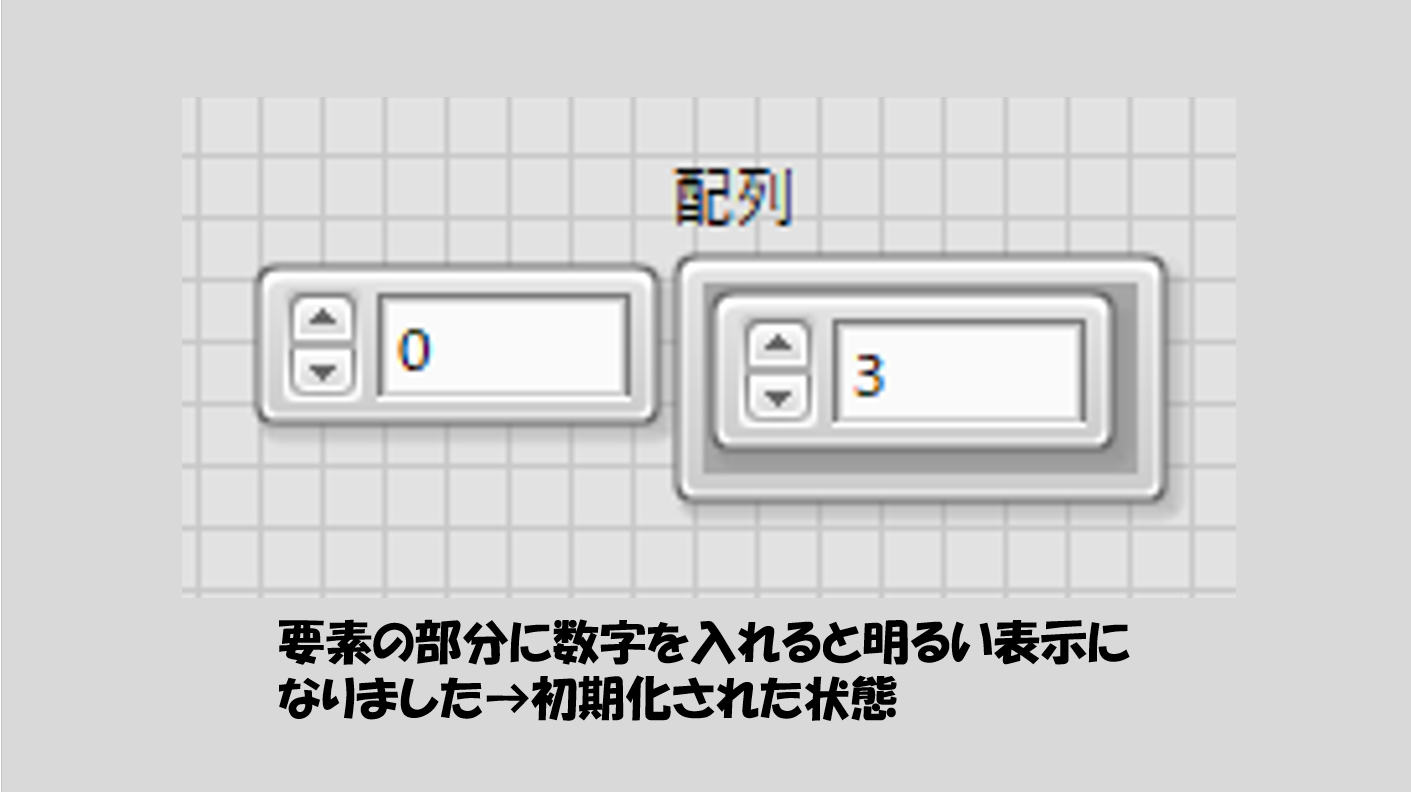
このとき、今入力した値は配列の要素になっています。左側に表示された0という数字が指標番号なので、上の図の例では「この配列の指標番号0の要素は3だ」と言えます。
指標番号を0から1にすると、また右側は暗い表示で0になっています。つまり「初期化されていない」状態ですね。言い換えると、この状態ではこの配列は要素を1つ(指標番号0の「3」という値)しか持っていない状態です。初期化された要素の数が、配列のサイズになるとも表現できます。
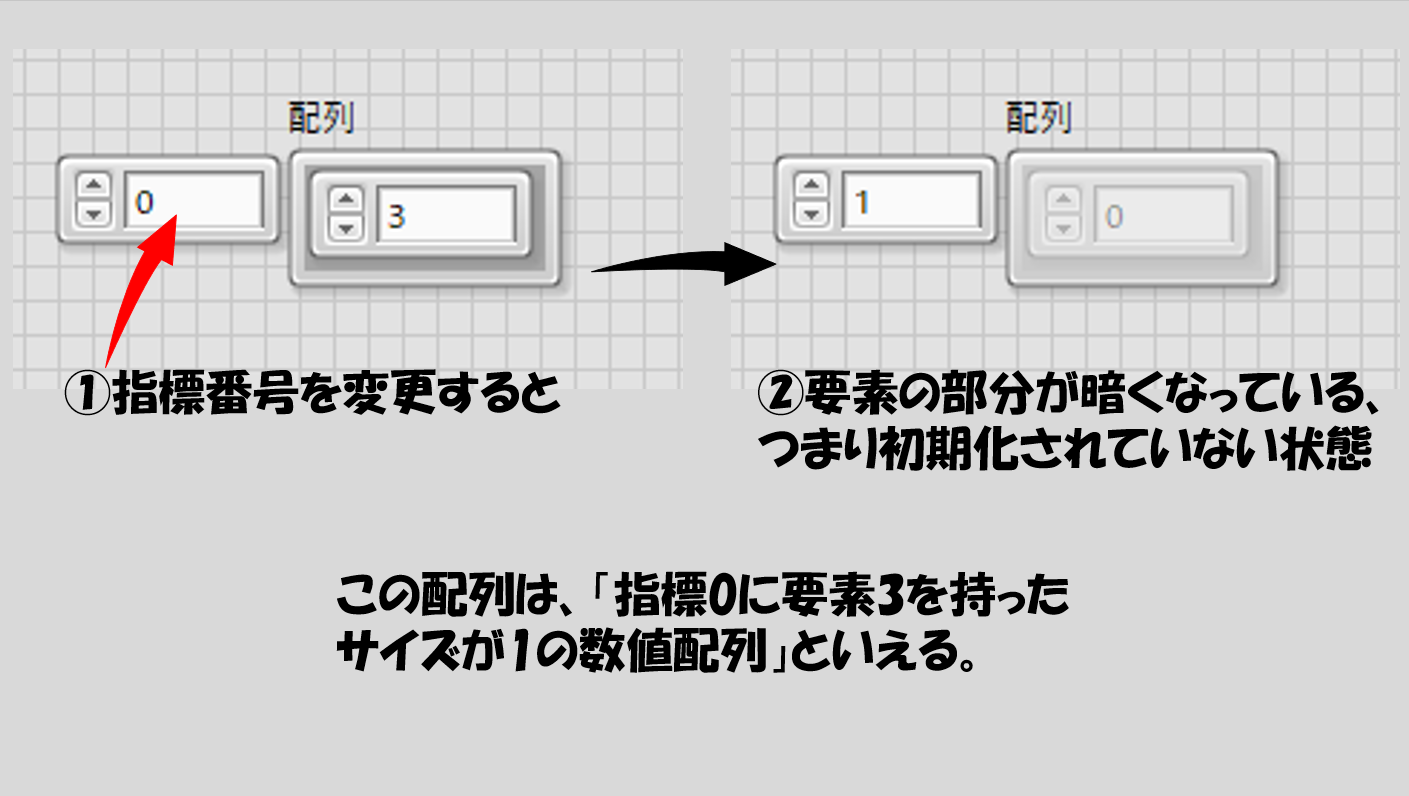
繰り返しになりますが、初期化されていない部分は、つまり要素がない状態です。なので、初期化されていない時に表示される0は、別に0という値の要素を持っているのではなく、単に数値が入りますよということを表している、という程度に思っていれば問題ないです。
この状態でまた右側に何か値を入れてみます。するとこれも明るい表示になって、サイズが2の配列を用意したことになります。
指標番号を0に戻すと、さっき入力した値が表れます。各指標の中の要素は独立(他の指標の要素に影響されない)していることがわかります。
ところで、この状態だと毎回指標番号を変えないと他の指標番号を見ることができません。フロントパネル上の枠が狭くて表示できる場所がない、という場合ならともかく、普通は配列の中の複数の値が一目で見れた方が便利ですよね。
実は配列の要素は複数表示させることができます。マウスカーソルを合わせると青い四角が出るので、これを縦か横に引っ張るとずらっと配列が表示されます。この時点では、初期化されていない(暗い表示の)ものも表示させることができます。
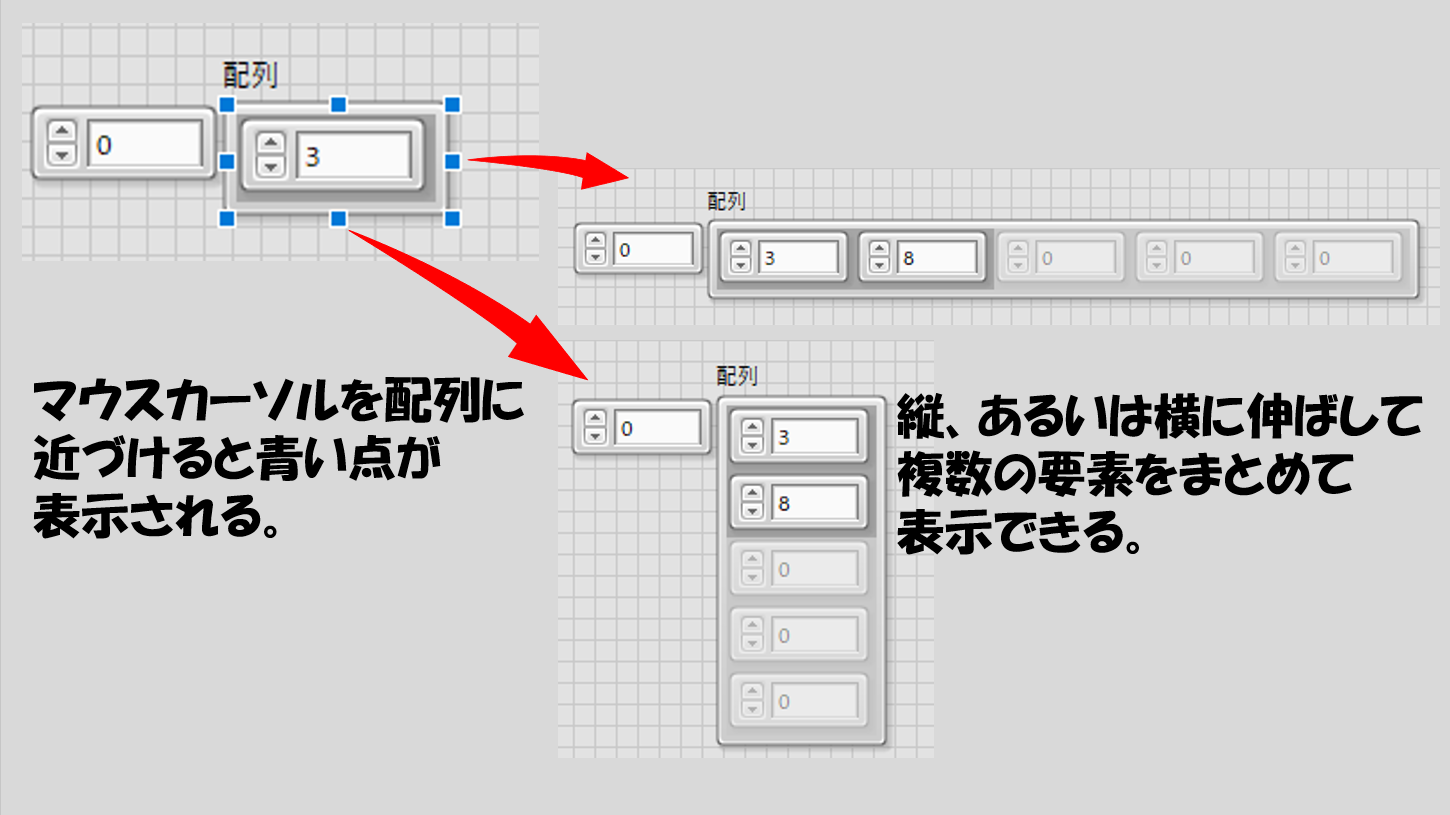
横に表示させるか縦に表示させるかに差異はありません(一次元配列の場合)。このとき、指標番号は常に「一番上もしくは左の要素の番号」を表しています。
例えば、4番目の部分に何か値を入れると、3番目の要素は自動的に0が入り明るい表示となります。3番目(指標番号2)の要素を飛び越えて4番目(指標番号3)の要素を用意できるのではなく、飛び越された場合にはその飛び越された部分は全て0(正確には、暗い表示の時に表示されているデータ)となります。
この状態で指標番号を変えると左側の要素を表した部分が一つずつ上あるいは左にずれることが分かるかと思います。

配列の作り方、見方についてはこの辺りの内容を知っていれば十分です。
配列の特徴
ここからは、配列が持つ特徴を見ていきます。
- 一つのデータタイプに対して複数の値を持てる
- サイズが自由に変更される
- 二次元の配列、三次元の配列、など、多次元の配列を持てる
- 「配列の配列」は作れない
一つ一つ確認していきますね。
一つのデータタイプに対して複数の値を持てる
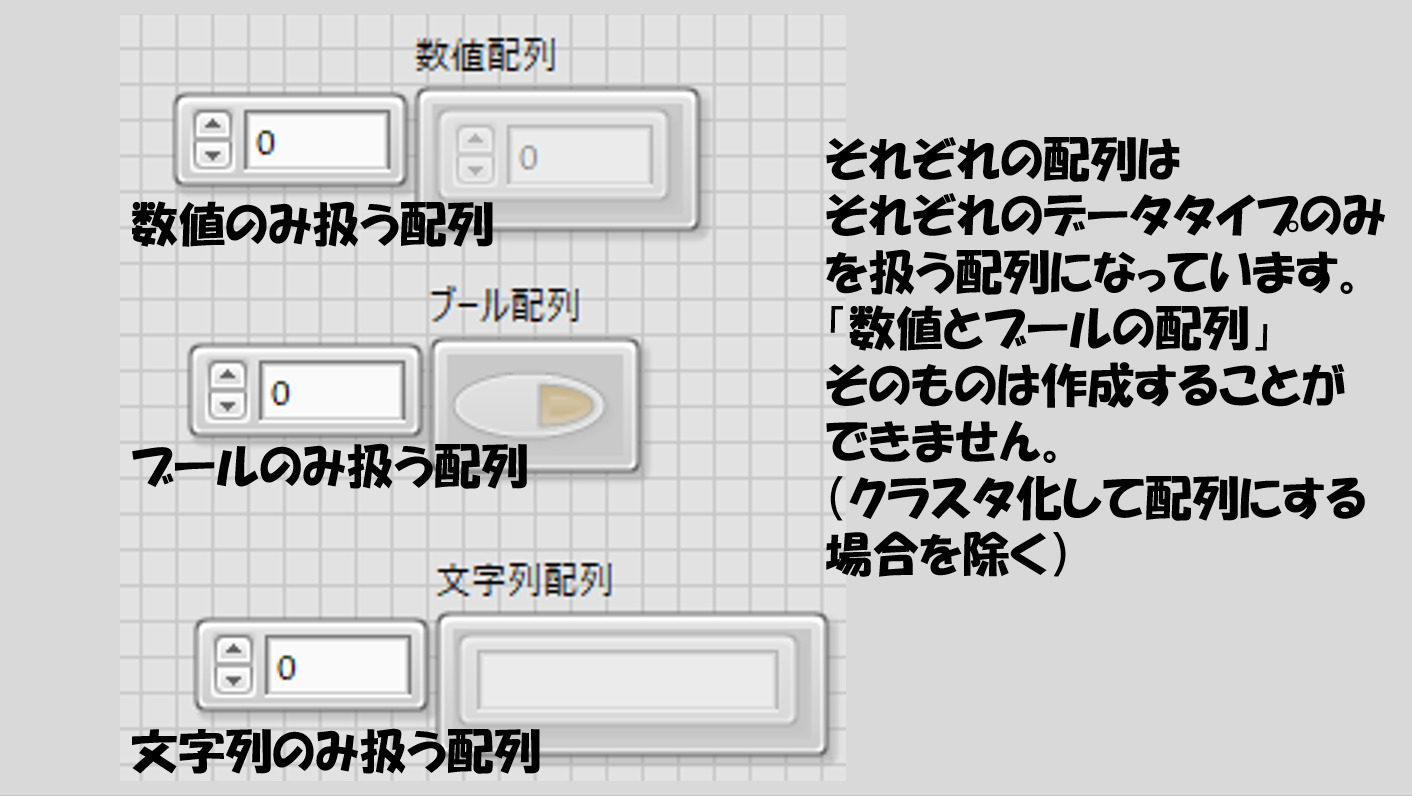
まず、配列は一つのデータタイプに対して複数の値を持ちます。
「数値の配列」や「文字列の配列」といった具合に、「あるデータタイプの配列」でしか存在しません。そしてそのデータタイプのデータを複数集めてひとまとまりにして扱っている、ということです。
逆に言えば、「一つのデータタイプ」しかまとめられません。「数値と文字列の配列」というものは作れません(それっぽいものはクラスタという別のデータタイプを使用すれば作れますが、それはあくまでクラスタの配列という扱いになるので今はおいておきます)。
サイズが自由に変更される
次に、サイズが自由に変更できるという点です。
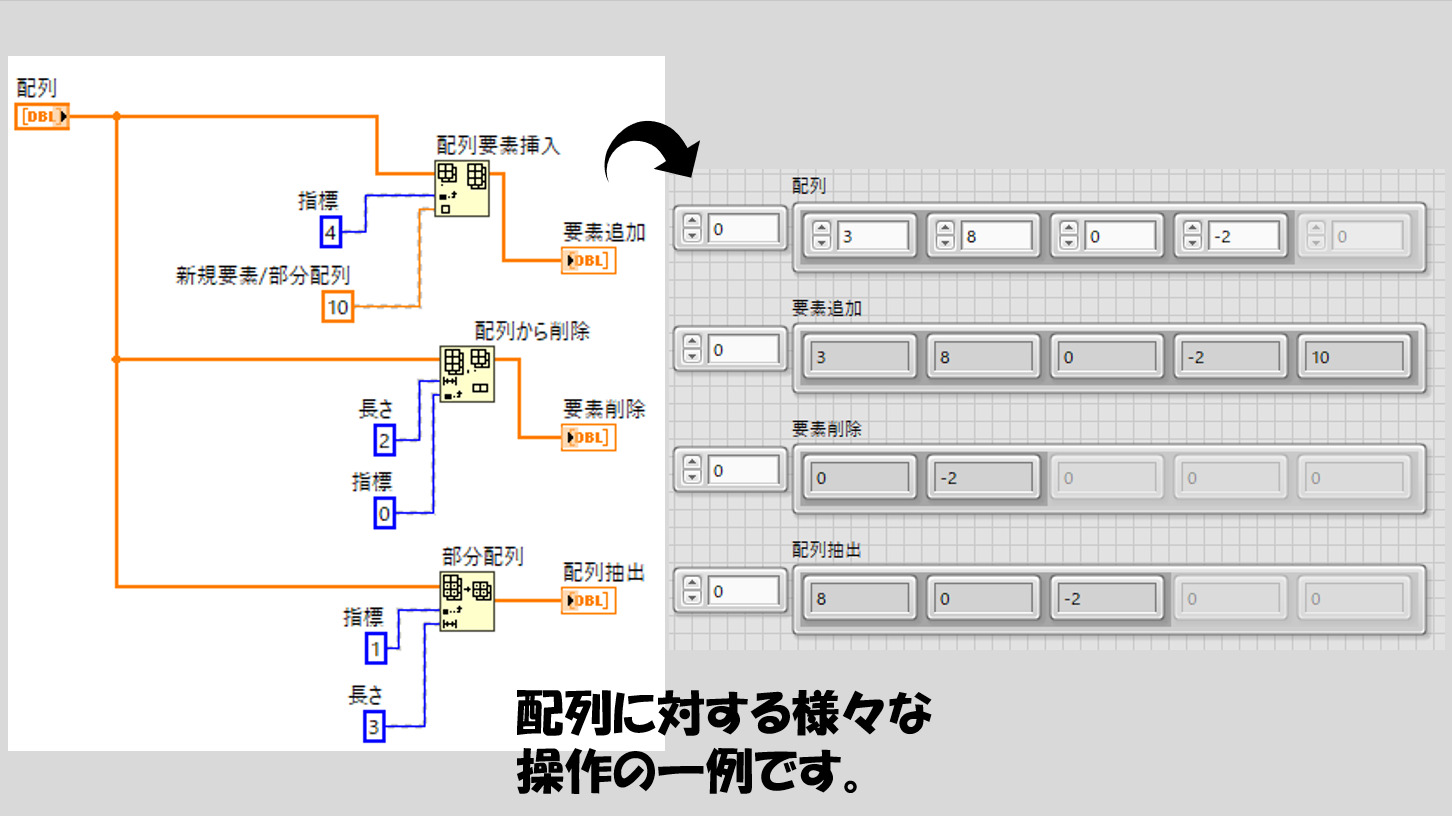
配列にはサイズがあるというお話をしました。いくつのデータのまとまりか、というそのデータの数がサイズになります。
このサイズは、プログラムの中で様々に変化することができます。配列に新たな要素を加えたり、逆に要素を削除したり、ある配列から部分的に要素を取り出して別の配列を作ったり。それぞれの操作のための関数が用意されています。
二次元の配列、三次元の配列、など、多次元の配列を持てる
配列の次元については、エクセルをイメージするとわかりやすいかもしれません。
先ほどまで扱っていた配列は、一次元の配列となっています。一次元配列は縦、または横に一直線にデータをまとめている(縦、横は表示上の違いだけです)状態です。これに対して、縦にも横にも広がっているのが二次元の配列です。エクセルの一つのシートの状態というイメージですね。
これに対し、エクセルのシートが複数重なったように二次元配列が重なった状態が三次元配列です。
実際には四次元以上も配列を作ることはできるのですが、個人的には四次元以上の配列が使われているのは見たことがないので気にしなくていいと思います。
多次元の配列は、配列の指標番号を表示している部分を縦に延ばすことで用意できます。例えば下に一つ伸ばし、指標を表示させる枠が2つになっているとき、要素を表す部分は縦と横両方に広げられます。縦方向の指標番号、横方向の指標番号を表せるため、このようになります。三次元以上の配列も同じです。
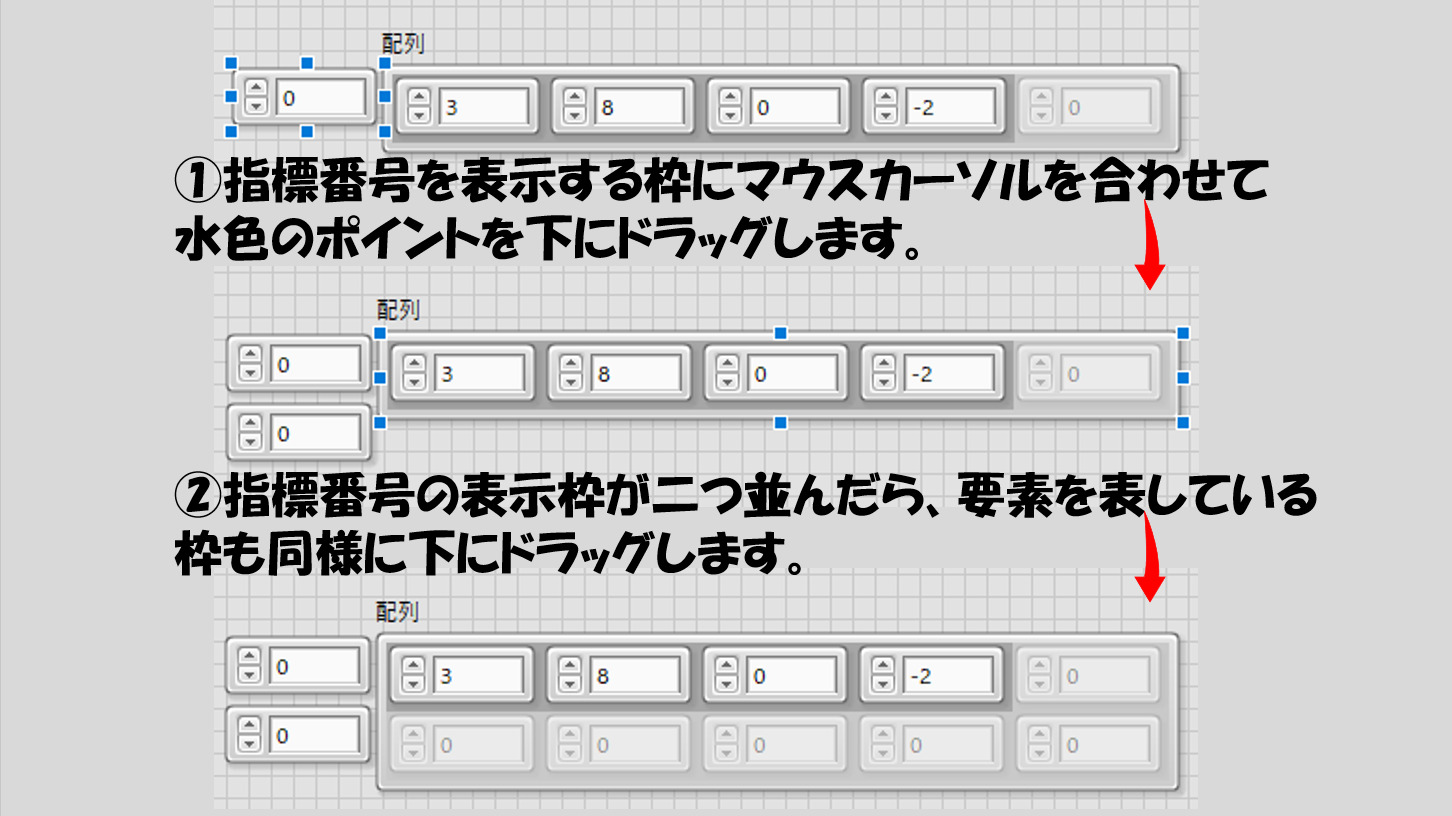
「配列の配列」は作れない
最後の配列の配列は作れない、ですが、よく考えると「一次元の配列」の配列は結局二次元の配列と同じことです。なので作れないというかは実質的にはより高次元の配列で実現されている状態と思ってください。
サイズ変更の部分で少し紹介していますが、配列に対する様々な操作を行う関数では指標番号で何かを指定することがとても多いです。例えば
- 指標番号X番目の要素を取り出す
- 指標番号X番目からY番目の要素を削除する
- 指標番号X番目に別の配列をはさむ
- 指標番号X番目からの要素を別の要素で置換する
といったことができます。逆に、要素を指定して指標番号を知るということもできます。
・・・なんでそんなことをする必要があるのか、どういった場面でこういった操作が必要になるのか私は最初わかりませんでしたが、プログラムを書く上で嫌になるくらいこれらの操作が必要になってきます。
配列操作は場合によってはプログラム全体の動作にもとても関係してきます。というのも、配列はそもそもが大容量のデータのまとまりを扱うことになるため、その分メモリを消費するからです。
LabVIEWは使用できる(=LabVIEWが予約している)メモリの量が決まっているため、あまりに配列を多用するとメモリ不足のエラーが起きてLabVIEW自体が落ちてしまうことがあります。これを防ぐために効率的な配列の扱い方はあるのですがこのシリーズではそこまで扱いません。
まずは配列はどう作るのか、どういう役割があってどういった操作ができるのかを覚えてもらえればいいかなと思います。
さて、これで繰り返し処理を行った際の複数のデータを扱うデータタイプの準備が整いました。いよいよ次回から繰り返し処理を行うというコードをLabVIEWでどう実現するかにはいっていきます。
もしよろしければ次の記事も見ていってもらえると嬉しいです。
ここまで読んでいただきありがとうございました。
コメント