この記事で扱っていること
- 大容量のファイルからのデータの読み出しを行う方法
を紹介しています。
注意:すべてのエラーを確認しているわけではないので、記事の内容を実装する際には自己責任でお願いします。また、エラー配線は適当な部分があるので適宜修正してください。
LabVIEWでデータファイルを読み込む際、そのファイルの中身があまり多くないのであれば、データを全て読み取り、例えばスプレッドシート文字列から配列に変換関数で配列にして処理するのが便利です。
ただ、配列に変換するとなると、その分のメモリを確保する必要が出てきます。
となると、大量のデータが保存されているファイルを読み取る場合には配列も巨大になりメモリを多く消費することになります。
LabVIEWはビット数によって使用できるメモリ量が決まりますが、例えば32ビットのLabVIEWでは多くても3 GBまでとなっているようなので、これ以上のメモリを使用することができません。
プログラム内では当然、この配列にばかりメモリを消費するわけではないだろうと思うので、大容量のデータを読み取るのに困るわけです。
ただ、往々にしてそんなに大量のデータを一度に一気にほしいという場面もあまりないかもしれません。例えば、グラフに表示させる場合に、そんなに大量のデータを一度に読み込んでも見にくくなると思います。
そこで、データを区切って読み取るような仕組みを作ることで、一度に指定した数分のデータを読み、その読み取り範囲を前後にずらすような仕組みを作ってみました。
どんな結果になるか
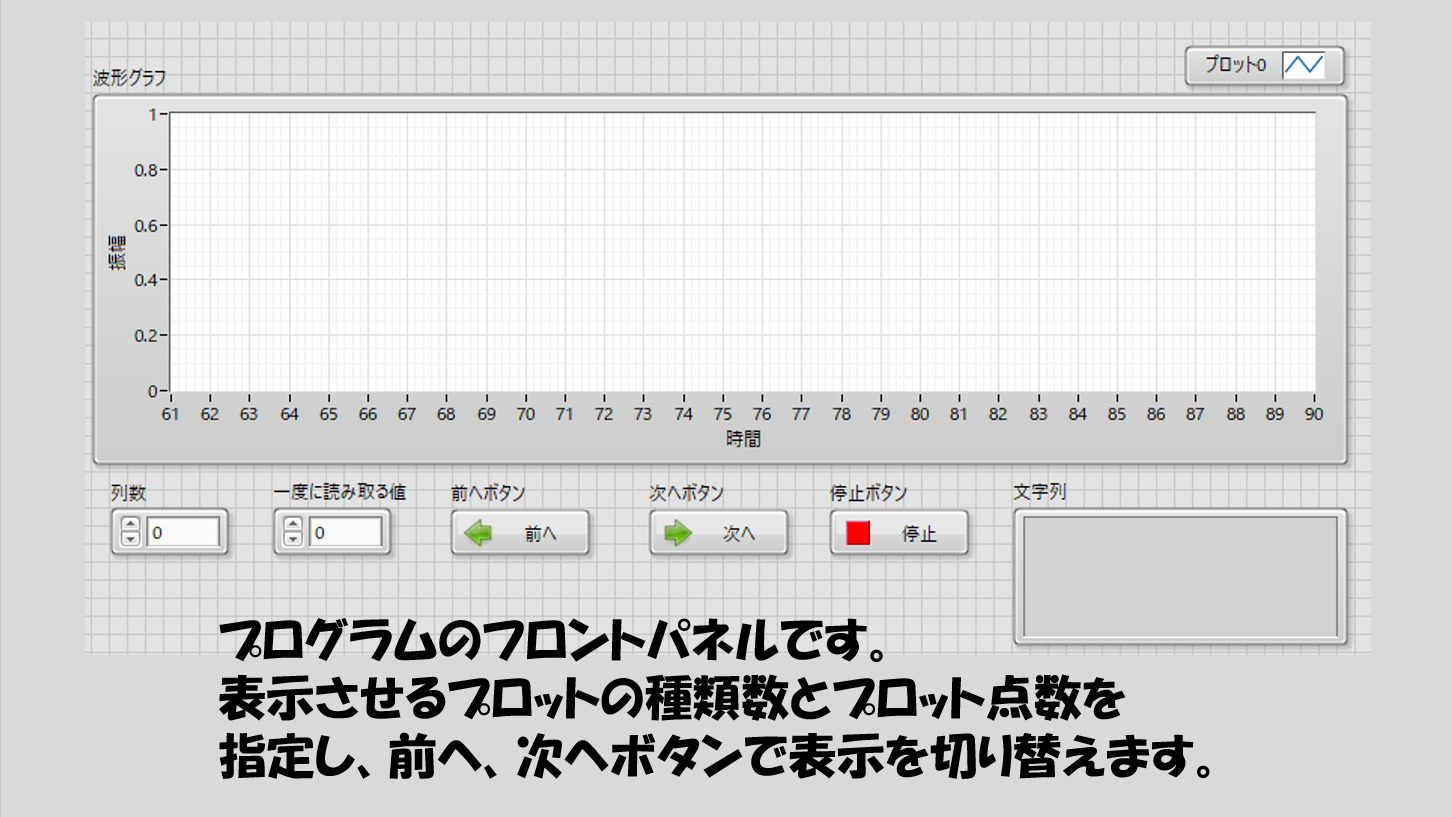
プログラムの作りとしては、まずファイルにどれだけの種類のデータがあるかを指定し、一度にいくつのデータを読み取るかを指定します。
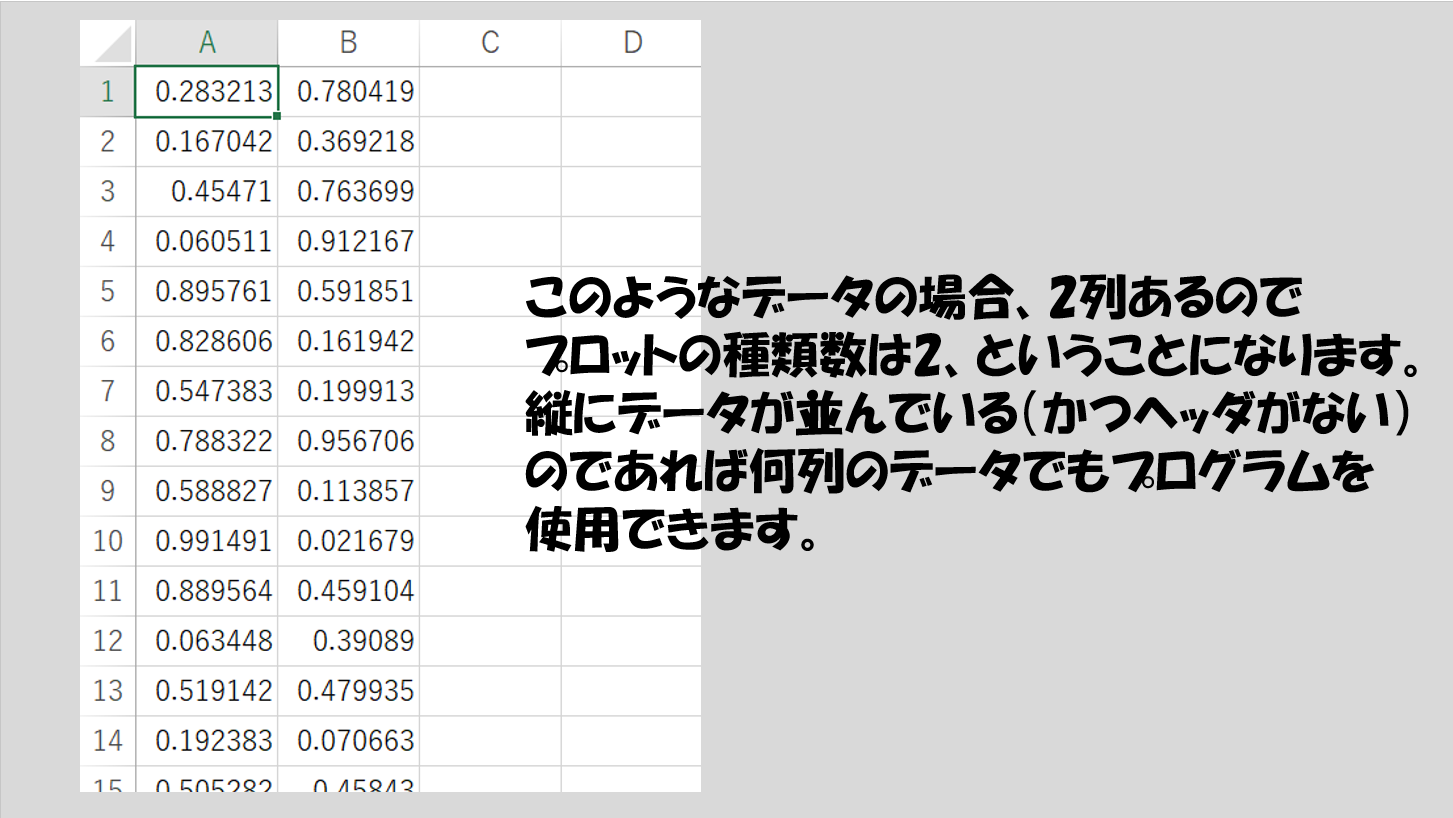
ここでいうデータの種類というのは、例えば以下の図のようにデータが列方向にずらっと並んでいた場合、何列あるか、に対応します。下の図のようなファイルであれば2列、ということになります。
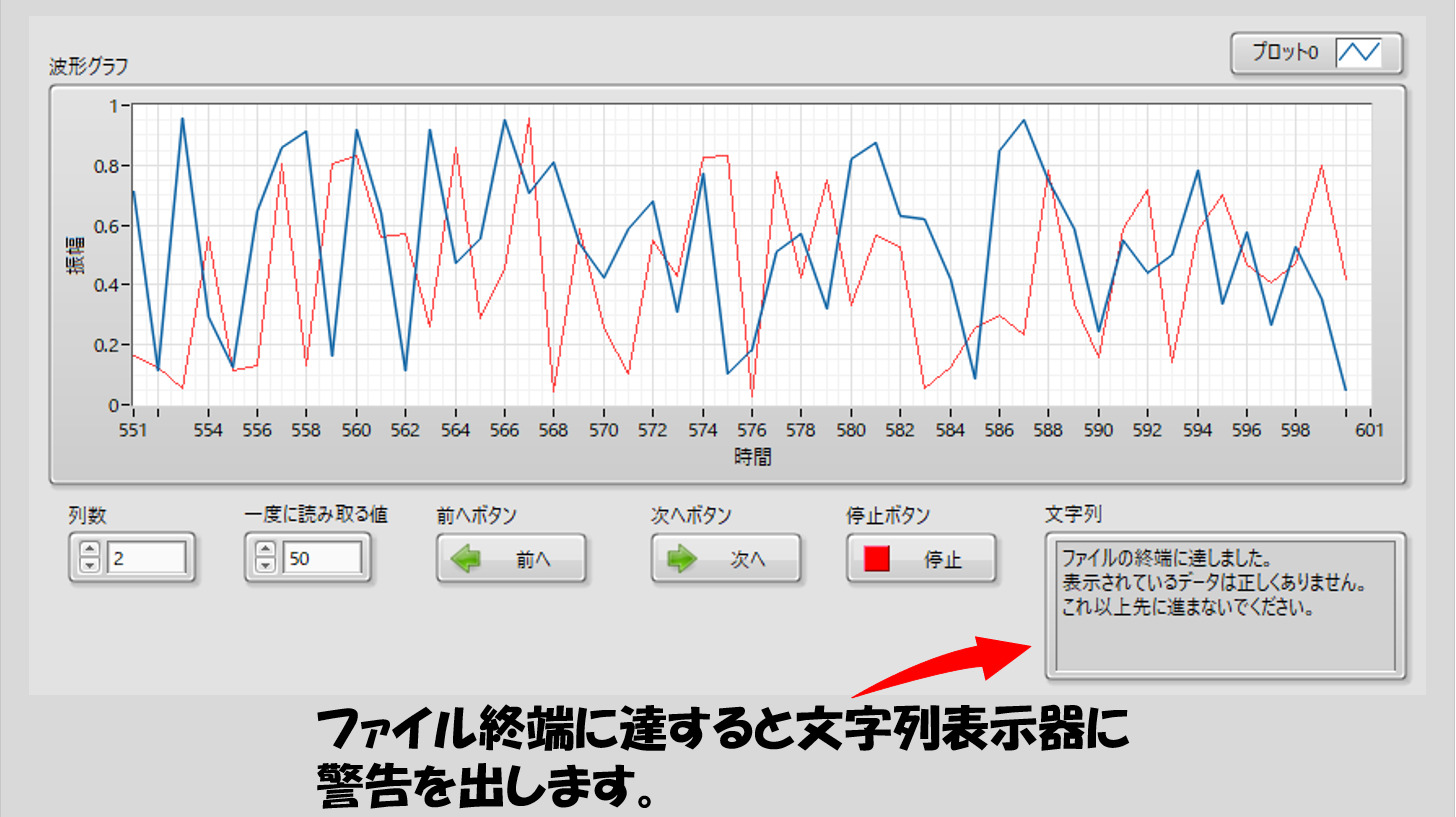
プログラムを実行する前にこれら二つのパラメタを決めて実行すると、どのファイルを読むかのダイアログが表示され、ファイルを指定するとグラフに指定した数のデータが抜き出されて表示されます。
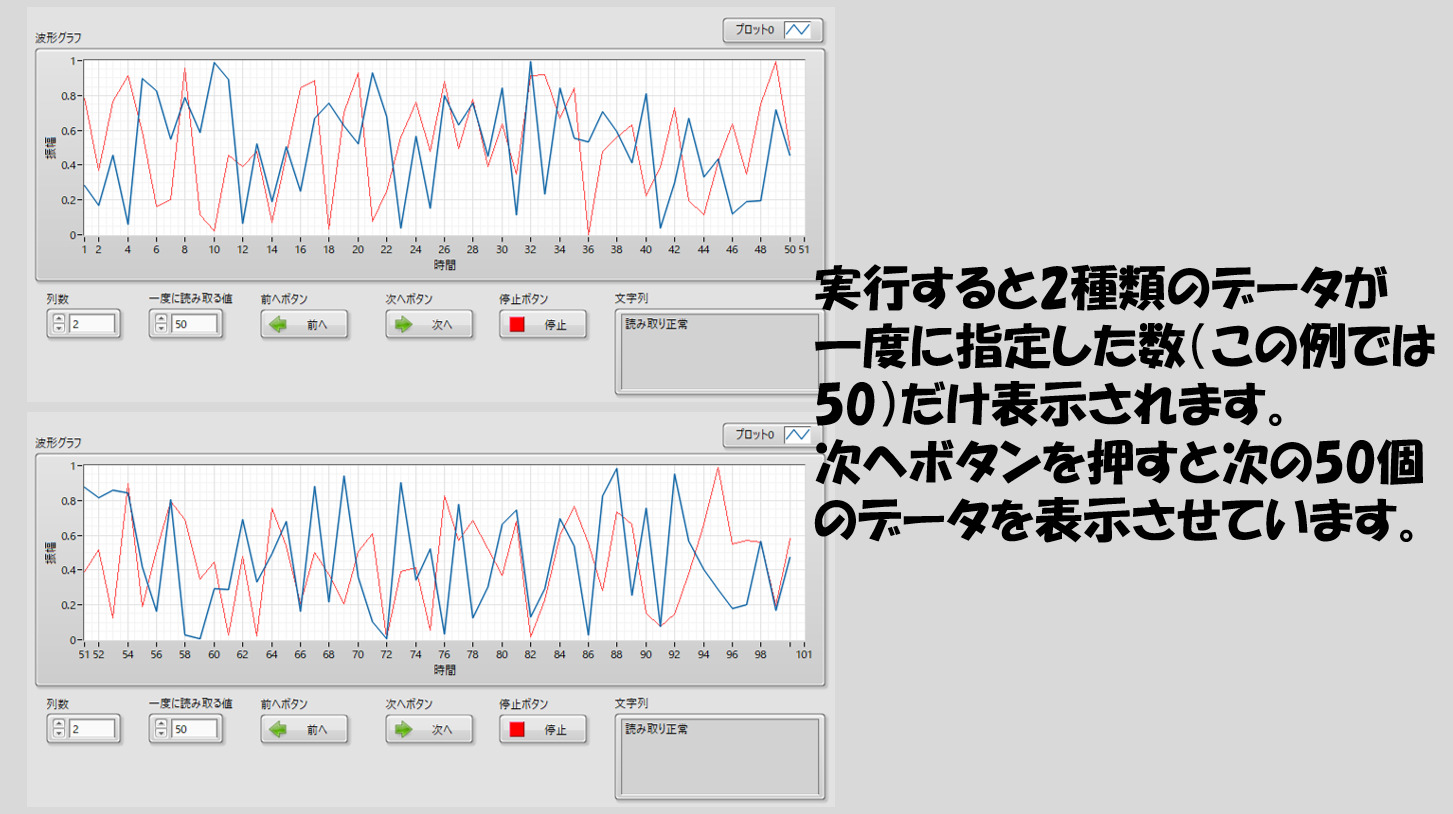
LabVIEWのグラフは0から始まり、デフォルトだと常にそうなってしまうため、敢えてファイルの行数とグラフの表示を一致させるためにオフセットを変更するような形式としています。
また、大容量と言えど当然有限なので、ファイルの中身のデータはいずれ終わります。その際には警告を表示し、データの終端まで来たことを知らせます。(下の図で見せているファイルは全然大容量ではないのですが)
プログラムの構造
プログラムは大容量のデータを扱っても効率がよくなるようにイベントストラクチャや配列連結追加を使わない方法で実装しました。

前へボタンあるいは次へボタンを押すと切り替えるようにしていますが、このイベントケースにはタイムアウトイベントも追加しています。
このプログラムで重要な働きをしているのはテキストファイルから読み取る関数のライン読み取りという設定です。これは通常はオフになっているのですべてのラインを読み取るのですが、ライン読み取りをオンにすると、一回この関数を実行したときには一行しか読み取りません。
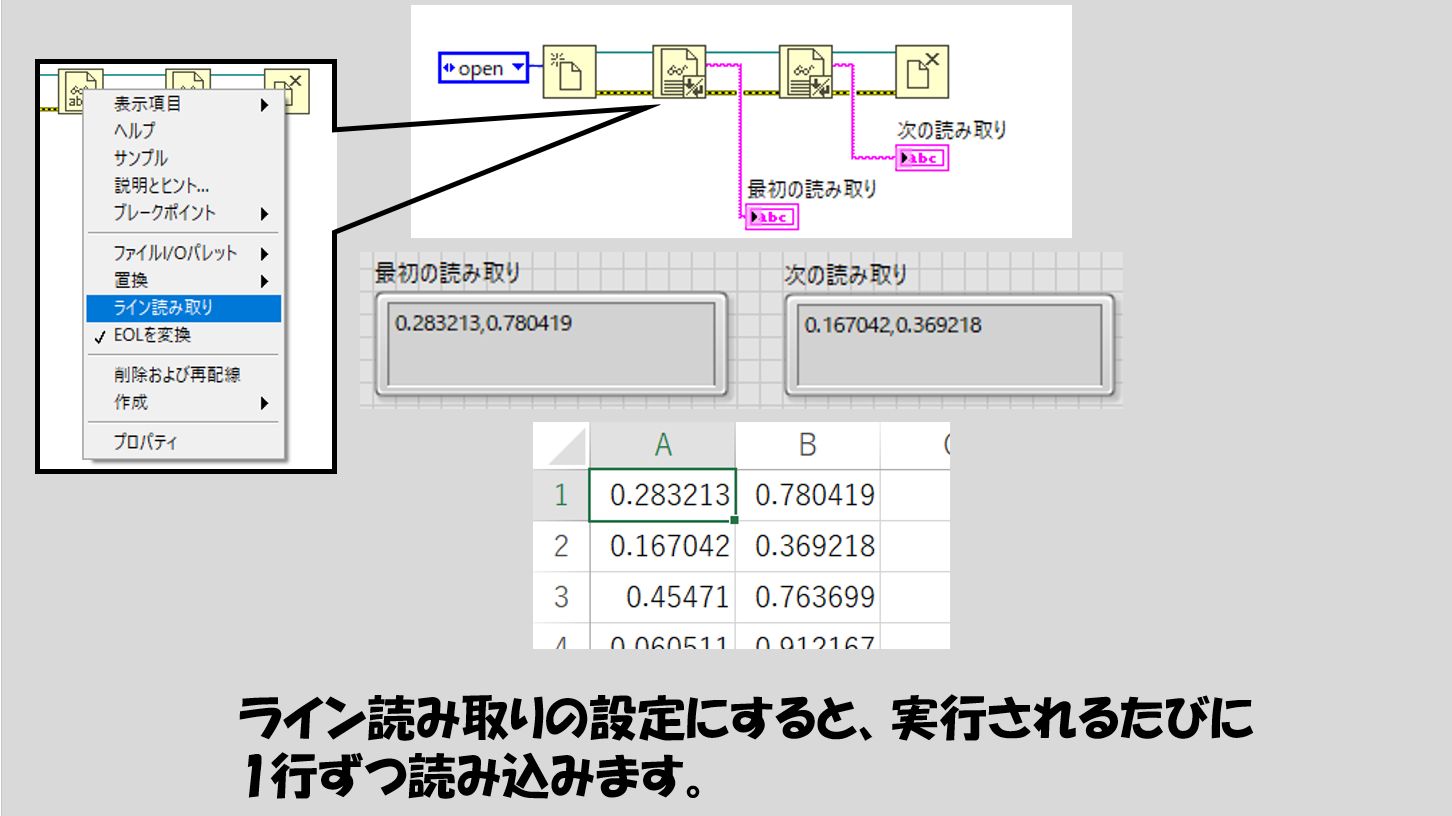
そのためこの性質を逆手に取り、
- 読み取りたい行まではForループで「空読み」する
- 読み取りたい行までたどり着いたら、読み取りたいデータ数分だけForループを回す
という組み方をしています。
プログラム全体の流れを確認していきます。
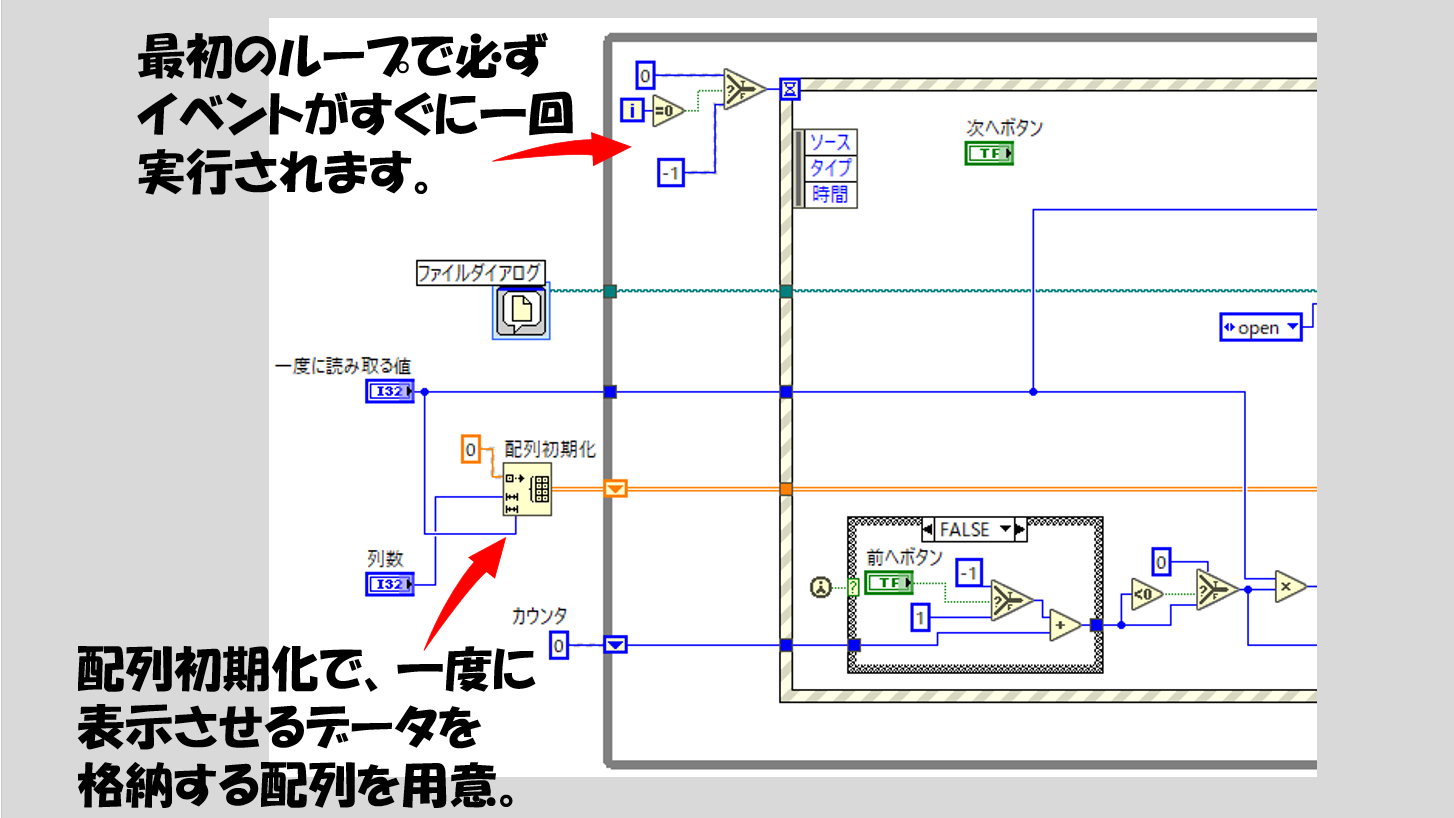
まずはWhileループに入る前に配列初期化を使用することで、これから読み出すデータの格納場所を確保しておきます。あらかじめ配列を用意してその配列の値をどんどん置換していくという方法をとるためです。
Whileループに入ってからイベントストラクチャがありますが、何もイベントを実行しないとグラフには何も表示されません。そこで、Whileループの一番最初だけタイムアウト値を0にして一度強制的にタイムアウトイベントを実行するようにしています。
なお、タイムアウトイベントはWhileループの2回目以降は発生しないようにするために-1を配線しています。
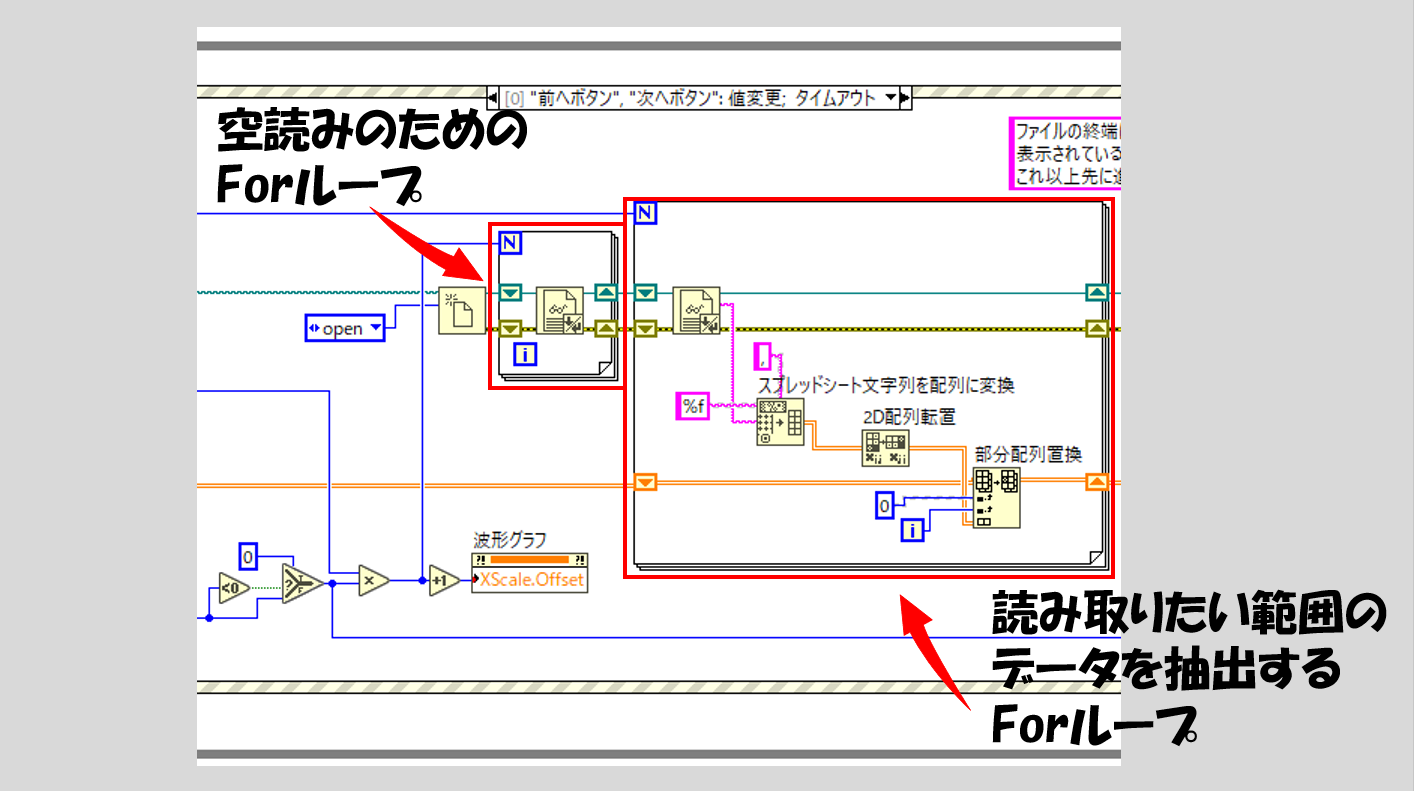
Whileループに入ったら、前へボタンか次へボタンが押されたらイベントを実行するようにしています。このイベントの最初で、Forループの「空読み」を何回行うかを指定します。
そのための仕組みとしてカウンタという数値を用意し、カウンタ×一度に読み取る数の計算によって空読みの回数を指定、その後に一度に読み取る数の値をもう一度Forループに使用します。
イベントは前へか次へのボタンどちらかが押されれば発生するので、カウンタの値の操作は前へボタンのみ行っています。もしこのイベントケースが実行され前へボタンがTRUEになっている(つまり前へボタンが押されたことでイベントが発生した)場合にはカウンタを-1します。一方もしこのイベントケースが実行され前へボタンがFALSEになっている(つまり次へボタンが押されたことでイベントが発生した)場合にはカウンタを+1します。
ただし、イベントケースの初回(タイムアウトによってイベント発生)にはカウンタは0のままとします。
また、カウンタが0より小さい値になった場合には強制的に0とするようにしています。

カウンタの設定が終わったらあとはForループを二つ設けて、一つ目で空読みを繰り返し、二つ目で読み取りたい範囲のデータを抽出、配列初期化で用意しておいた配列と値を置換してやります。
また、いずれファイルの中のデータの終端まで達した際に知らせる機能は、ファイル終端まで達したことを意味するエラー4が出ることを利用して判断させています。
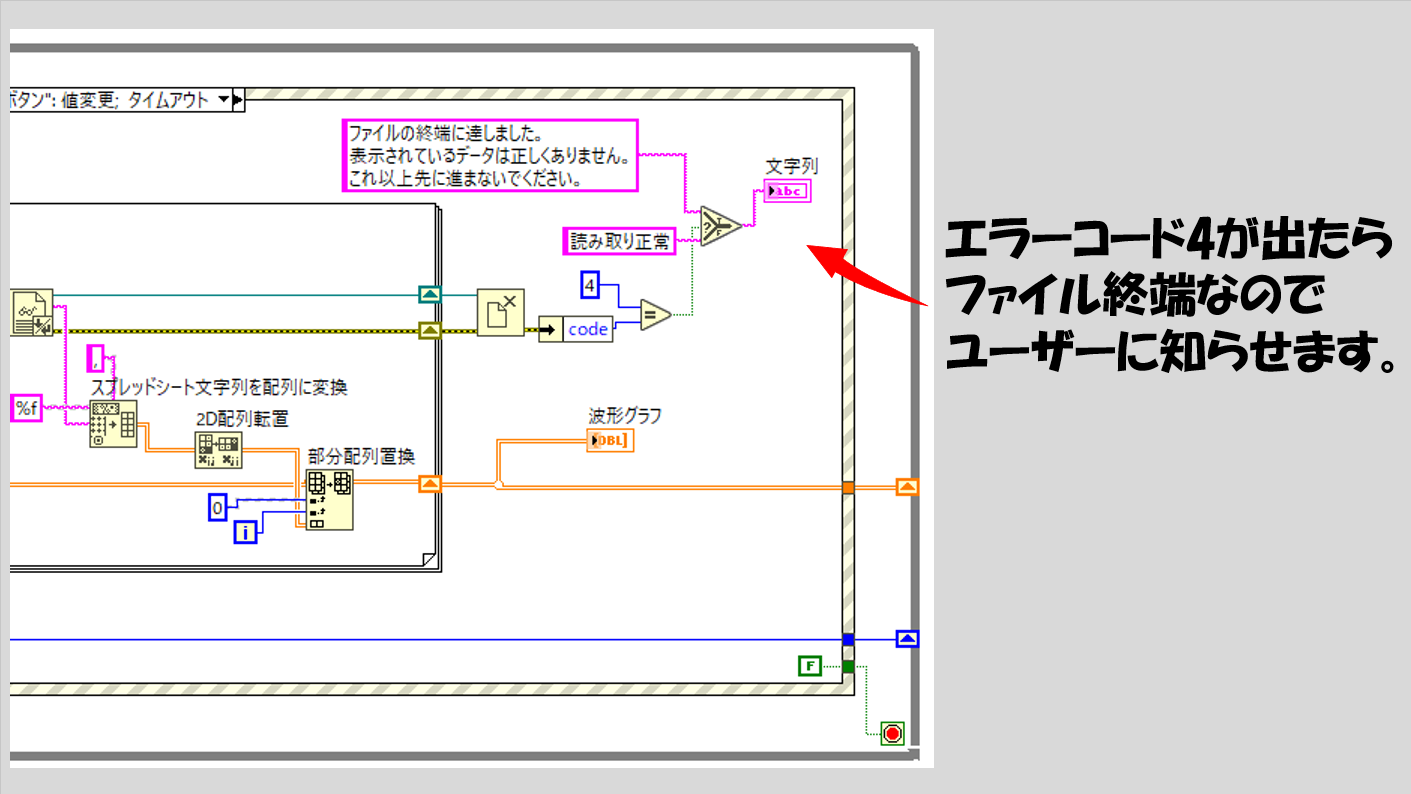
効率があまり良くないなと思うのは、これを毎Whileループごとにやっている点です。
テキストファイルから読み取るの関数でライン読み取りをした後、前のラインに戻って読み取るということができません。正確にはできるのかもしれませんが、簡単にはできないと思います。
そこで仕方なく、読み取る範囲を変える場合には一度ファイルを閉じて開きなおし、再度同じようにForループを駆使して別の範囲のデータを読み取るようにしています。
この仕組みからもわかる通り、このプログラムはファイルの後半を読もうとするほど表示に時間がかかるようになります。空読みのForループの回数が増えるからですね。
配列連結追加を使用した場合
上記のプログラムは効率の面を考えて配列連結追加を使わずに実装しました。
当然配列連結追加を使用してもプログラムは組めるのですが、試したところ読み込むデータが後の部分になればなるほど処理速度に差が出ました。

例えば、大容量のcsvファイルに対して、一度に20000点読み込む設定とし、120001点目から140000点目までを読み取るために次へボタンを押してから実際にグラフ表示にかかる時間は、配列連結追加を使用すると約4秒かかるのに対して配列置換の方法だと約2秒ほどで済みました。
ただし、データを空読みする構造自体はどちらの方法でも同じなため、純粋に後半のForループでの効率が物を言っているようです。
大容量のファイルの読み取りを、特に意識しないで一度にすべてのデータを読み取ろうとするとLabVIEWはメモリ不足のエラーを出しがちです。
64ビットのLabVIEW(日本語がないですが)では使用できるメモリ量が増えるのでエラーを起きにくくすることはできますが、一度にまとめて大量のデータを呼び出す必要がないのであれば本記事の内容を役立ててもらえたら嬉しいです。
ここまで読んでいただきありがとうございました。
コメント