この記事では、LabVIEWプログラムをどのように読み解くのかについて紹介しています。
他の人が作ったプログラムを引き継いだがLabVIEWは初めてなので中身をどう読んでいいかわからない、あるいはとりあえずLabVIEWをインストールしてサンプルを見てその内容を理解したいが手始めにどうすればいいか、という方向けに、最低限これだけは覚えときましょう、といった内容を紹介しています。
最低限の知識なので、あまり複雑なプログラムには対応しきれませんが、それでもプログラムの構造を紐解く上で大切な内容を取り上げています。
なのでLabVIEWプログラムを自分で書ける方には退屈かもしれません。また、プログラムの読み方を紹介しているので、プログラムを作るのに必要な操作の説明はしていません。
プログラムを作るほうに興味がある場合には、初心者の方向けにプログラム作りの流れを紹介したシリーズがあるのでこちらを参考にしてみてください。

このシリーズは全部を見るとなかなかのボリュームになっています。
本記事でも要所要所でこのシリーズに関連する記事についてはシリーズの何番目の記事なのかの紹介をしています。
本記事で扱っている内容について
LabVIEWプログラムは図的にプログラムの処理の流れを記述するので、様々な図が何を表しているのかを知らないとプログラムが読めません。
「先輩のプログラムをもらったけれど読み方がわからないから何がされているのか全く分からない」、「古いプログラムがあって少しだけ修正したいんだけれど何が何やらわからない」、そんな場合に、
- LabVIEWのプログラムの色や表記法には意味がある(データタイプが異なる)ことを知る
- プログラムの中で実行される処理の順番には決まりがあることを意識する
- アルゴリズムについて、どの表記がどういう処理(繰り返し、条件分岐、など)をしているかわかる
- 各処理が具体的にどういったことを行っているのか調べられる
これらのことが重要だと思っているので、こういった内容をこの記事で取り扱っています。
なので、もしLabVIEWプログラムを読むのに何から始めたらいいの?と迷っている方はこの先読み進めていただくと何となくでも様子をつかめるようになるかなと思います。
LabVIEWプログラムの基礎用語
LabVIEWプログラムを理解するうえで、まず知らなくてはいけないのはよく使われる用語です。
本記事で紹介する、プログラムの読み方の説明でも専門の用語を使うのは避けられないので、最低限これだけは覚えておく必要がある、という用語がいくつかあります。
その中でも代表的な用語は以下のものです。
- フロントパネル/ブロックダイアグラム
- 制御器/表示器
- ワイヤ
- 実行ボタン
本記事ではこれらの用語は特に説明なしに使います。
なのでもしこれらの用語の意味が分からない、ということであれば別記事で解説しているのでこちらをまずは確認してもらうといいと思います。

データタイプを知る
LabVIEWはプログラムを書くためのプログラミング言語であり、様々なデータを処理することになります。
その際にLabVIEWでは色によってそのデータが何を表しているかを表現しています。
逆に言えば、色さえ覚えてしまえばどのようなデータが扱われているかを一目で知ることができます。何気にこれがとても便利です。
なのでLabVIEWプログラムを理解するうえで、まずはデータタイプと色の対応を覚えてしまうことをオススメします。
本来は以下の図で紹介している以外にも数多くのデータタイプがありますが、頻出するデータタイプを挙げています。
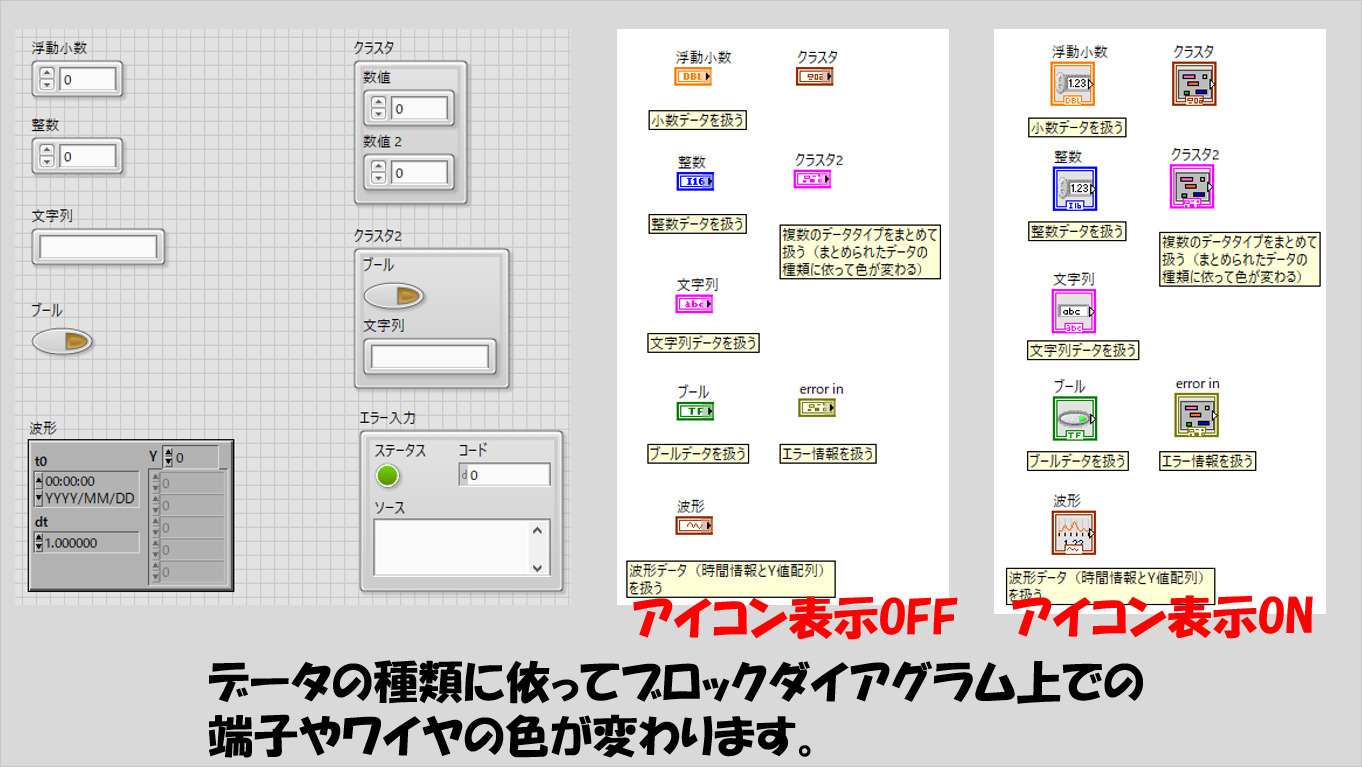
なお、アイコン表示のOFFやONというのはブロックダイアグラム上の見た目の違いなだけです。右クリックして相互に変換可能です(アイコン表示をONにすると場所を取るので、基本的にOFFにしていることが多いと思いますが、LabVIEWをインストールしたてのデフォルト状態ではONの設定になっています)
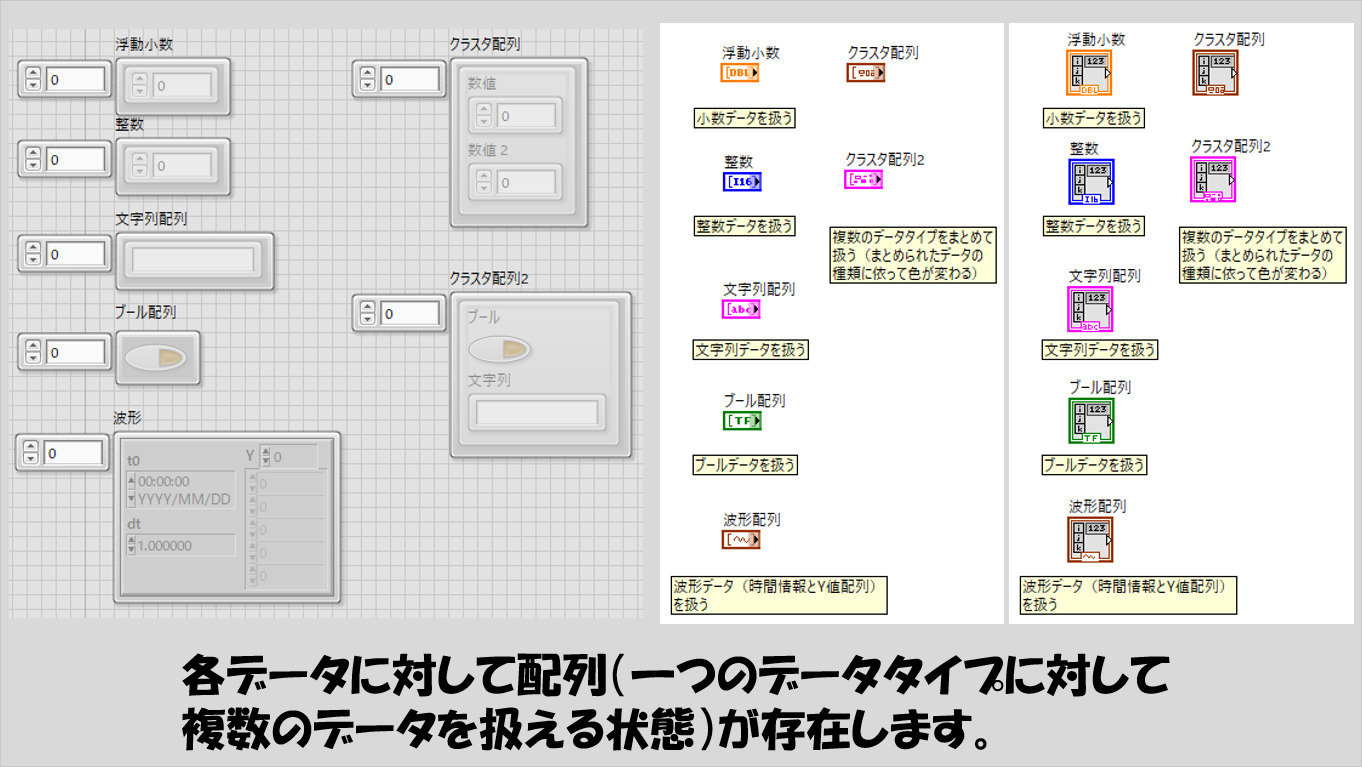
これらは「単体」の値を扱います。同じデータタイプを複数扱う場合には、それぞれに対して配列データが対応します。(エラーデータも配列として扱うこと自体はできますが、あまり見かけません)
他のプログラミング言語を知っている方からすれば「リスト」という表現がわかりやすいかもしれませんが、配列とリストは同じイメージです。
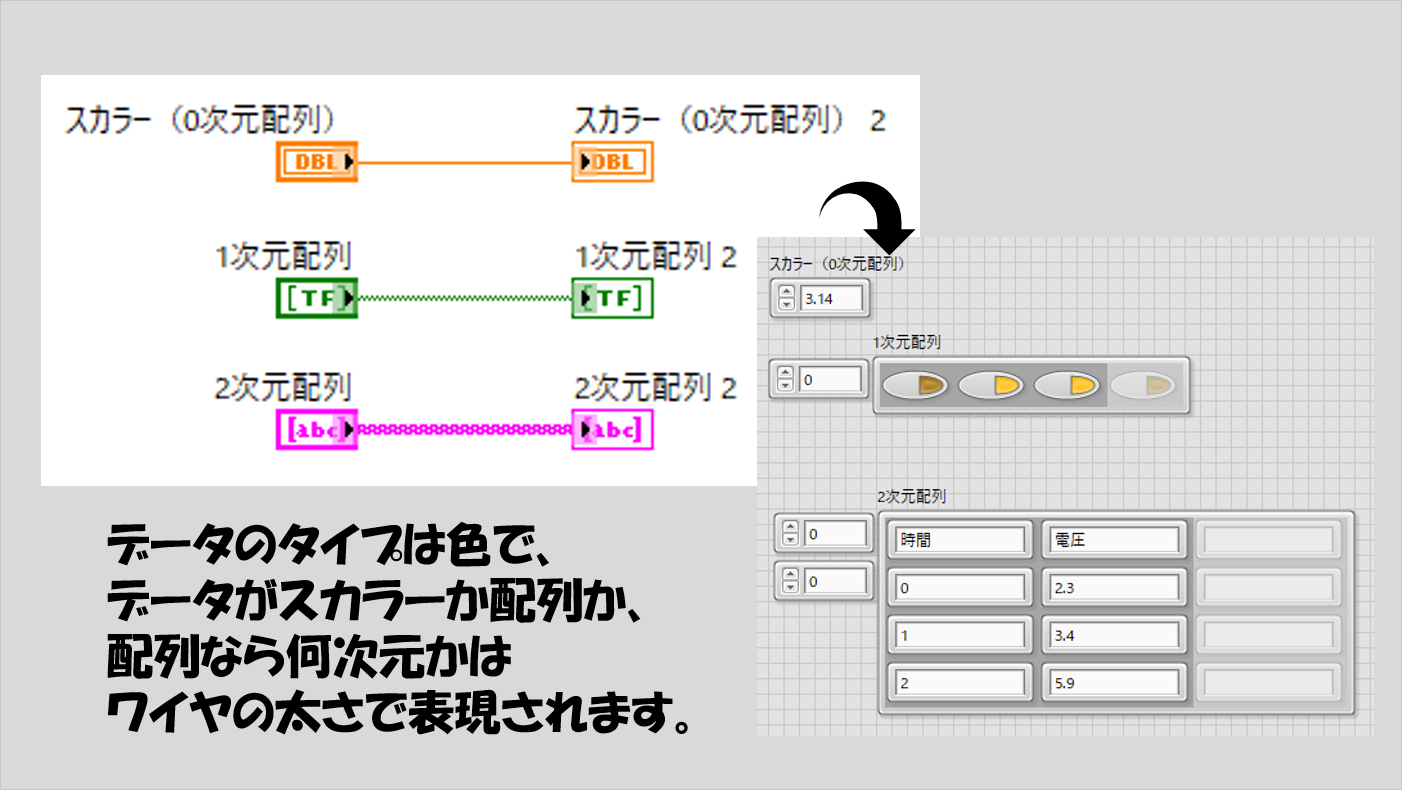
配列には次元という考え方が存在します。1次元、2次元、・・・と多くありますが、ほとんどの場合4次元以降の配列は扱わないと思います。
これらの次元は、ワイヤの太さで判断することができます。なので、色とワイヤの太さはLabVIEWプログラムを理解するうえでとても重要です。
配列ではない、単体の値を表すものはスカラーと表現することもあり、これをあえて「0次元」ということにすると、各違いは以下の図のように表れます。
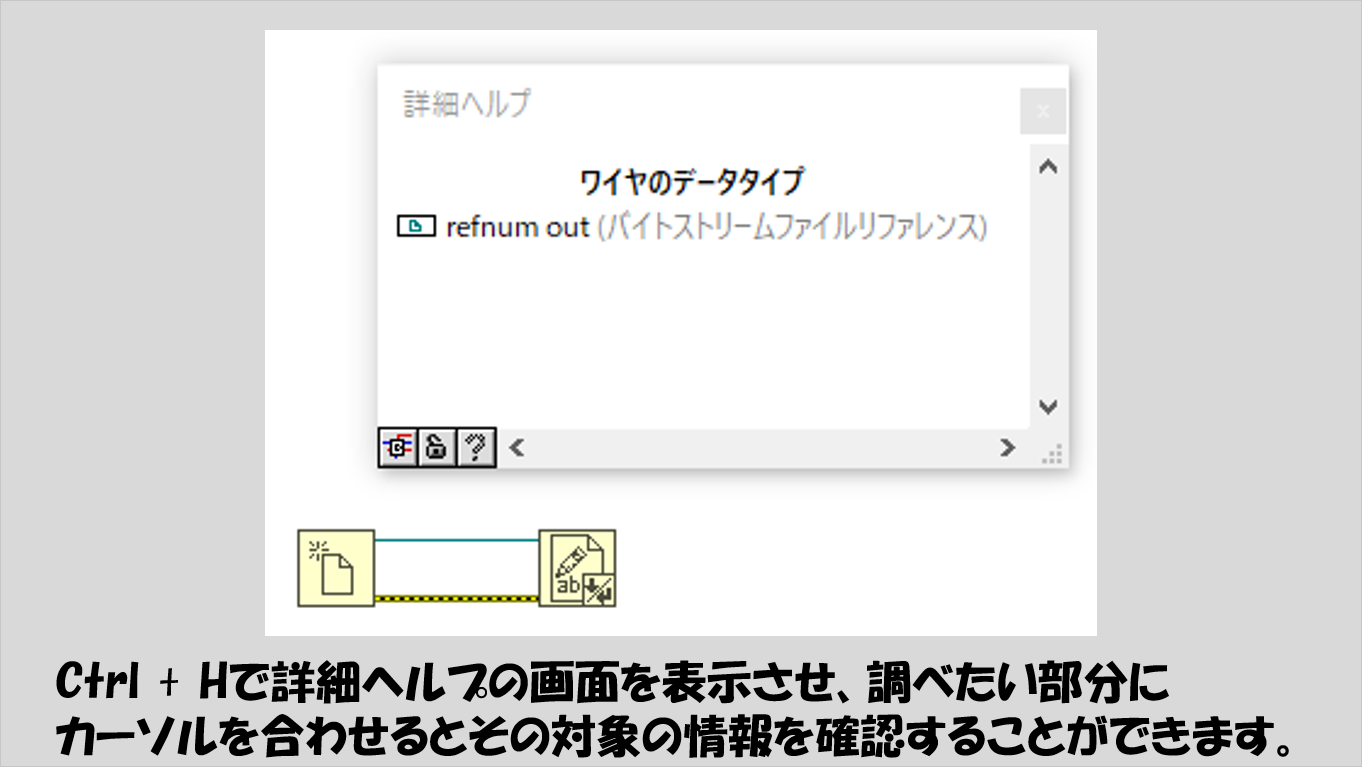
もしここに挙がっていないデータタイプが使用されている場合には、Ctrl + Hで開く詳細ヘルプの画面でデータタイプの種類を確認することができます。
まぁLabVIEW初めて、という方にとってはこの詳細ヘルプでデータタイプを確認しても「なんのこっちゃ?」となるかもしれませんが、要はデータタイプが違うのだな、と区別できることが重要です。
例えば以下の図では、緑色のワイヤにマウスカーソルをあてたときの詳細ヘルプの結果で「(バイトストリーム)ファイルリファレンス」とのことで、ファイル情報を扱うリファレンスデータと読み取ることができます。
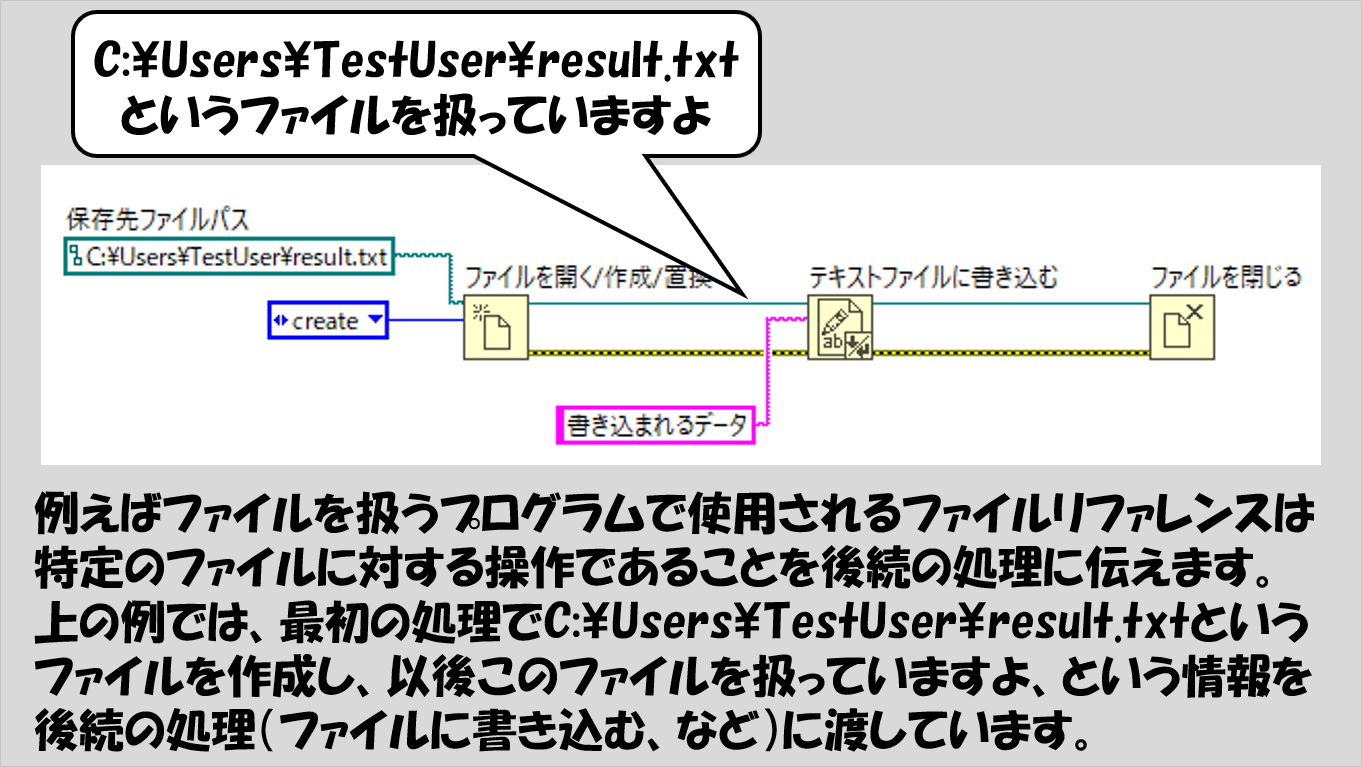
リファレンスデータ、というのは「ある特定の情報に対する参照番号」です。refnumと表現されたりもします。
ファイルを扱う場合によく見られるのでファイルIOの例を以下で紹介していますが、ファイル操作以外では例えばハードウェア操作でも似たような概念で考えれば読み解く上では十分だと思います。
データの種類が色やワイヤの太さで表されることがわかったら、改めて自分が読み解こうとしているLabVIEWプログラムを見てみてください。きっと上に挙げた見た目のものがわんさか登場していると思います。
ただ、これだけを知ってもプログラムは読めないので、次にプログラムの「順番」について紹介していきます。
LabVIEWプログラムの「流れ」を知る
文字を上から順に並べてプログラムを書いていく、いわゆるテキスト言語と異なり、LabVIEWは制御器や表示器、関数などのアイコンをワイヤで結んでプログラムを組むことになります。
テキスト言語では基本的にプログラムが実行される順番は上からですが、LabVIEWでもプログラムが実行される順序があり、これを見分ける方法があります。
とても大雑把に説明すると、構成を全く考えないで各制御器や表示器、関数などのアイコンをむちゃくちゃに配置しない限りでは、左から右に実行されます。
ただ、この左から右という表現は結果的にそうなるだけであって、より正しいルールとしては「入力値が全てそろってから処理が実行され結果が出力される」ということを意識することが大切です。
説明のために、以下では抽象化した表記「A」、「B」で表すことにします。LabVIEWでは処理のためのノード、関数、端子に様々な形がありますが、全部ひっくるめて四角い表記で「A」~「D」で示します。(実際はLabVIEWのアルゴリズムに関わるストラクチャと呼ばれる処理にも同じ原則を当てはめられます)
これを踏まえ、「入力値が全てそろってから処理が実行され結果が出力される」についてまずはシンプルに図示してみると以下のようになります。
以下の図では、入力として「入力1」と「入力2」がAに与えられています。データタイプの色を見るとわかりますが、入力1は数値(浮動小数)、入力2はブール値です。
そしてAの結果がBにわたって、Bの処理が終わった結果が「出力3」という文字列の表示器に与えられています。
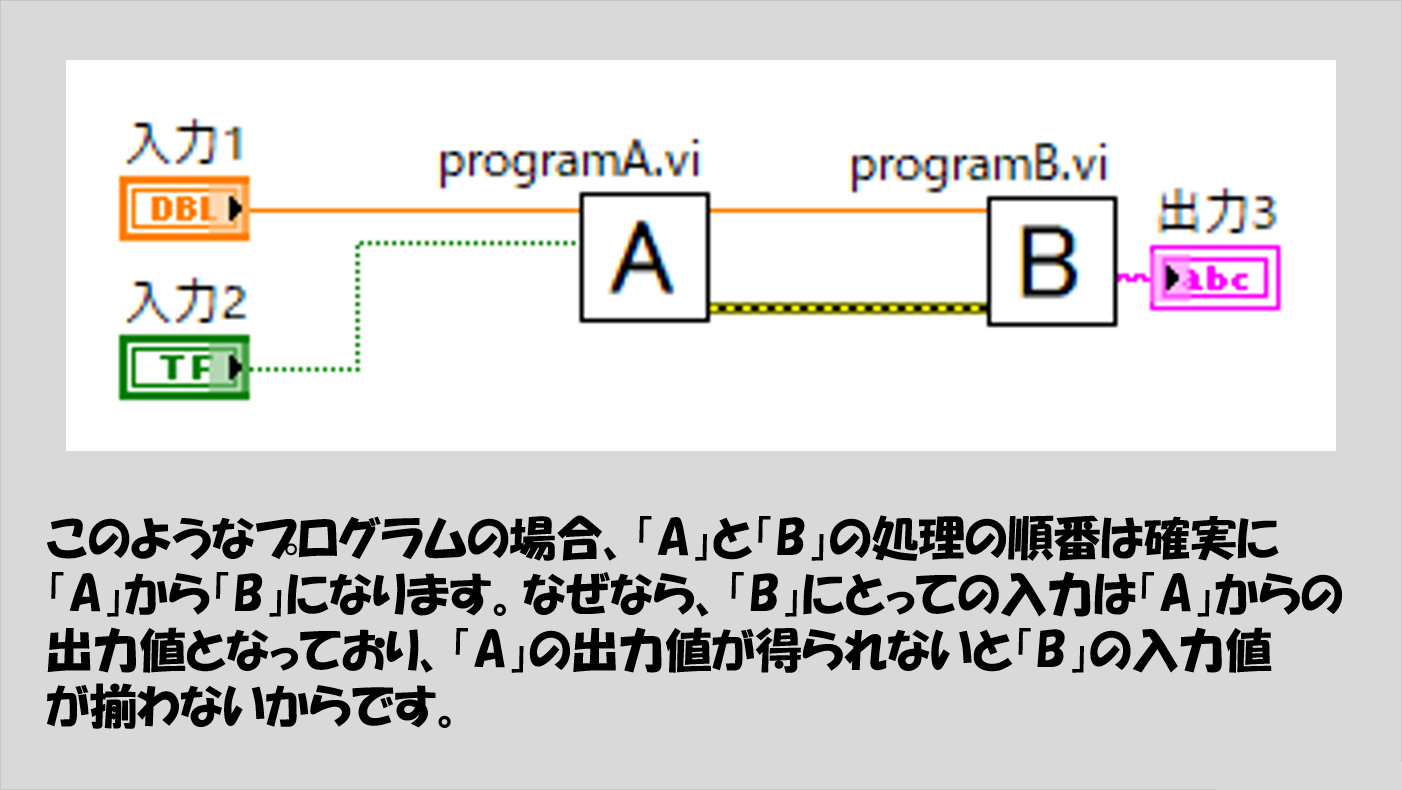
図にも書いていますが、上の場合には「A」の処理の後に「B」が行われるという順番が確定しているので、プログラムの流れは「Aの処理が最初に実行されて終わったらBの処理が実行される」といえます。
一応、抽象化しない形で具体的な表現をするとこんな感じです。もちろん、扱っているデータのタイプには依りません。常に、赤で示した数字の順番に実行されます。
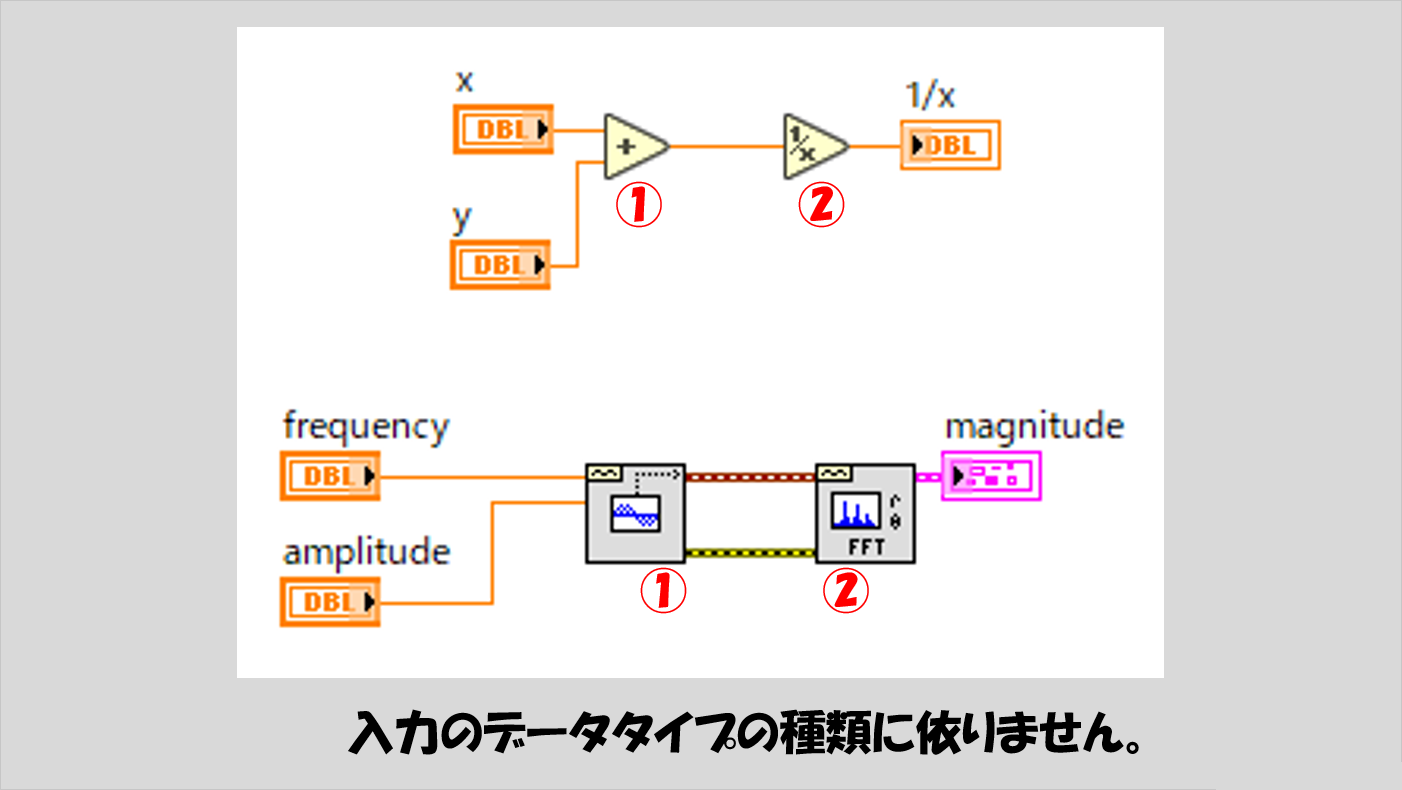
LabVIEWのプログラムの流れを理解するためには正直この説明だけでいいと言えばいいのですが、これはLabVIEWプログラムを読むうえで絶対に覚える必要がある部分なのでもう少し例を挙げます。
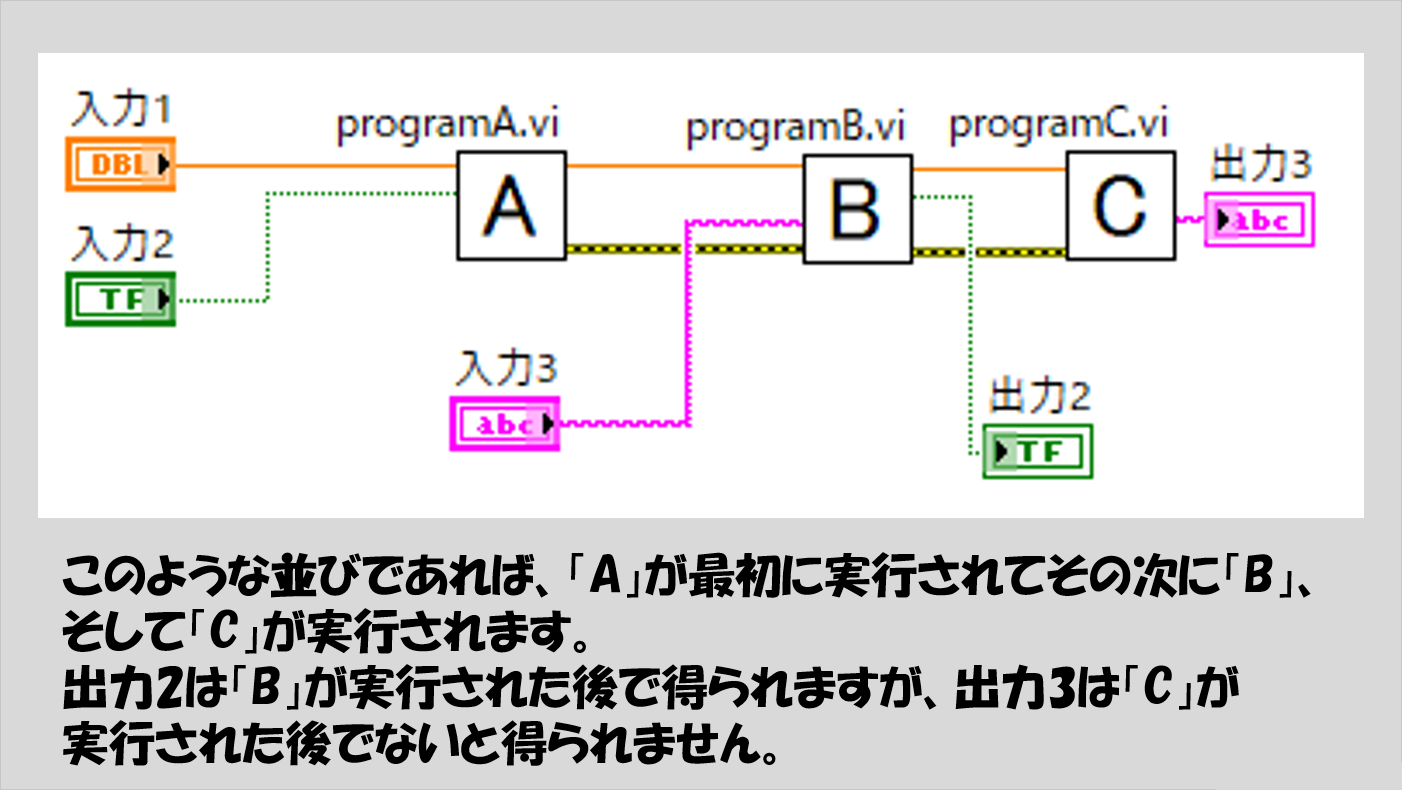
下の図の場合、実行される順番は「A」、「B」、そして「C」の順番です。理屈は上と同じで、入力がそろってからじゃないと実行されないものの、入力が揃うために他の出力が必要な場合にはその出力を待ってからでないと処理されないため、前後関係が生まれることになります。
では、以下の図のような場合ではどうか、というと、実はここで「実行順番が決まらない」ケースが出てきます。
具体的には「C」と「A」や「B」の実行順番の前後が決まりません。
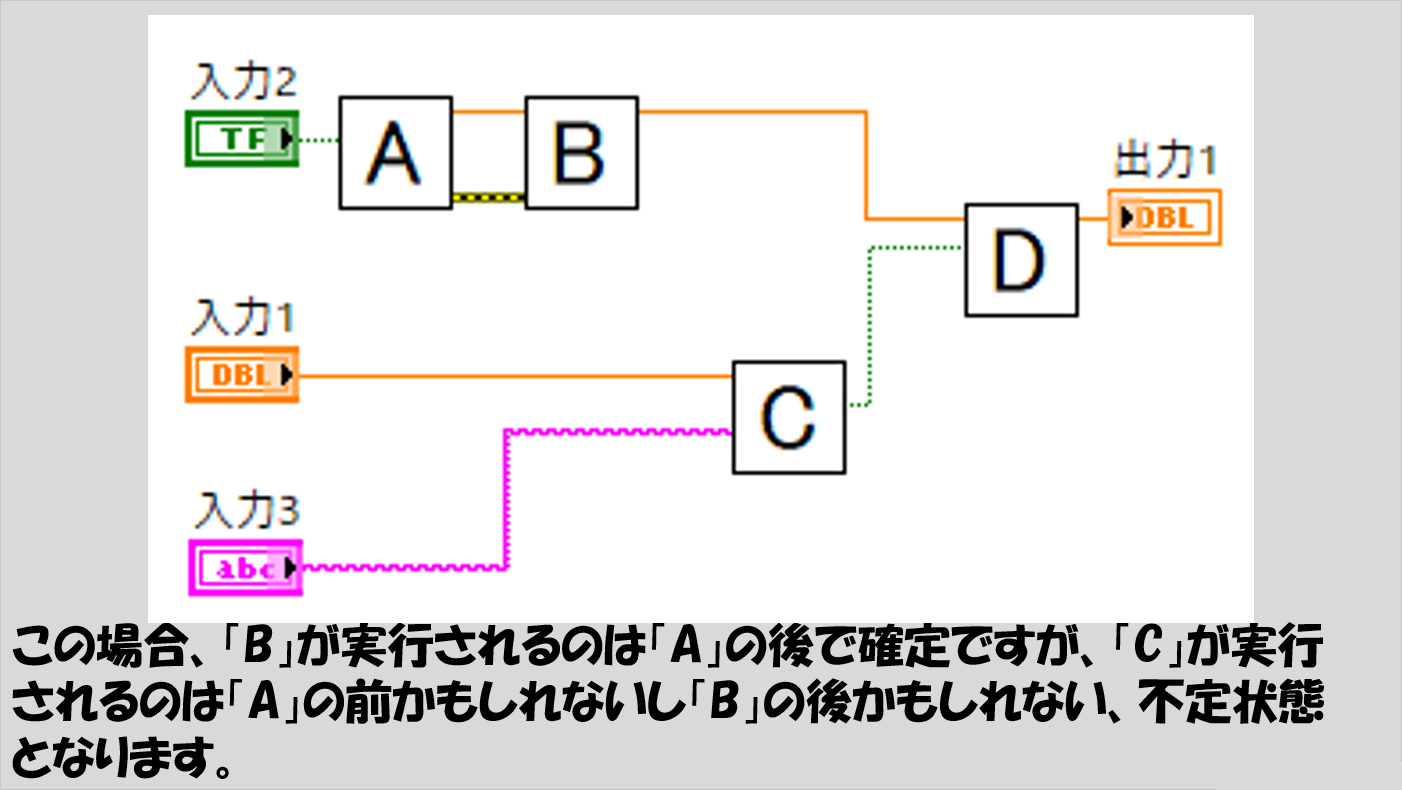
上の図で、「A」や「B」が「C」よりも左側に書かれているから「C」は「B」よりも後だ、という判断にはなりません。
あくまで、入力が揃ったら実行されるというルールで考えると、「C」は「A」や「B」の処理と独立しているため、いつ実行されるか不確定になっています。
なので、あくまで上の図で順番が確定しているのは「「A」の後に「B」」ということと、「「B」や「C」の後に「D」」ということだけです。
一方で、以下のようになっていたら、すべての順番が確定します。
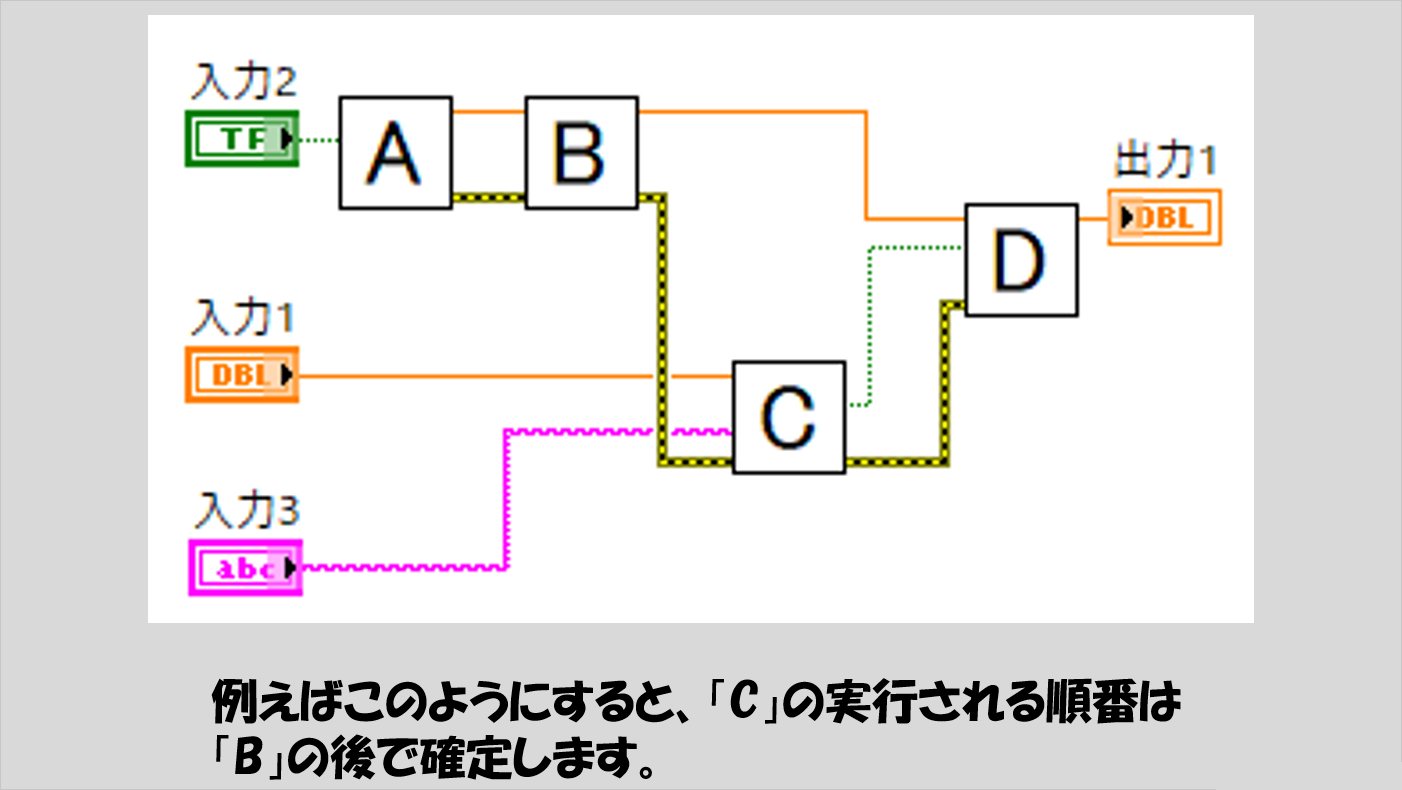
最後のは少しひっかけ問題っぽくもありましたが、実際にはLabVIEWではこのような最後に紹介した「実行される順番が確定しない」ような書き方をするケースがよく表れます。
「え、そんなの困るじゃん」と思うかもしれませんが、よくよく考えると実際には困りません。そもそも依存関係(ある処理の結果を使って別の処理を行う)場合には先行処理の出力を後続処理の入力に渡すことで実行順番が確定しますし、依存関係がないのであれば、実行の順番なんて気にする必要がないのです。
いや、正確に言うと一部の場合では実行順番を確定させる書き方が(それ単体では)できないにもかかわらず順番を確定したい場合もあるのですが、そんなときには工夫して順番が確定するようにプログラムを書くだけです(黄色いワイヤである、エラーのワイヤを使って順番付けをすることが多いです)。
なぜ実行される順番が確定しないような書き方がされるか、についてはどちらかというとプログラムの書き方の話になるので深くは紹介しませんが、端的に言うと「並列で実行させるため」、という理由になります。
実は、このような並列処理を実装しやすいのがLabVIEWの大きな利点の一つになっています。なので、プログラムを読むときにこの部分は特に注意します。
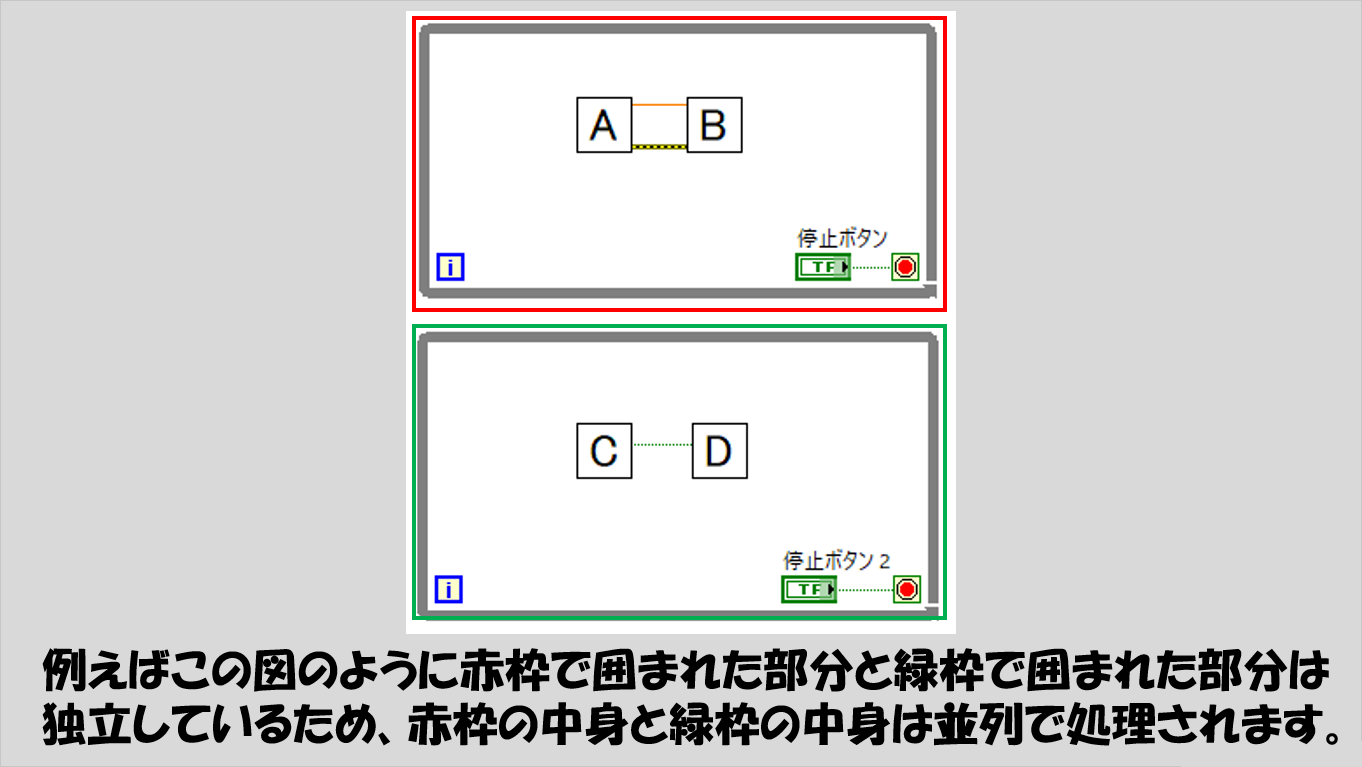
この図で、赤や緑の枠で囲っている部分はそれぞれ何の入出力のやりとりもないため、独立して実行されます。
この赤枠や緑枠の中の、グレーの囲みについてはすぐ次で紹介します。
最後に大事なことを一つ。これまでの説明で「入力値が全てそろってから処理が実行され結果が出力される」ということは何となく理解できたかなと思うのですが、そもそもある処理に対し何が入力値となって何が出力値になっているかはどうやって見分けるんだ?と点に関して補足します。
これは簡単で、Ctrl + Hで詳細ヘルプを見たときに、左側に書いてあるのが入力、右側に書いてあるのが出力です。
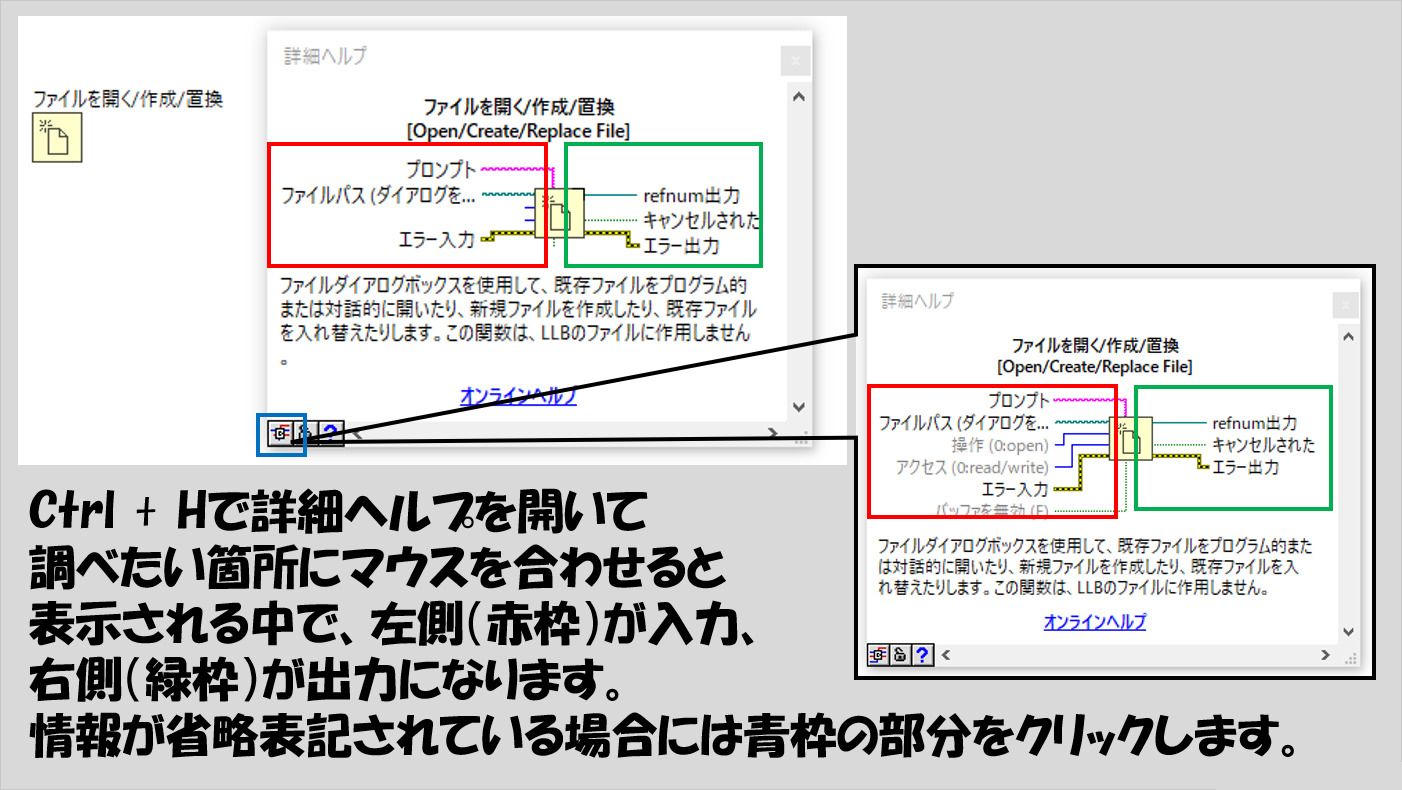
こうしてみると、基本的に全てが(ごく一部に例外はあるのですが)入力はアイコンの左側に固まっていて、出力はアイコンの右側に固まっていると思います。
これが、大雑把に説明した「構成を全く考えないで各制御器や表示器、関数などのアイコンをむちゃくちゃに配置しない限りでは、左から右に実行され」る理由です。
アルゴリズムに関する表記方法を知る
データの流れはワイヤ配線で決まっていて、すべての入力がそろってから出ないと処理がなされず結果も出ないことを紹介しました。
ただ、このデータの流れの原則だけ理解すればじゃあプログラムを読めるのかというとそうではありませんね。
データの流れを知っても、各処理で何がなされているかも知らないと意味がないです。
何らかの機能をもって、入力値に対して出力値を生むものは関数とかノードなどと呼ばれます(先ほどの順番を説明した部分での「A」や「B」などと書いていた部分です)が、これらは詳細ヘルプを見る事でどのような入力を必要としてどのような処理をしているか、どのような結果を得られるかを調べることができます。
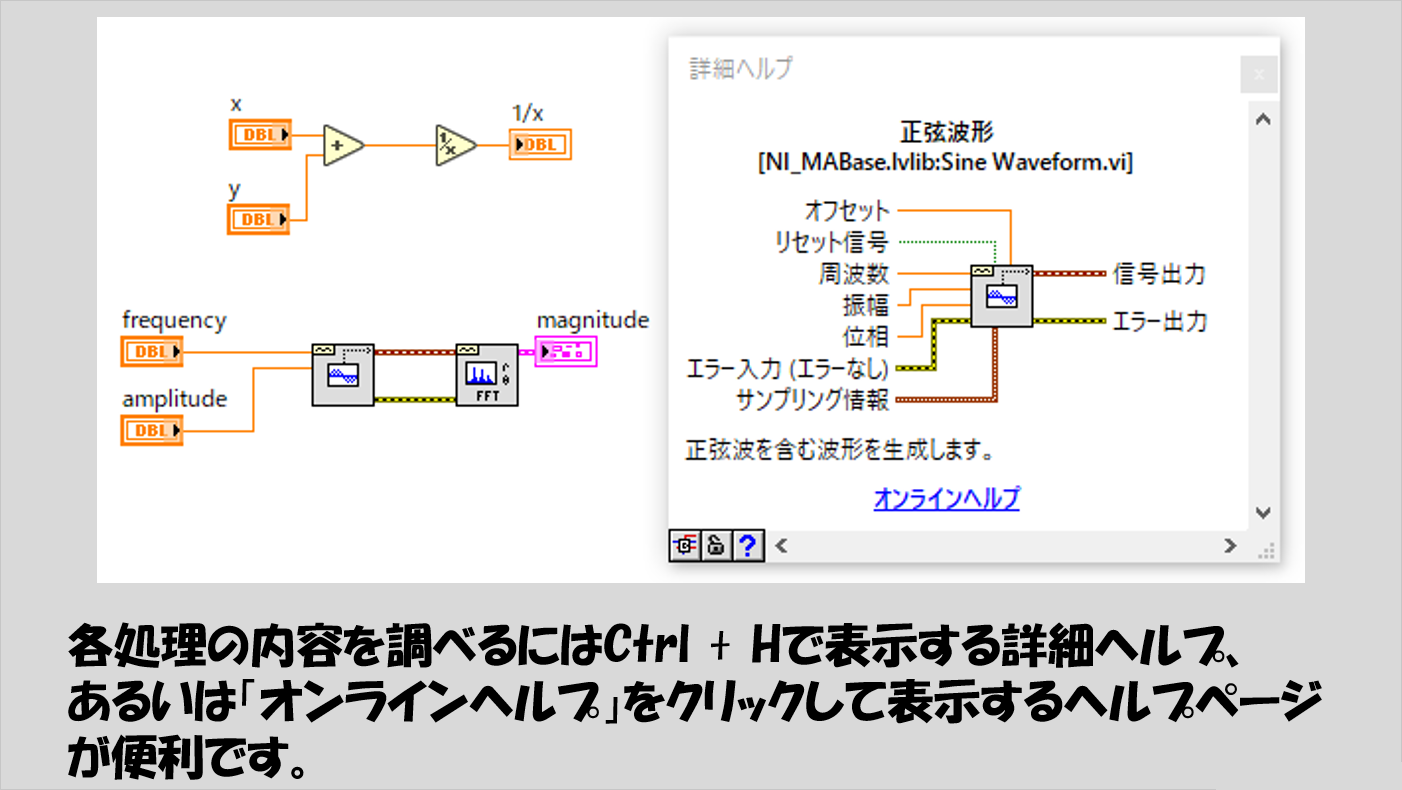
しかしLabVIEWプログラムの中には関数やノードばかりではなく、アルゴリズムに関係する表記も数多く見られます。プログラムを読み解くためにはこれらの意味も知っておく必要があります。
最低限、これらの意味は分かるようにしておくといいと思います。
- Whileループ/Forループ
- ケースストラクチャ
- イベントストラクチャ
- 無効ストラクチャ
アルゴリズムに関係するものは他にもありますが、とりあえず上の4つはどんなことを表しているのかを理解しておくといいと思います。
ただし、これらはまともに説明しようとすると奥が深いものばかりなので、本記事では「こんな表記があったらこんな意味です」という紹介にとどめています。
その処理についてさらに詳しく使われ方を知りたいという方のために、対応する「まずこれ」のシリーズの記事のリンクもはっているのでよかったら参考にしてみてください。
Whileループ/Forループ
これは、他のプログラミング言語でも同じ名前で登場すると思いますが、他の言語同様、繰り返し処理を表します。
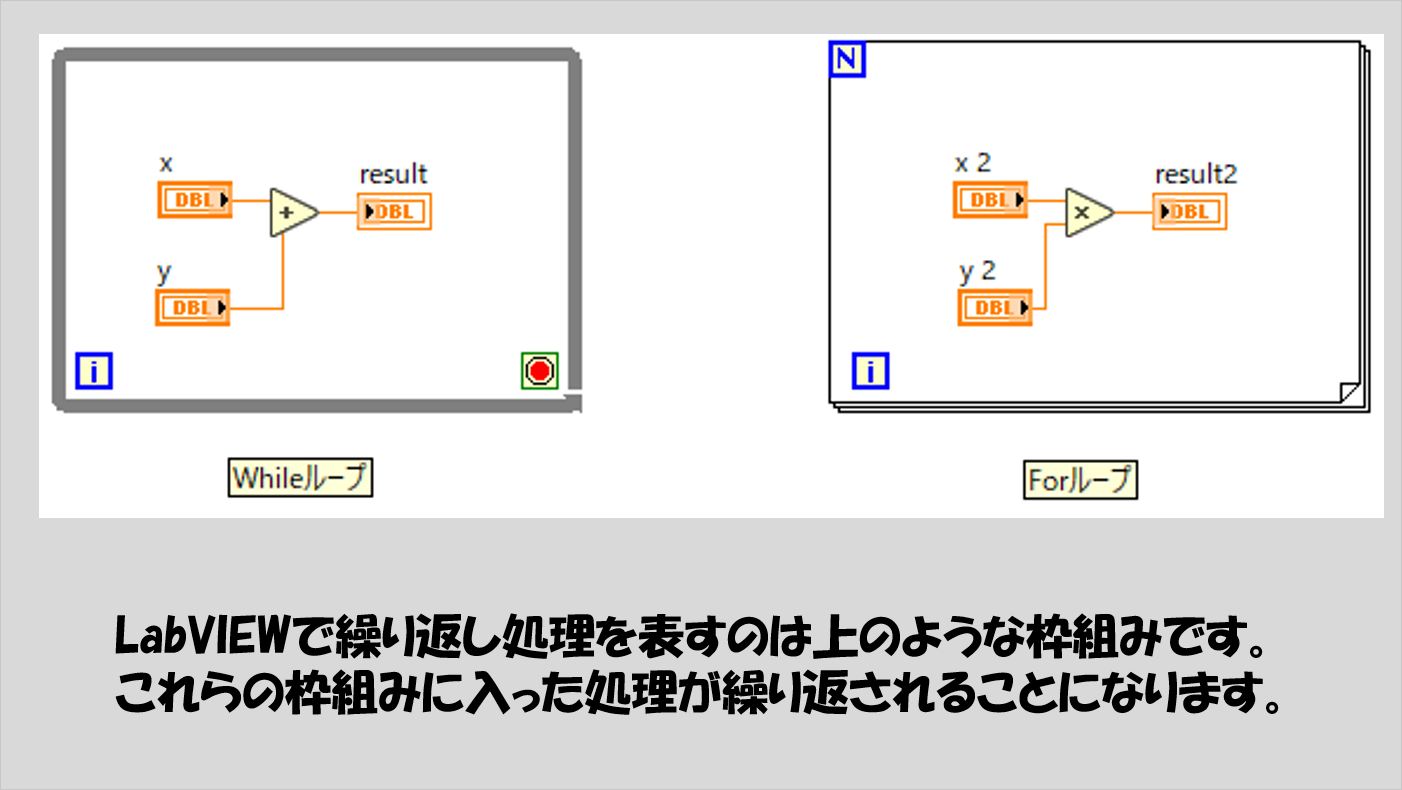
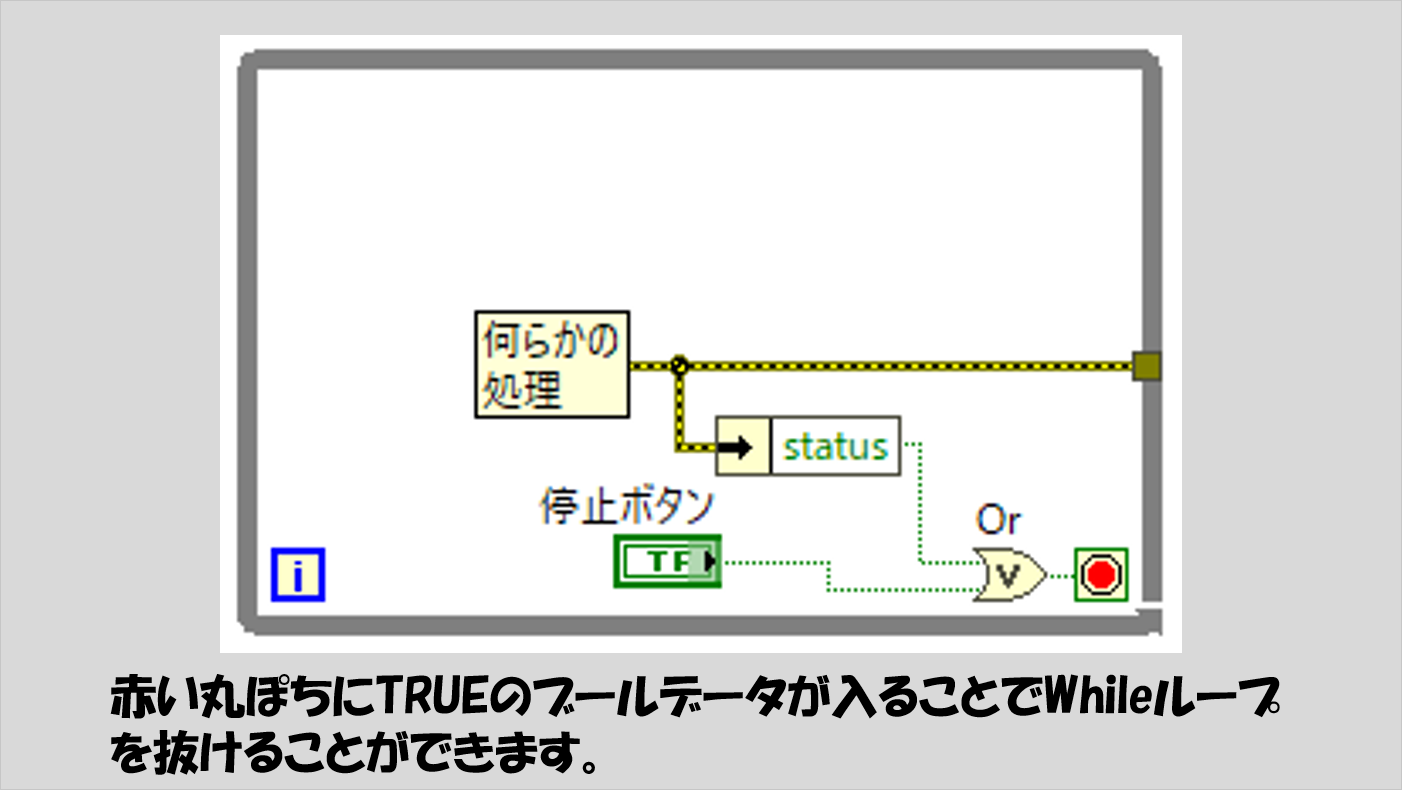
Whileループの場合、赤い丸ぽちの部分にTRUEのデータが渡された場合に繰り返しを止める、という動作になります。
なので例えば以下のようなプログラムになっている場合、
- 停止ボタンが押された
- エラーが出た(エラーステータスがTRUEとなった)
場合にWhileループが終わりますが、上記の二つのいずれかが検出されたとしてもその回の実行はされることになります。言い換えれば、Whileループは最低限1回は必ず実行されます。
一方Forループでは、回数を指定してその回数分の繰り返しが終わったら処理を抜けます。

また、中にはWhileループ同様、赤い丸ぽちを付けることもでき、ここにTRUEが渡されると規定回数の繰り返しが終わっていなくても強制的に繰り返しが終わります。

また、Whileループ、Forループに共通して入力と出力には大きく分けて二つの種類があります。それは以下の図で示した自動指標付けの有効/無効の設定で、簡単に表現すると無効の場合にはスカラー値を、有効の場合には配列を扱うことができます。

上の図で、Forループに回数の指定がないのですが、このForループはある決まった回数回ることになります。それは、「配列2」と書かれた、自動指標付け有効の入力トンネルに配線された配列の要素の数と一致します。
この書き方は、Forループの回数を最初から決めるのではなく、プログラムの処理の結果次第によって回数が変わるような場合に有効な書き方になります。

また、これらとは別に、シフトレジスタという機能もあります。簡単に言えば、特定の結果を次の繰り返し時に使用したい場合に使用できるようにするための機能です。
例えば、下の図の左にあるWhileループでは、N回目の段階で得られている「数値」がN+1回目に「数値2」として取り出せます。そしてWhileループが終わったら、「出力」には最後に「数値」に書いてある値が表示されます。
下の図の右にあるForループでは、Forループの一番最初の実行で「ブール2」からは「最初の値」が出ることになります(これをシフトレジスタの初期化と言います)。
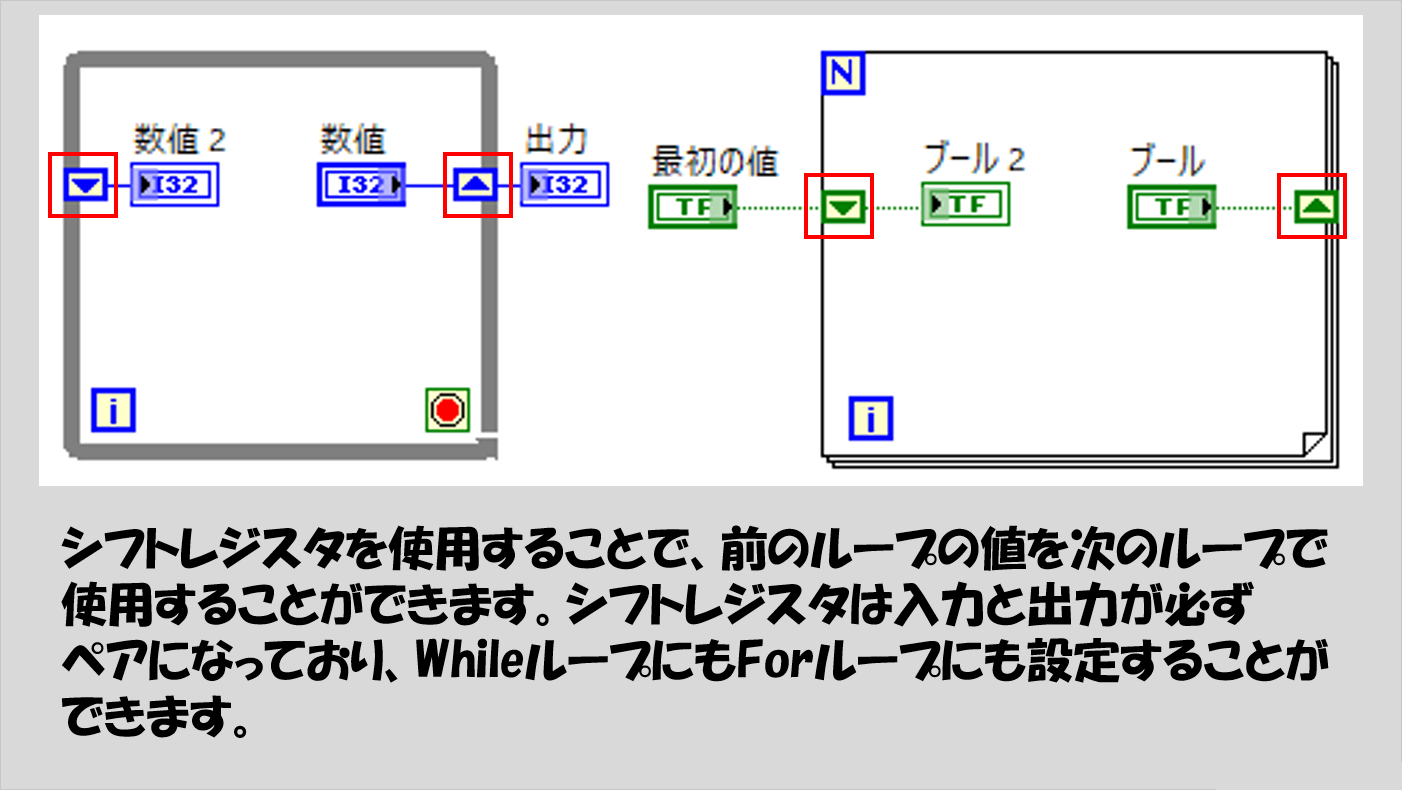
WhileループやForループに関しては最低限これらのことは覚えておく必要があります。
もしここで紹介した内容(特に最後の方の、トンネルの種類とシフトレジスタ、初期化の話など)についてもう少し具体的に知りたい場合には、LabVIEWでプログラムを書く方向けに書いた記事ですが、以下が参考になると思います。
ケースストラクチャ
こちらはいわゆる条件分岐を表しています。
読み方は簡単で、入力された値によってどのラベルの中の処理を行うかを判断させる分岐処理が行えます。
以下の例でいうと、「数値」の値によって、それが「1」か「0やそれ以外」で処理が変わることになり、数値が「1」ならx2とy2の引き算を、数値が「5」であればxとyの足し算を行っていることになります(「デフォルト」とは、定義されていない値が入ってきた場合に実行される項目名になります)。
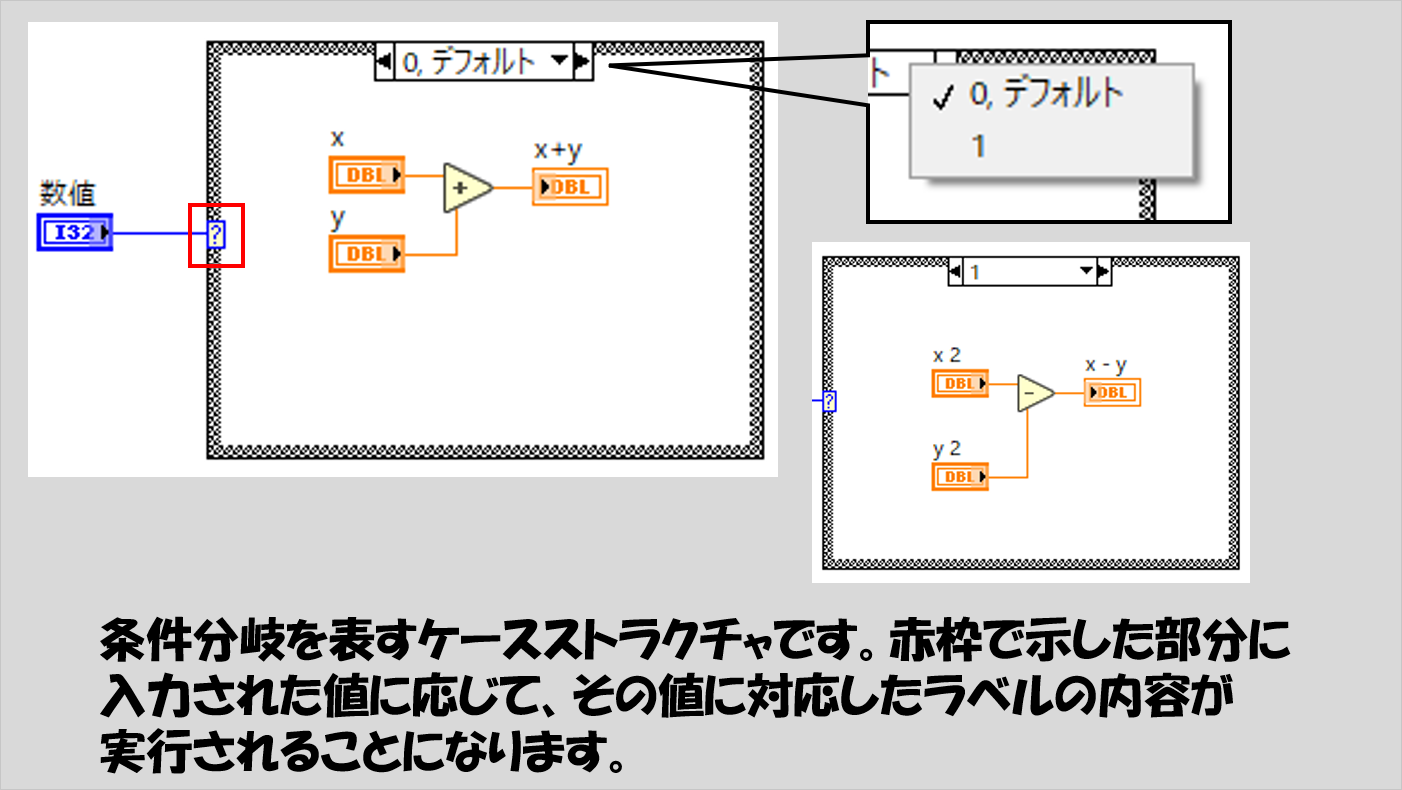
プログラムの中では、このラベル内に記された処理を実行することになります。
ラベル、つまり分岐の数はいくらでも増やすことができます。
また、条件分岐の判断材料となるのは数値だけでなく、以下の図のような文字列やブール、エラー情報なんかも使用することができます。

こちらももう少し他の例も知りたいということでしたら以下の記事を参考にしてみてください。
イベントストラクチャ
ユーザーがフロントパネル上のボタンを押したり何か文字や数値を新たに入力したということを「イベント」として検出し、そのイベントの種類によって処理内容を変えるための方法がイベントストラクチャです。
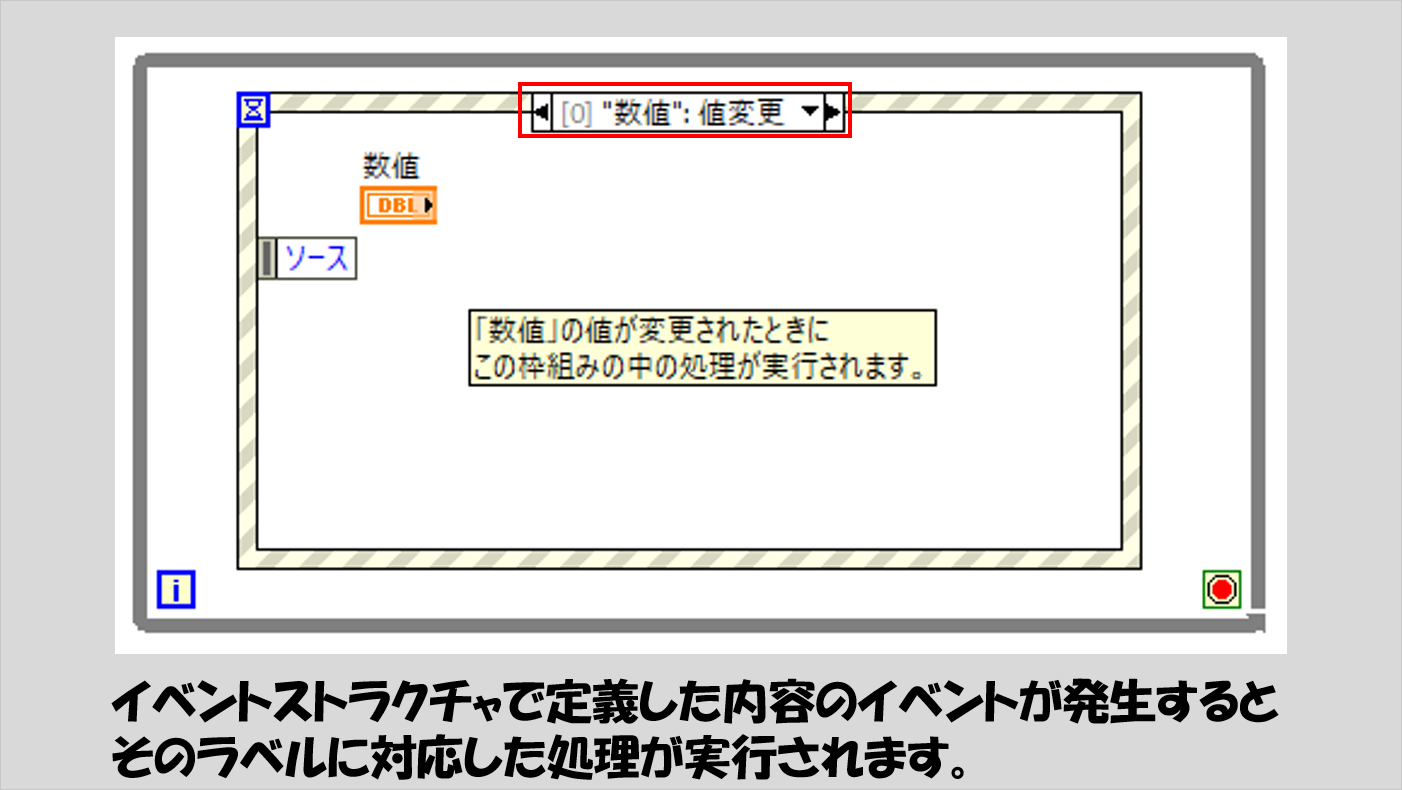
もし以下の図のような表記を見かけたら、それはイベントを検出しようとしているのだな、と考えます。
なお、以下の図の例では、「数値」の値が変更された際に、この黄色の枠組みの中の処理を実行することになります。
ケースストラクチャ同様、イベントも複数設けることができます。
イベントはかなり種類があるのですが、よく使われるのは限られ、その中でも何かしらのデータの「値変更」イベントは最もよく使用されます。
この内容については以下の記事を参考にしてみてください。

無効ストラクチャ
上で紹介した3つほどは頻出ではないと思いますが、無効ストラクチャというものもあります。これはいわゆるコメントアウトに相当します。
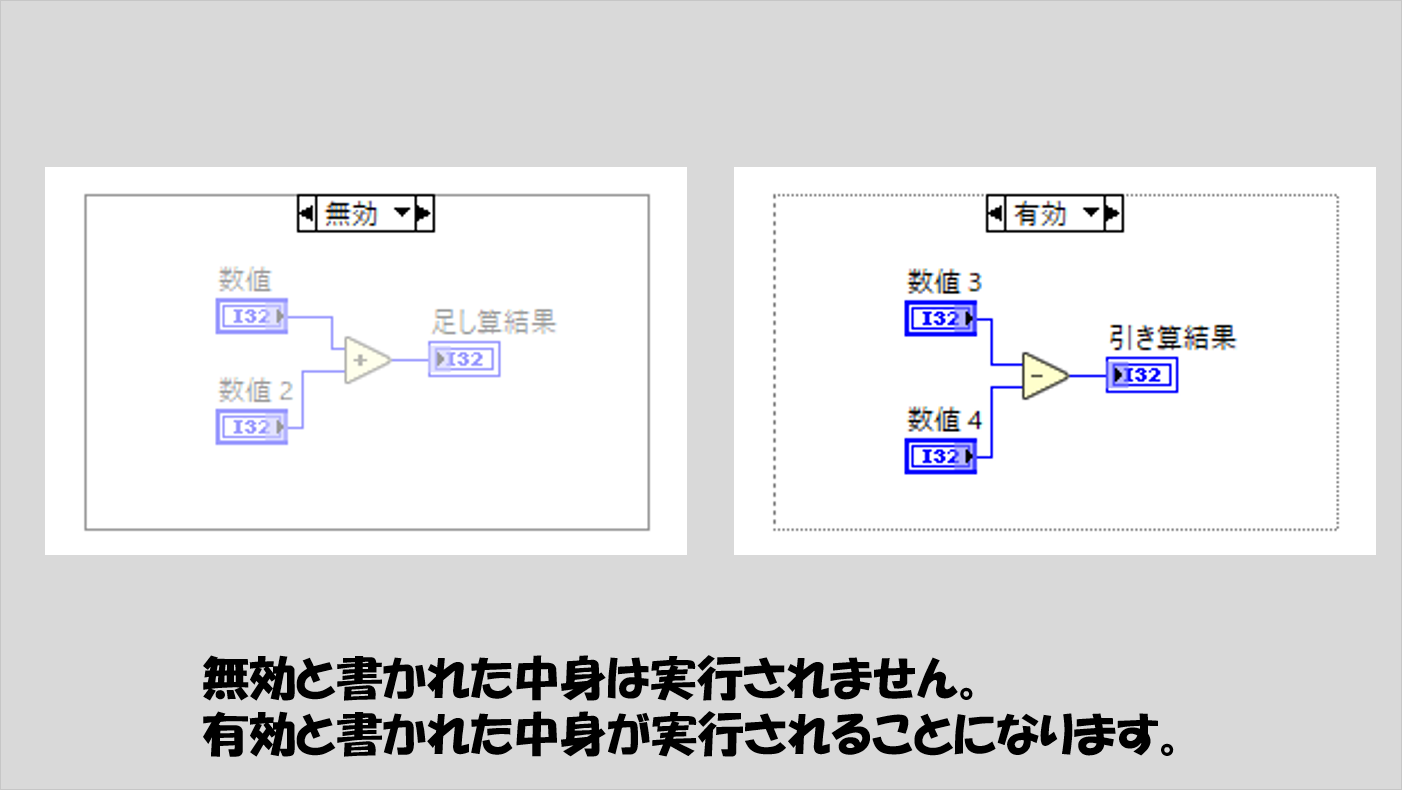
有効、と表示されている場合その中の処理は実行されるのでそこは注意が必要です。
こちらについては特に紹介記事は他にありません。上で紹介した通り、「無効」と書かれた中身はプログラム実行中に処理されないだけ、ただそれだけのことです。
変数について
他のプログラミング言語でもあるように、LabVIEWでも変数というものが存在します。
ある特定の値を一時的に保存したり、その保存した値を取り出して使用するための仕組みで、見た目としては以下のような見た目をしています。
ローカル変数は家のような図が、グローバル変数には地球のような図が、それぞれ描かれています。

各変数は、データを共有できる範囲が異なっていて、ローカル変数は同じVI内でしか共有できず、グローバル変数はVIをまたいでデータを共有できます。
ただし、LabVIEWプログラムでは、うまい書き方がされている場合には変数はそれほど多く登場しません。言い換えると、プログラム全体の設計次第で基本的には変数を使用しなくても書ける、ということです(例外的に使用するケースはありますが)。
なので、不必要に変数が多用されているプログラムは、あまり効率を重視していないとか、以下で紹介する典型的な書き方に沿っていないプログラムになっているという可能性があります。
なお、「変数」と名の付くものは他にもシェア変数というものがあり、これは「異なるPC間でデータを共有する」ことができるものです。この変数については他で代用が効かない(全く代用が効かないかというと、PC間でデータを共有する仕組みは他にもありますが)ため使用することがあるものの、扱いが高度なので本記事では割愛します。
変数について興味がある、ということでしたらまずこれのシリーズの記事も参照してみてください。
典型的な書き方に沿ったプログラムの見方
プログラムの流れを追えるようになり、各関数の処理を詳細ヘルプやヘルプで調べ、各種アルゴリズムの表記方法もわかるようになれば既存プログラムを読める基本的な準備は整ったと言えます。
ただ、より簡単に読めるようになるための方法というものがあって、それが「典型的な書き方」を知ることです。
LabVIEWにはプログラムを書く際によく使われる典型的な書き方があり、これはデザインテンプレートと呼ばれています。
もしプログラムがこのテンプレートに沿った書き方がされている場合には、ある程度決まった処理の流れがあるため、その通りの読めば理解しやすいということでプログラムを読み解きやすくなります。
私の知る限り、「良い」プログラムは得てしてこうしたテンプレート(またはその応用)に沿って書かれているものです。
もちろん、プログラムを書いた人の力量によってはその限りではないですけれどね。
ともかく、ここではそんなデザインテンプレートの代表としてステートマシンと生産者/消費者デザインの二つを紹介します。実際には他にもテンプレートは存在しますが、全くLabVIEWプログラムを読んだことがない、という方にとっては高度過ぎる内容になるので割愛します。
ステートマシン
この組み方は、プログラムで行っている処理がフローチャートで記述できるような流れを持っている場合によく用いられます。
「マシン」と名前がついていますが、何か「機械」とか「ロボット」みたいなものではありません。
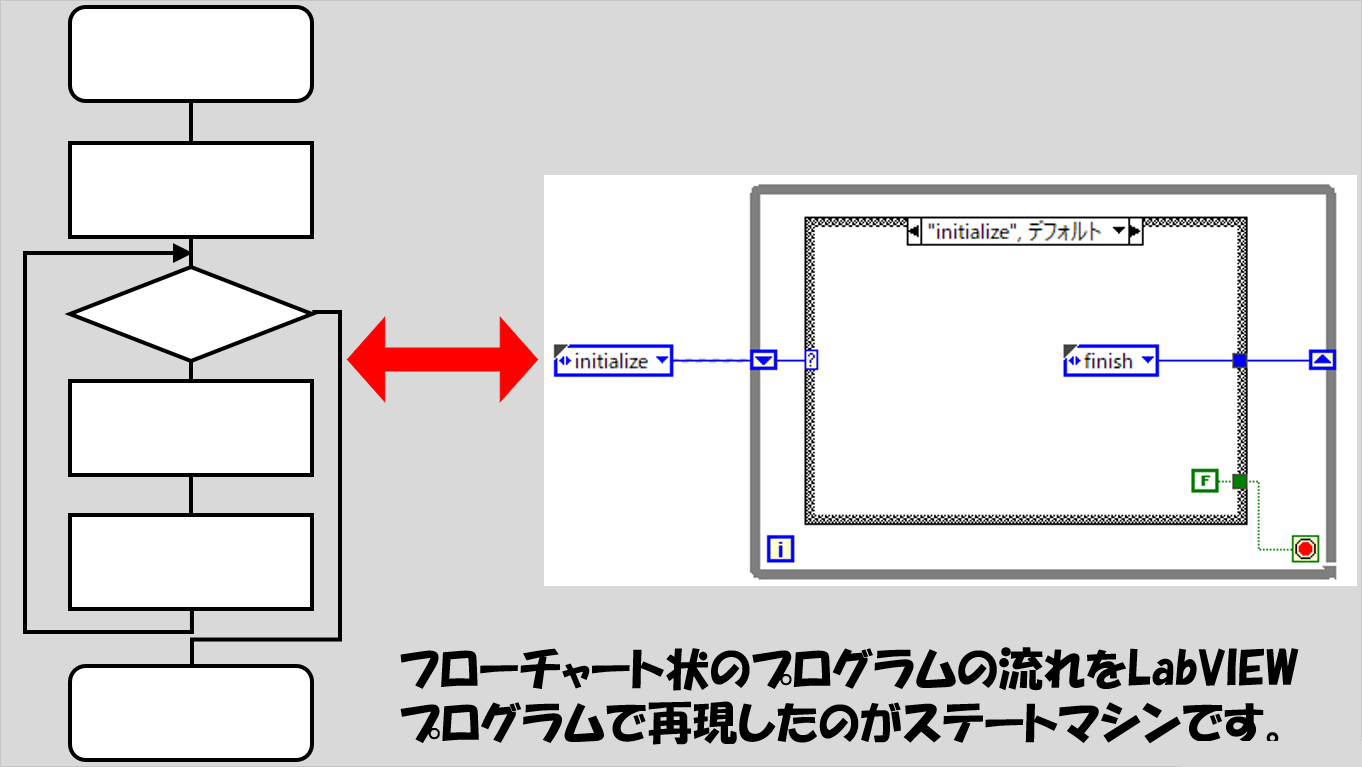
もし以下のような構造を持っていたら、ステートマシンで組まれているかもしれない、と思ってください。
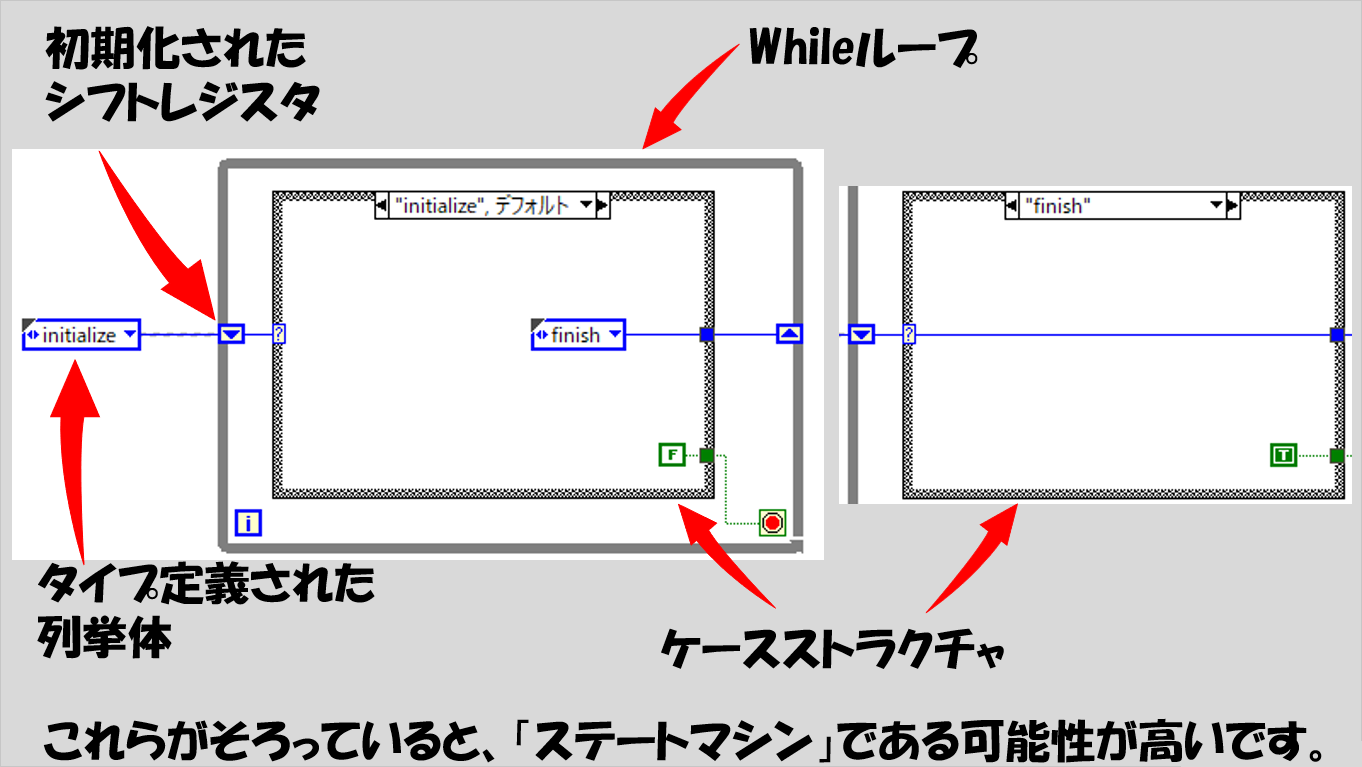
本記事で紹介していないのは「タイプ定義された列挙体」ですが、「列挙体」とはそういう名前のデータタイプ(項目を列挙しているのでそう呼ばれます)として考えてください。表示は上の図で示したような青色の表示しかないため、見た目で判断できると思います。
構造を大雑把に説明すると、
- Whileループでケースストラクチャ、つまり条件分岐の処理を繰り返す
- 各ループで、ケースストラクチャでどの処理が実行されるかは、シフトレジスタからの入力で決まる
- シフトレジスタは前のループの値を取得する機能になっているため、「前のループの処理の内容によって次のループでどの条件分岐の処理が実行されるかが決まる」ことになる
と言えます。
具体的なプログラムの例でステートマシンの流れを紹介しているので、もし読み方についてもっと知りたい!ということであれば以下を参考にしてもらえると思います。
生産者/消費者デザイン
こちらは、主にWhileループが複数ある場合にそれらのループ間でデータをやり取りするための仕組みです。
もし以下の関数が使用されていた場合にはごくごく一部の例外はありますが、基本的には生産者/消費者デザインが使われていると考えます。
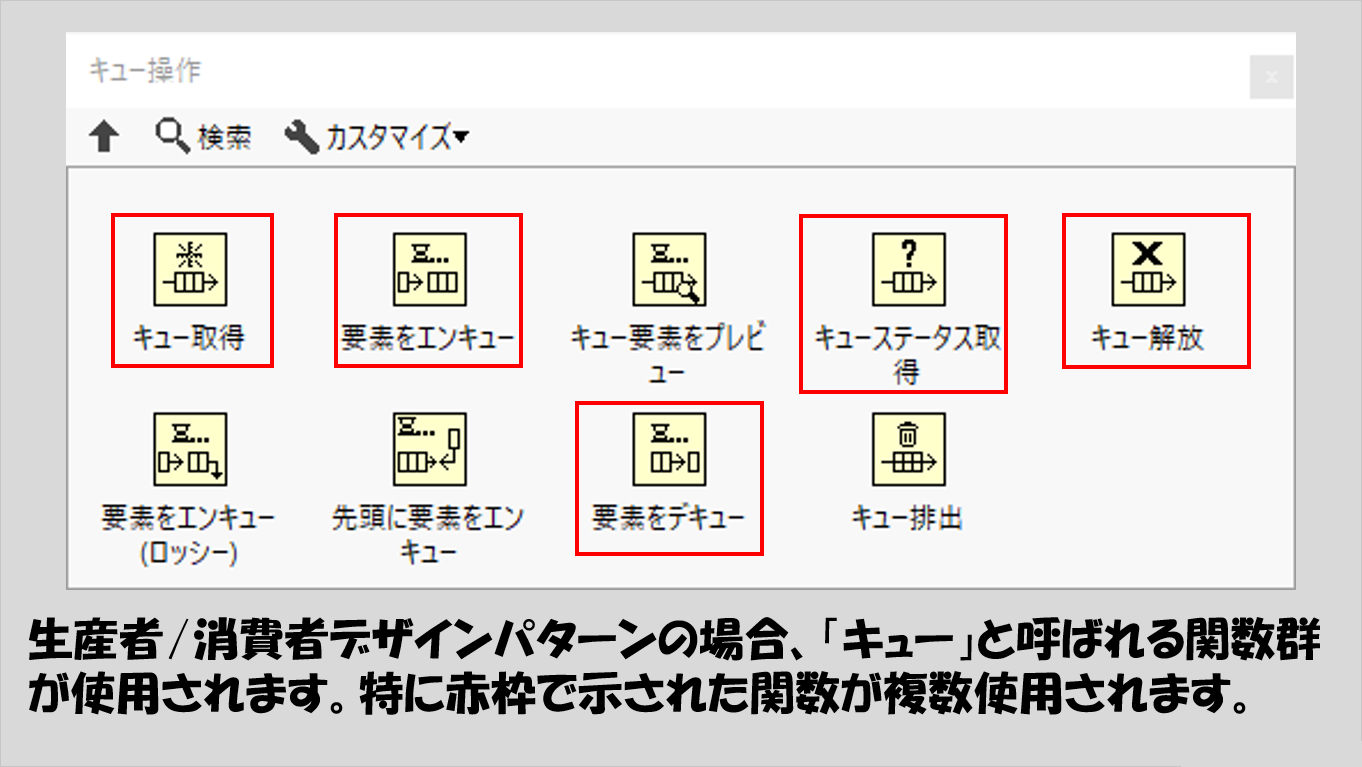
キューとは「並ぶ」という意味のqueueからきていて、その名の通り「データを並ばせてその並びにデータを追加したりデータを取り出したりする」仕組みを持ちます。
この説明に出てくる、データを並ばせている場所、というのが、複数のループから共通してアクセスできる場所になっています。そのため、複数のループ間でデータをやり取りするのによく使用されます。
典型的な形だと以下のような見た目をしています。
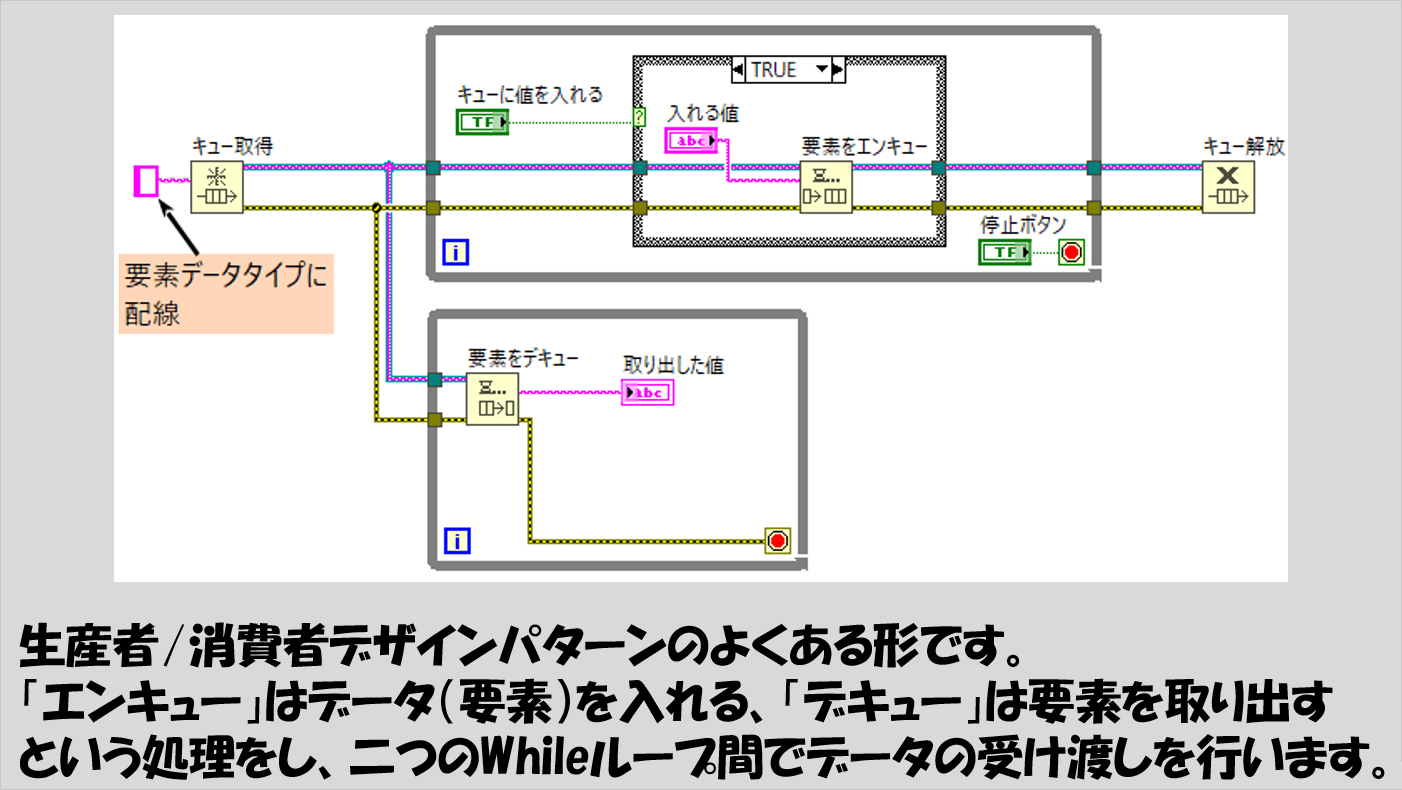
なお、一つのキューでは一つのデータタイプしか扱えません。
複数のキューがある場合には、どのキューでどのデータタイプが扱われているかを見極める必要がありますが、キュー生成の関数に入力されているデータタイプが、Whileループ間でやりとりされているデータタイプに一致します。
なので上の図のプログラムの例では文字列データがWhileループ間でやり取りされていることになります。
生産者/消費者デザインはループ間でデータを受け渡ししているんだということさえ覚えておけばなんとかプログラムを読めると思います。
とはいえそれぞれの処理の中身についてさらに知りたいという場合には以下の記事も参考にしてみてください。
他にもデザインパターンとして有名なのはキューメッセージハンドラというデザインがありますが、このレベルになると、全く引継ぎを行わないで初心者の方が一から読み解くという場面はそうそう起きないと思います。
ただ、「まずこれ」のシリーズでは、このキューメッセージハンドラのデザインを読み取くための解説記事も出しているので、理解するにはすべての記事を読まないと難しい(読んでも難しいかもですが)ので、困ったら覗いてみてください。
LabVIEWプログラムを読み解く上で必要な知識について紹介してきました。本来はもっと知っておいた方がいい用語や使い方などはたくさんありますが、読み取ってどういったことが行われているかを理解するための最低限の知識を挙げてみたつもりです。
なので本記事で扱った内容くらいは一通り雰囲気をつかんだうえで、実際に読み解きたいプログラムの中身の解読にチャレンジしてみてください。
ここまで読んでいただきありがとうございました。
コメント