LabVIEWを触ったことがない方に向けて、それなりのプログラムが書けるようになるところまで基本的な事柄を解説していこうという試みです。
シリーズ13回目として複数のデータタイプをまとめたデータタイプ、クラスタについて紹介していきます。
この記事は、以下のような方に向けて書いています。
- データタイプをまとめるにはどうすればいいの?
- クラスタに対するバンドル操作の違いは?
- クラスタって何のためにあるの?
もし上記のことに興味があるよ、という方には参考にして頂けるかもしれません。
なお、前回の記事はこちらです。
複数のデータタイプをまとめて扱う(クラスタ)
唐突ですが、ここまでの内容でこんなことを思った方もいるのではないでしょうか?「配列は一つのデータタイプしか扱えなかったが、複数のデータをまとめてひと固まりに扱うにはどうすればいいのか?」と。
実際複数のデータタイプをまとめることができれば、関連したデータどうしをまとめて扱うことができるのでプログラムがとても見やすくなります。
関連したデータ同士って何のこと?と思うかもしれません。例えば個人情報をイメージしてください。これは住所と氏名と年齢と電話番号がセットになっていると考えたら、これらがバラバラに存在しているより、これらのセットが「個人情報」として固まりであった方がわかりやすいと思いませんか?
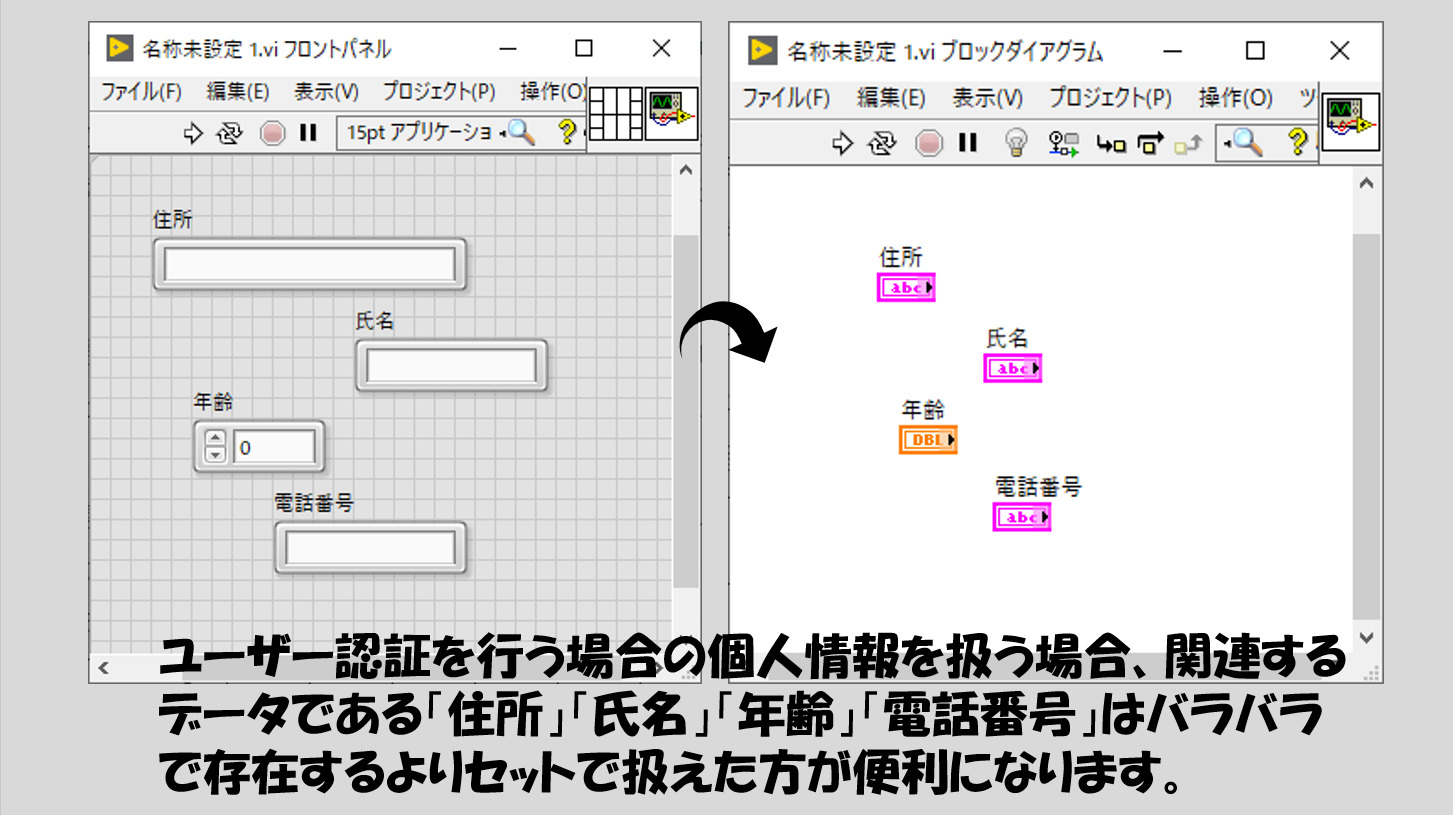
個人情報を扱うプログラムなんて組まないよ、という方もいると思いますが、例えば何かユーザーを認証させるプログラムを使用するのであれば機会があると思います。
別に複数種類のデータタイプでなくても、何か制御対象に対して「加速度X」「加速度Y」「加速度Z」といった具合に関連したデータをまとめて扱う様な機会は意外と出てくるものです。
いやむしろ実は既に話が出てきた中で便利な例が一つあります。黄色のワイヤで渡される、エラーの情報のことです。既にプログラムを作っていてエラーが出たという方もいるのではないでしょうか?
身近なのでこれを例に説明していきましょう。ということでエラーの表示器を見てみます。
フロントパネルでエラーの制御器あるいは表示器を表示させます。すると、3つのデータタイプ、ブール、数値、文字列がセットになった表示器が用意できると思います。
このような、複数のデータタイプをまとめたデータタイプを、クラスタと呼んでいます。他言語では構造体と呼ばれているものに対応しているかと思います。
エラーの情報がまとまったものは特にエラークラスタと呼んでいるのですが、エラーの情報は、以下のようになっていたのを覚えているでしょうか?
- ステータス:ブールデータでエラーが起きたのかをTRUE、FALSEで表示
- コード:I32の数値データでエラーの番号(エラーコード)を表示
- ソース:文字列データでエラーの発生個所を表示
ただしブールがFALSEでもエラーコードが0でない数値になっている場合があり、これは「警告」(プログラムは動作しているが、意図した動作になっていない可能性がある)を表しているのでした。
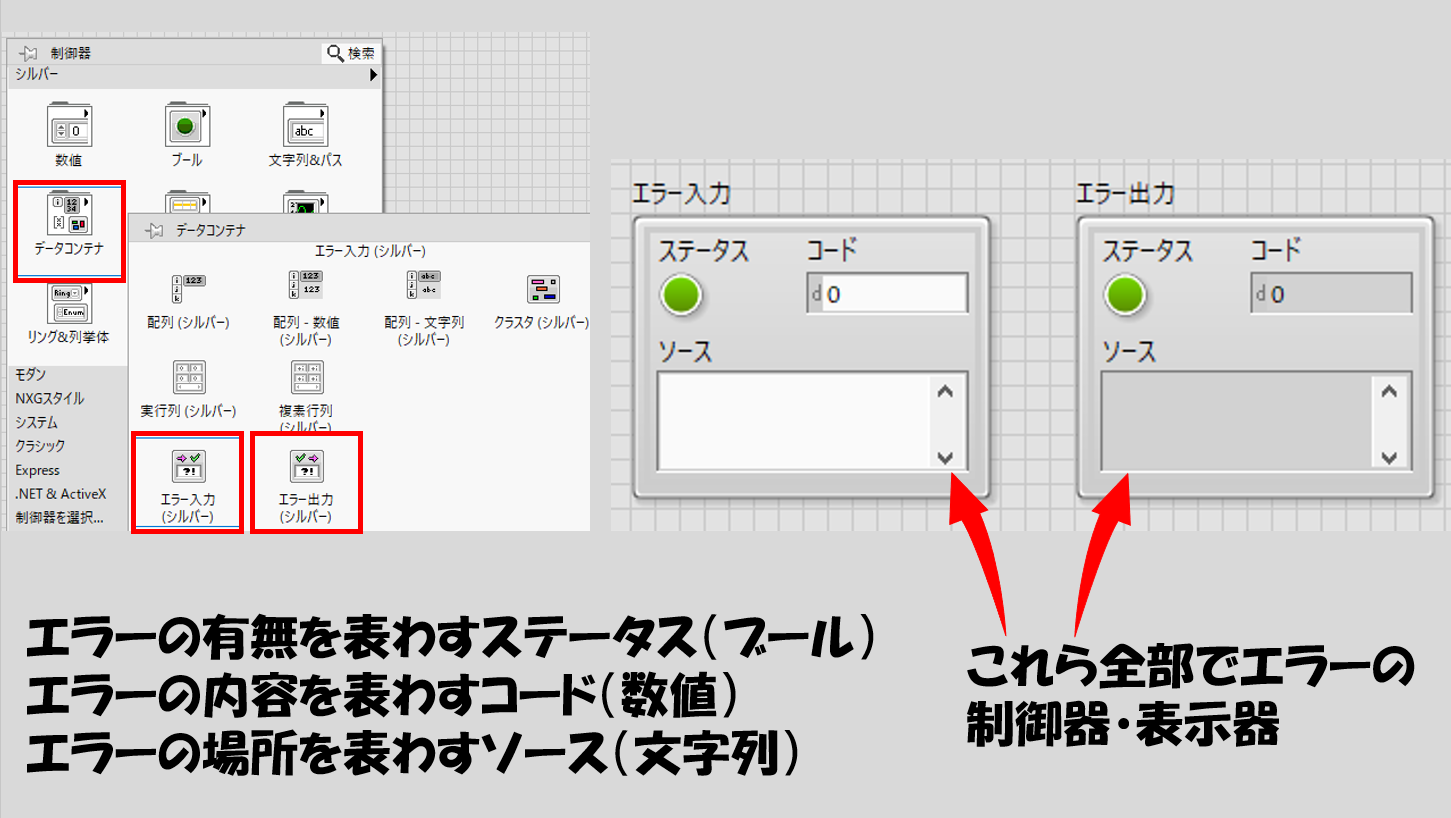
エラーについて3つのデータタイプで知らせて「どういったエラーがどこで起きたか」など分かりやすい状態としています。
このクラスタというデータタイプは自由に作り出すことができます。個人的には、既存のデータタイプを組み合わせて新しいデータタイプを作り出す、という感覚を持っています。
クラスタの作り方
実際にクラスタを作ってみましょう。方法は、配列を作る時と似たような流れで、まずは空のクラスタを用意します。あとは、そのクラスタに入れたいデータタイプの制御器あるいは表示器をフロントパネルに用意して、一つ一つドラッグアンドドロップでクラスタ定数の中に置くだけです。

クラスタの中に含めたい項目を入れてから、クラスタの枠を右クリックして「自動サイズ調整」を行うと、項目が枠からはみ出していても調整されます。

クラスタは複数のデータタイプをいくらでも内包することができるのですが、通常見やすさや実用性を重視すると要素を10以上持つことはないと思います。
また、あまり意識する場面は少ないかもしれませんが、クラスタ内のデータタイプは、クラスタ内で番号を持ちます。クラスタ作成時においた項目の順番と対応します。
配列の指標番号みたいに番号で何かデータを指定するわけではありません。この番号は、クラスタ内部のデータを抜き出す際に上から順番に表示される順番に対応します。そのため、見た目が全く同じでも、内部的な番号が異なるクラスタは別のクラスタであると認識される点も注意が必要です。
クラスタは表示をさせればフロントパネル上で中身は見えるのですが、ブロックダイアグラムではクラスタ用の端子の形をしています。この場合、詳細ヘルプを使用するとブロックダイアグラムからでも中身を確認することができます。
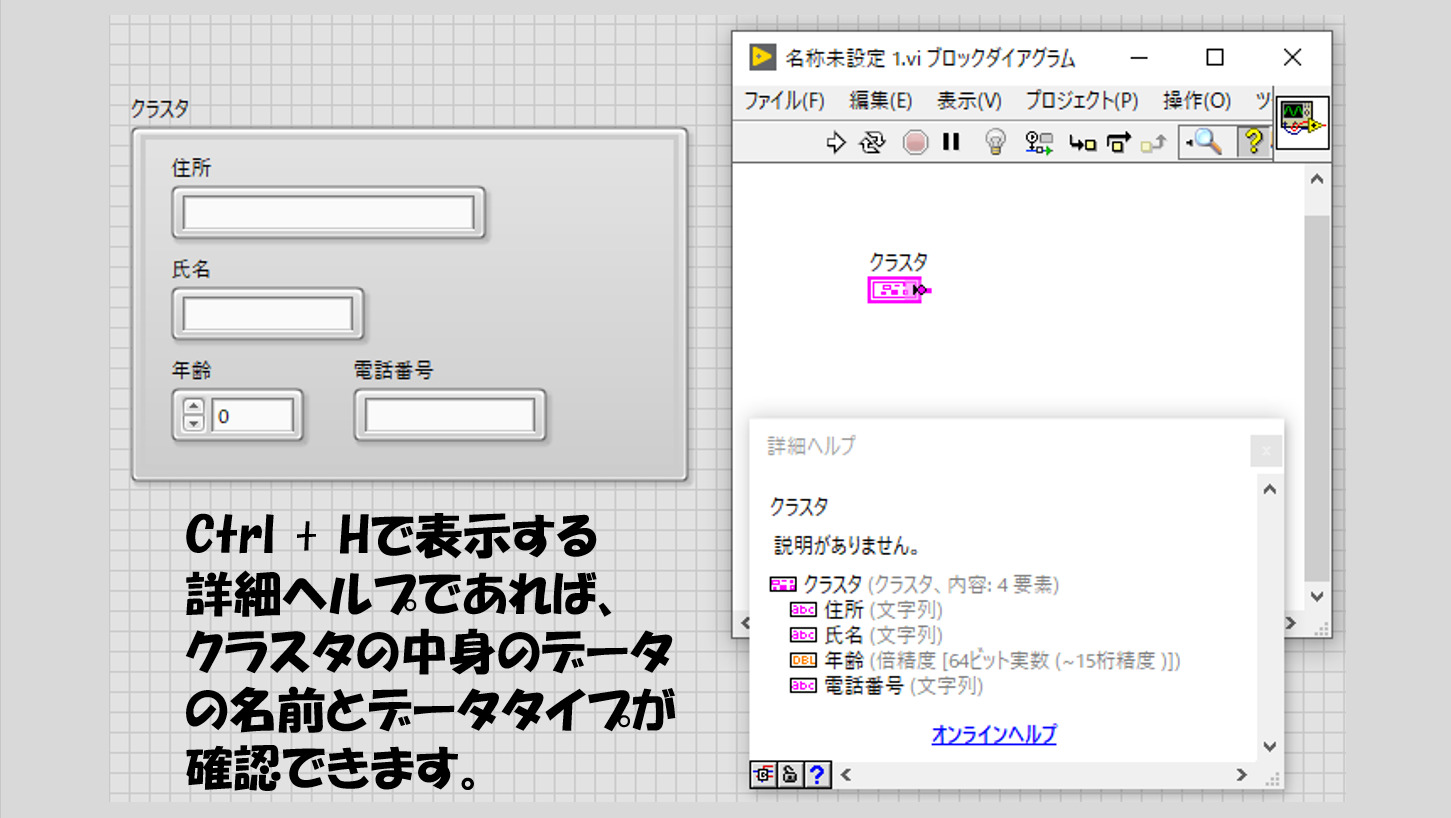
また、クラスタはクラスタ自身も含め様々なデータタイプを扱えるのですが、それ自体も制御器、表示器という概念を持つ関係上、「制御器と表示器が入り混じったクラスタ」を作ることはできません。

ちなみに、クラスタのデータタイプの色について特に紹介していませんが、それは中身のデータタイプの組によって色が変わりうるためです。色は変わるのですが、「クラスタ」としてのブロックダイアグラム上の端子の姿は似ています(とはいえデータタイプの組が異なると完全に同じではありません)。
以上がクラスタデータタイプの基本的な性質になります。
さて、クラスタとしてまとめたはいいものの、ブロックダイアグラム上でも「クラスタ」の端子しか表れておらず、これではクラスタの中身のデータを操作することができませんね。
そこで使用するのがバンドル系の関数です。
クラスタ内のデータを取り出す
早速まずはクラスタのデータの抜き出しをしていきます。クラスタに入っている特定のデータの値を読み出す(出力させる)、ということです。
どんなクラスタでもやり方は同じなので、ここでは皆さんも共通したものとして試せるようにエラークラスタを例として用います。抜き出し方は大きく二種類あり、
- 制御器あるいは表示器の名前で抜き出す
- 名前は関係なく順番で抜き出す
といった方法があります。何のことだか分からないと思うので、実際にどういう画面になるかそれぞれ見ていきます。
エラークラスタに限らず、すべてのクラスタはバンドル解除という関数を使って、クラスタの中の要素を分解します。束(=バンドル)になっている状態を解除、ということですね。
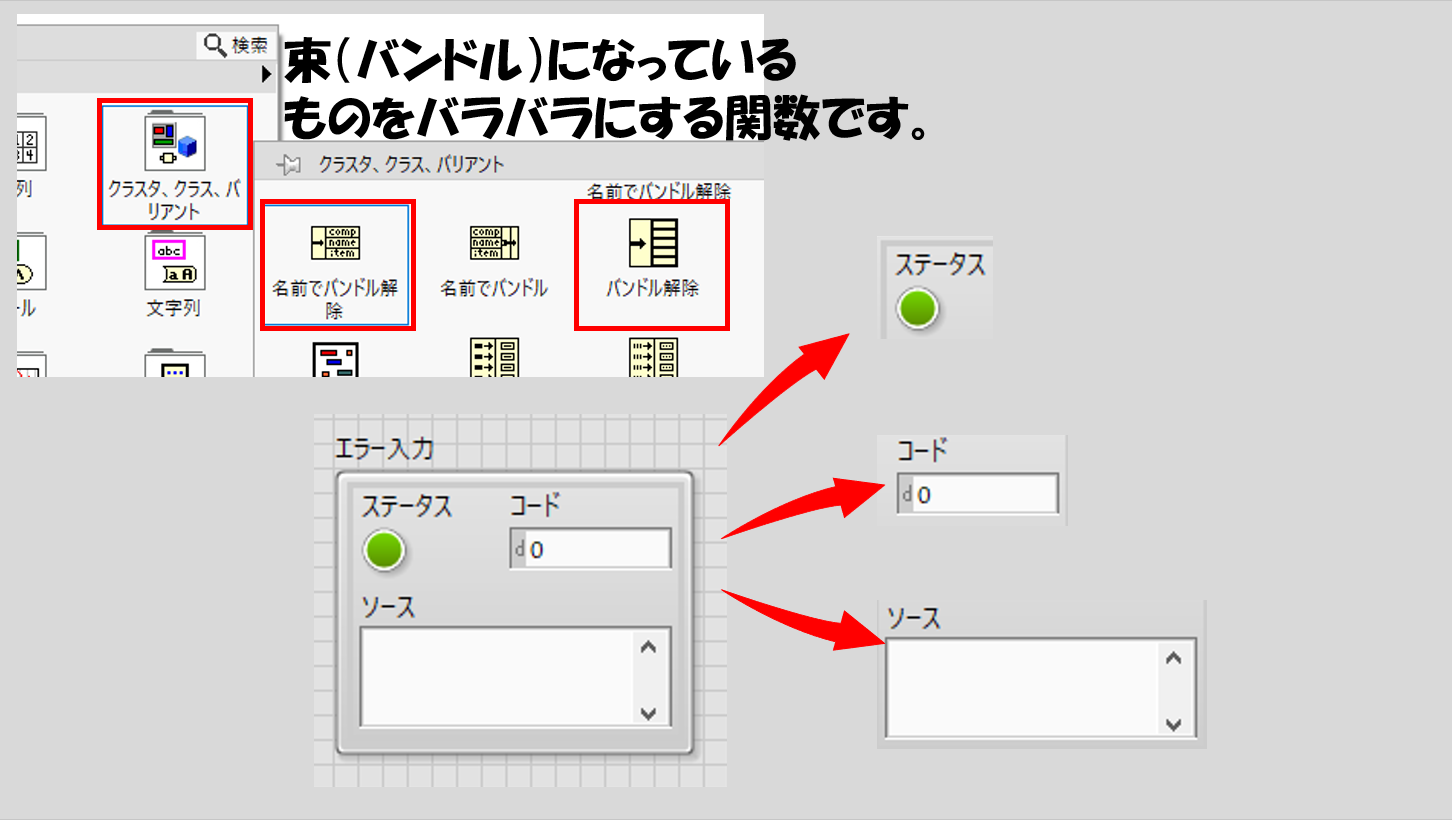
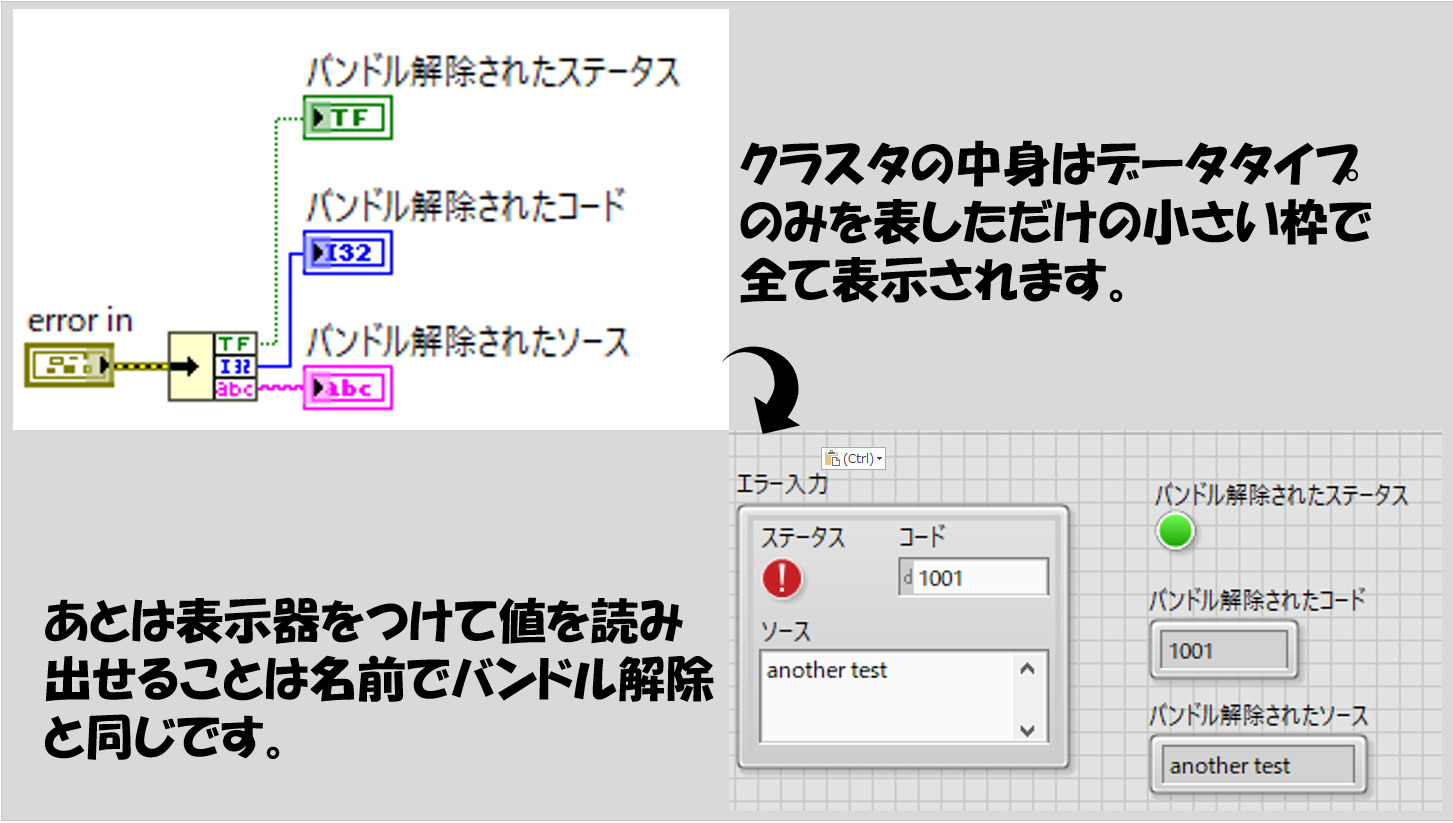
ブロックダイアグラムで関数パレットのクラスタパレットに「名前でバンドル解除」と「バンドル解除」があります。試しに名前でバンドル解除を置いて、これにエラークラスタの制御器をワイヤで配線します。
すると、緑色の文字でstatusと表示されました。Statusの部分をクリック、あるいは名前でバンドル解除の枠を下に引き伸ばすとその他のエラークラスタ内の要素も表示されます。これらの名前でバンドル解除の関数から各要素が取り出せます。
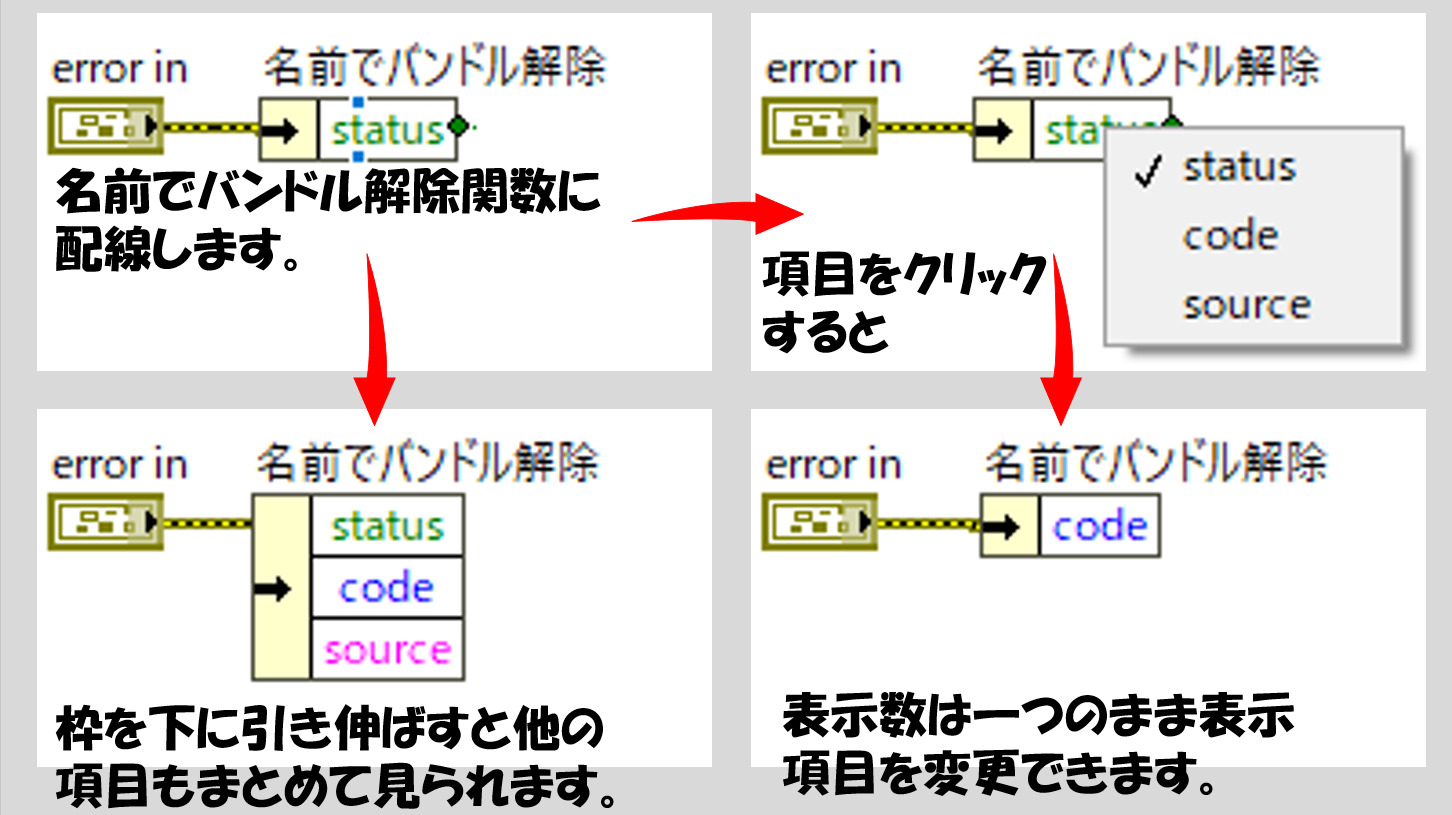
ここまでできたら、あとは個別の項目に対して表示器を付ければ中身を別個取り出すことができます。
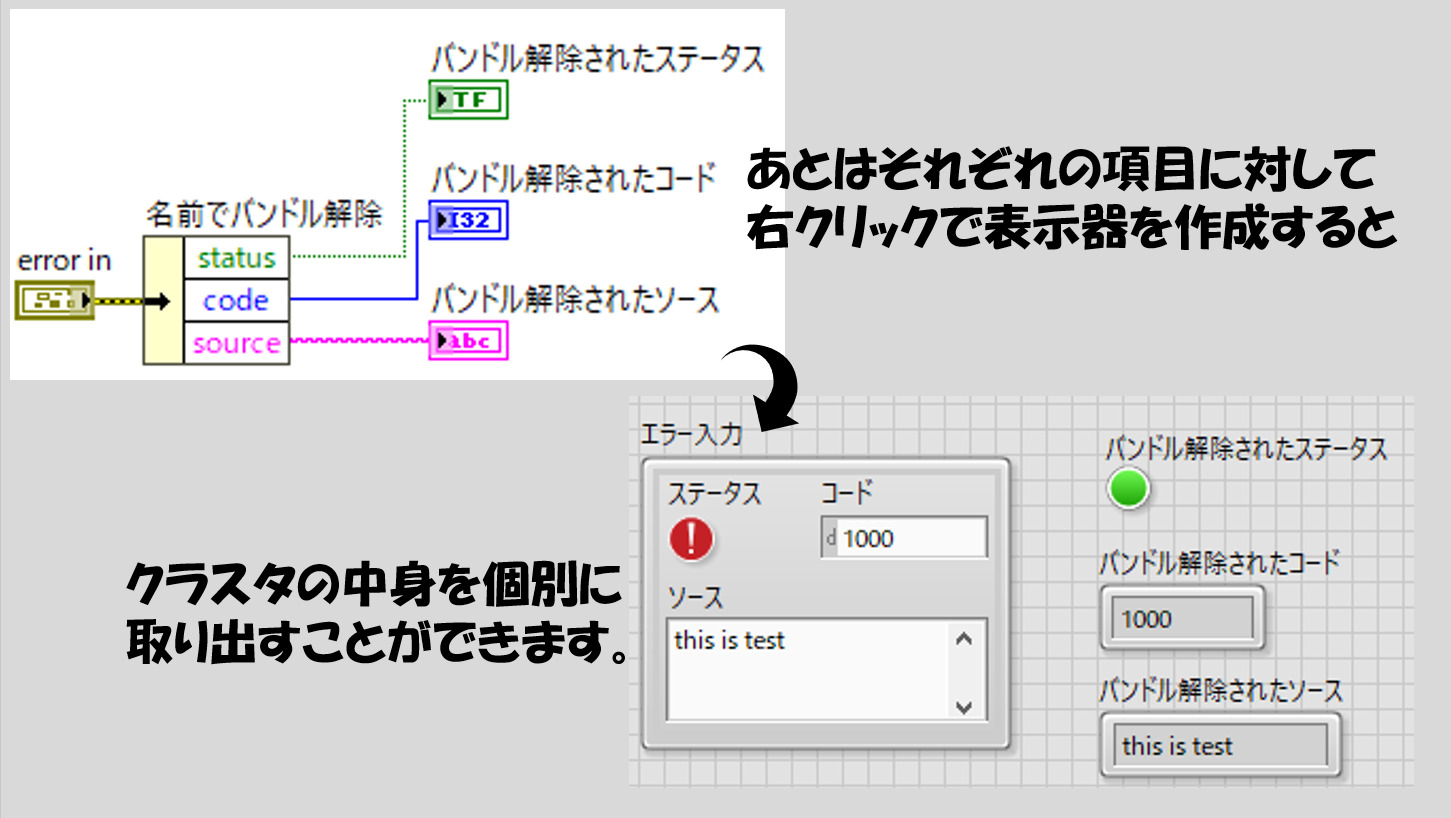
一方で、バンドル解除の関数を使用すると、エラークラスタの各要素の名前の代わりに小さいアイコン等が表示されると思います。これは、クラスタ内部の順番(status、code、sourceの順)で一度に各要素を取り出せるような状態です。
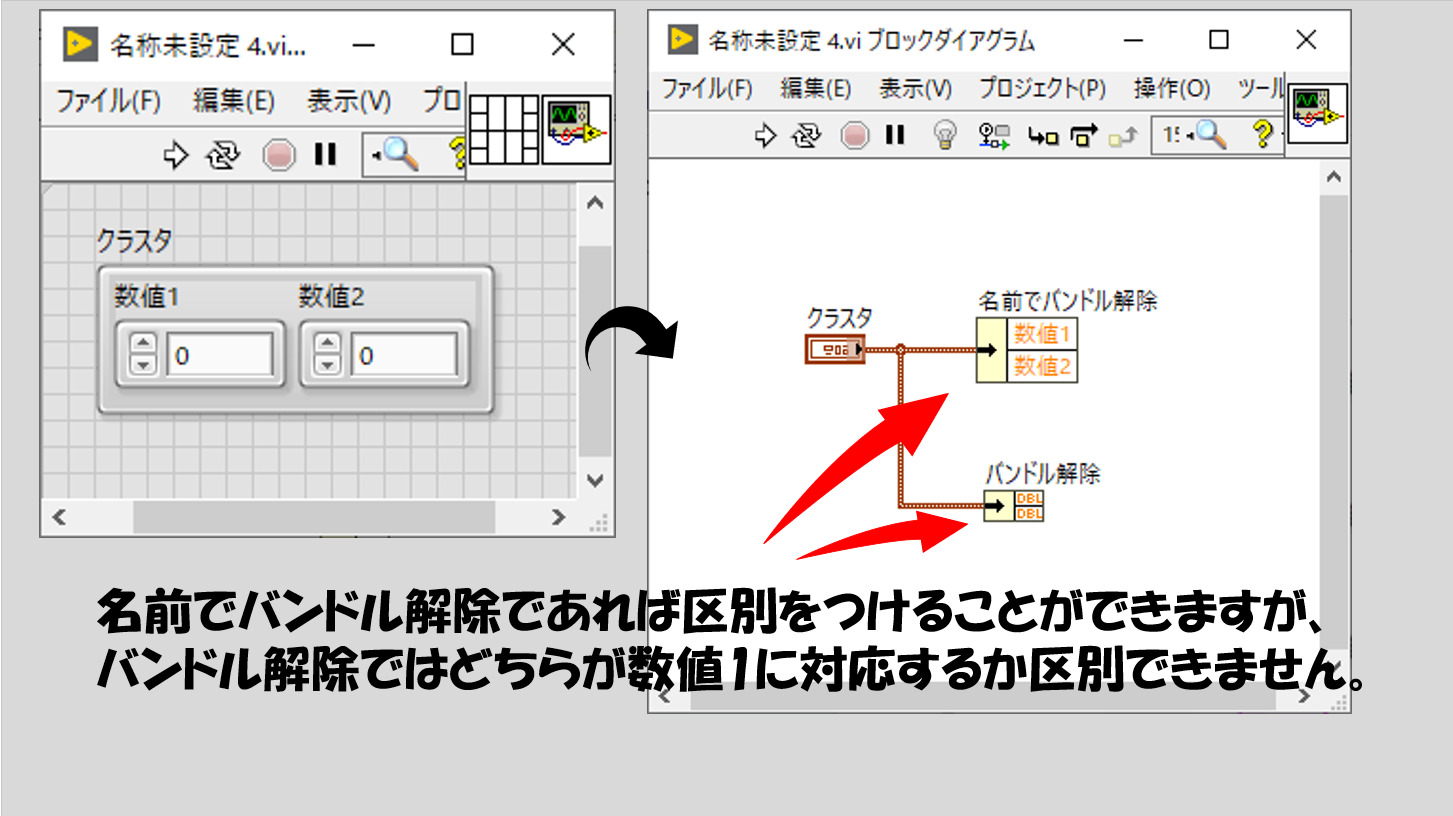
名前でバンドル解除、バンドル解除どちらを使っても結果は同じです。同じですが、名前でバンドル解除の方が確実にプログラムを作るときの間違いは少ないと思います。
たとえばあるクラスタに数値制御器が2つあったとして、これをバンドル解除で扱うと、順番がわからなければ混同してしまうことになりかねないからです。
ではいつバンドル解除の関数を使用するか、ですが、こちらについてはスペースの都合や順番を気にしなくても混同しないケース(例えばクラスタ内に重複したデータタイプの項目がないとき)に使用する感覚です。
クラスタ内に値を入れる
ブロックダイアグラムでバンドル解除の関数パレット上に「バンドル」の関数があったことに気づいた方も多いと思います。こちらは解除の反対の役割を持つ関数で、クラスタ内のデータに値を書き込むことができる関数です。
解除に関しては「名前で」がつくものとつかないものとで見た目に差はあれど挙動に違いはなかったのですが、値を書き込むバンドルの方は「名前で」がつくつかないで若干扱い方が異なります。
まず、「名前でバンドル」の場合です。この関数を使用するには、クラスタ(の定数や制御器)が常に必要になります。
まずは名前でバンドルをブロックダイアグラム上に置いてみましょう。一か所だけ、上側にノードが表れるのがわかるでしょうか?ここに「どんなクラスタに値を入れるか」というクラスタの形式を配線します。
これもエラークラスタを例にやってみます。エラークラスタを配線すると、statusと表示されると思います。これは左側に配線できるので、このstatusに何か値(この場合はTRUEかFALSE)を配線できるということになります。

ここでポイントは、なぜstatusという名前が表れたか、です。・・・そういうクラスタを配線したからですよね?
そうなんです、「名前でバンドル」の字のごとく、「名前」で扱うためにはそもそもその名前とその名前に紐づいたデータタイプが必要なので、それを入力クラスタとして教えないといけないわけです。
これが配線されていないと、上の図のようにプログラムの実行ボタンは壊れてしまいます。
入力クラスタにクラスタの定義を入れたら、あとはそれぞれの項目に制御器や定数で値を渡してやると、名前でバンドル関数の出力として、入力クラスタの各項目に制御器や定数の値が反映されます。

なお、すべての項目(上の図でいうところのstatus、code、source)に入力が必要というわけではありません。入力がない項目については、出力されるクラスタでは入力クラスタの値がそのまま使用されます。
一方で、「バンドル」の関数は名前を指定する必要がありません。そのため入力クラスタを必要とせず、最初から好きなように組み合わせたいデータタイプをどしどし配線してクラスタを生成することができます。
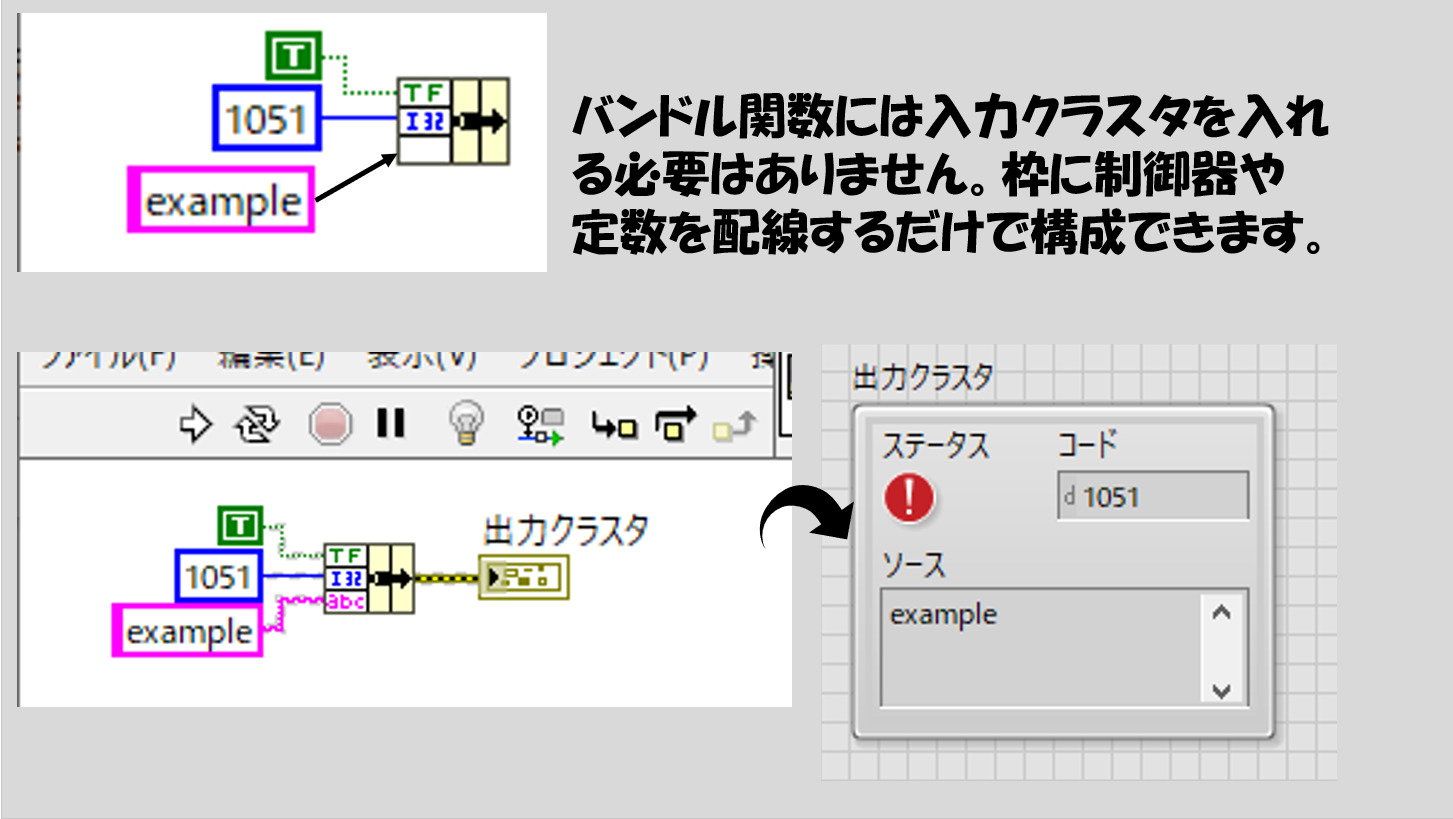
また、「名前でバンドル」と同様に、あるきまったクラスタを配線することもできます。この場合は、そのクラスタの持つ順番通りに値を入力できる状態となります。
「バンドル」関数でクラスタを作成する際に、各データにラベルを付けていた場合、結果として作成されたクラスタ内の制御器あるいは表示器にはちゃんと名前が付属しています。例えば「バンドル」の結果を「名前でバンドル解除」すると名前を選べるようになっていることがわかります。

このようにして「名前で」がつくつかないでバンドルの操作はクラスタを必要とするかしないかが異なります。
実際のプログラムでは、プログラムの中で新たにクラスタを作る場面は少なく、プログラムを書いている時点で必要なクラスタは定数等で用意しているため、「名前で」の「バンドル」「バンドル解除」を使用する場合が多いかと思います。
ただし、例外的に名前にこだわらずにクラスタタイプを用意する必要があるケースがあります。(前回扱ったXYグラフの作成がこれにあたります)
クラスタが必要な理由
ここまで見てきて、「クラスタの操作についてはわかった。でもエラークラスタ以外にどんな場面で使うの?」と疑問に思った方がいるかもしれません。
便利とは説明しましたが、なんの役に立つのかわからないし、覚える必要ないのでは?と私も最初クラスタの操作を習ったときにそう思いました。
確かにこれ、プログラムを作るときに絶対に必要かといわれると、正直知らなくてもプログラムは書けてしまうんです。だって一つ一つのデータをそのまま扱えばいいわけですから。

でも、プログラムってわかりやすさが大切なんです。「これとこれは関連したデータですよ、だからまとめています」とした方が、それらのデータは圧倒的に扱いやすくなるんです。
例えば、正弦波のデータを生成する関数に、「サンプリング情報」というクラスタ入力があります。
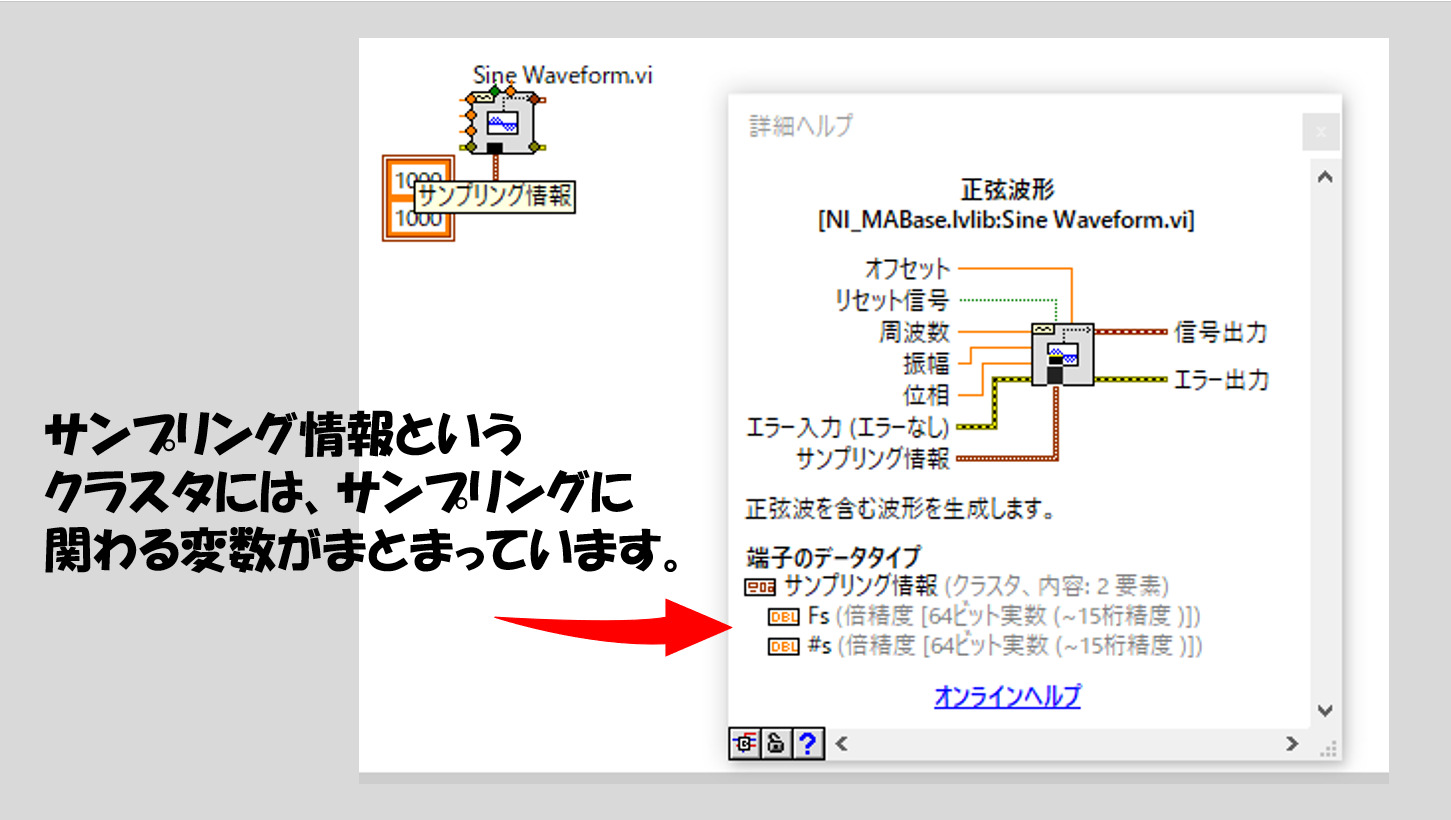
詳細ヘルプでこのクラスタの中身を見ると、Fsと#sと書いてあります。それぞれ、サンプリング周波数とサンプル数を表しています。何それ、という方もいると思いますので一応補足しておくと、
- サンプリング周波数:各データ点同士の時間間隔の逆数
- サンプル数:データ点の合計
のことですね。これらが変わると、同じ正弦波(周波数1)でも表現のされ方やデータの個数が変わるので、グラフ表示した際に以下のような結果になります。
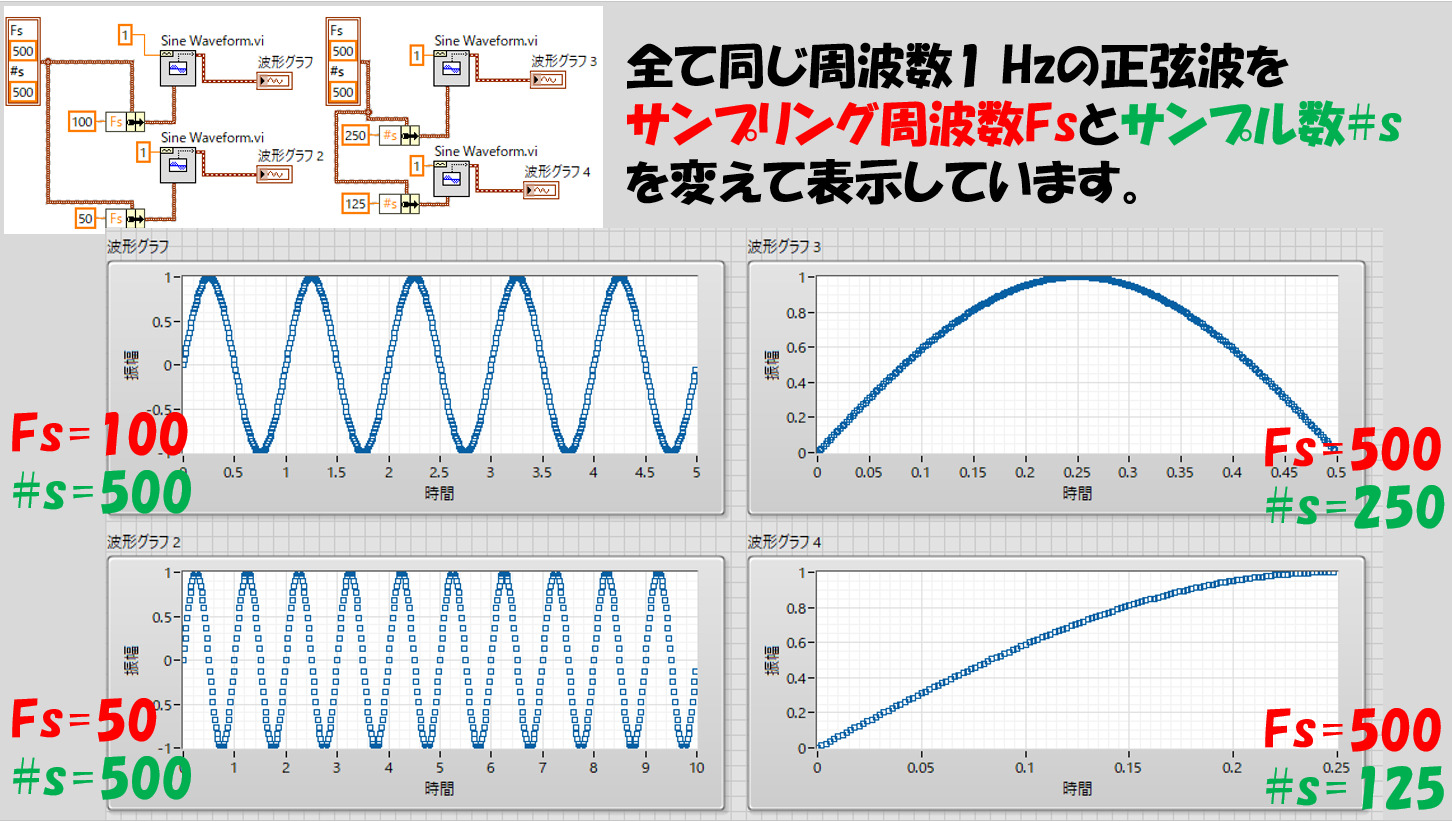
これらの値はこの正弦波発生の関数から出る波形のデータの様子に大きく関係してきます。どちらも波形データの特徴を決めるために必要な情報であり、ひとまとまりになっています。
二つの量がバラバラになっているより、「サンプリング情報」としてまとまっている方がわかりやすいですよね。
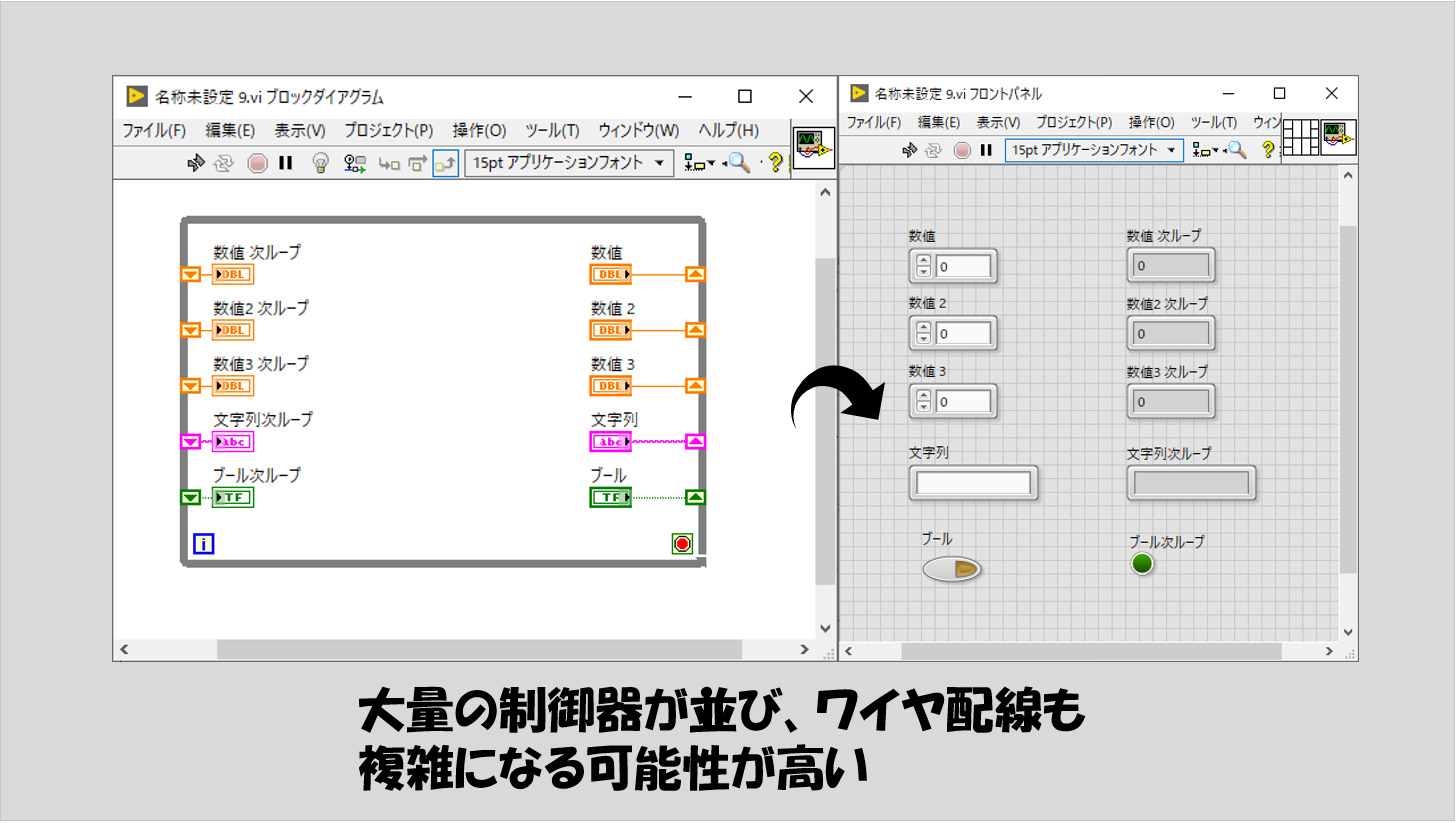
見やすさでいくと、ループのところで紹介したシフトレジスタとの相性もあります。例えば、数値3つとと文字列とブールがあるまとまったデータを表しているときに、これらをループ内で使用したいと考えたとします。シフトレジスタを使った場合に、以下のようになります。
でも、これらが関連があるということでクラスタにまとめると、もちろんクラスタだってシフトレジスタに対応しているのでこのようになります。
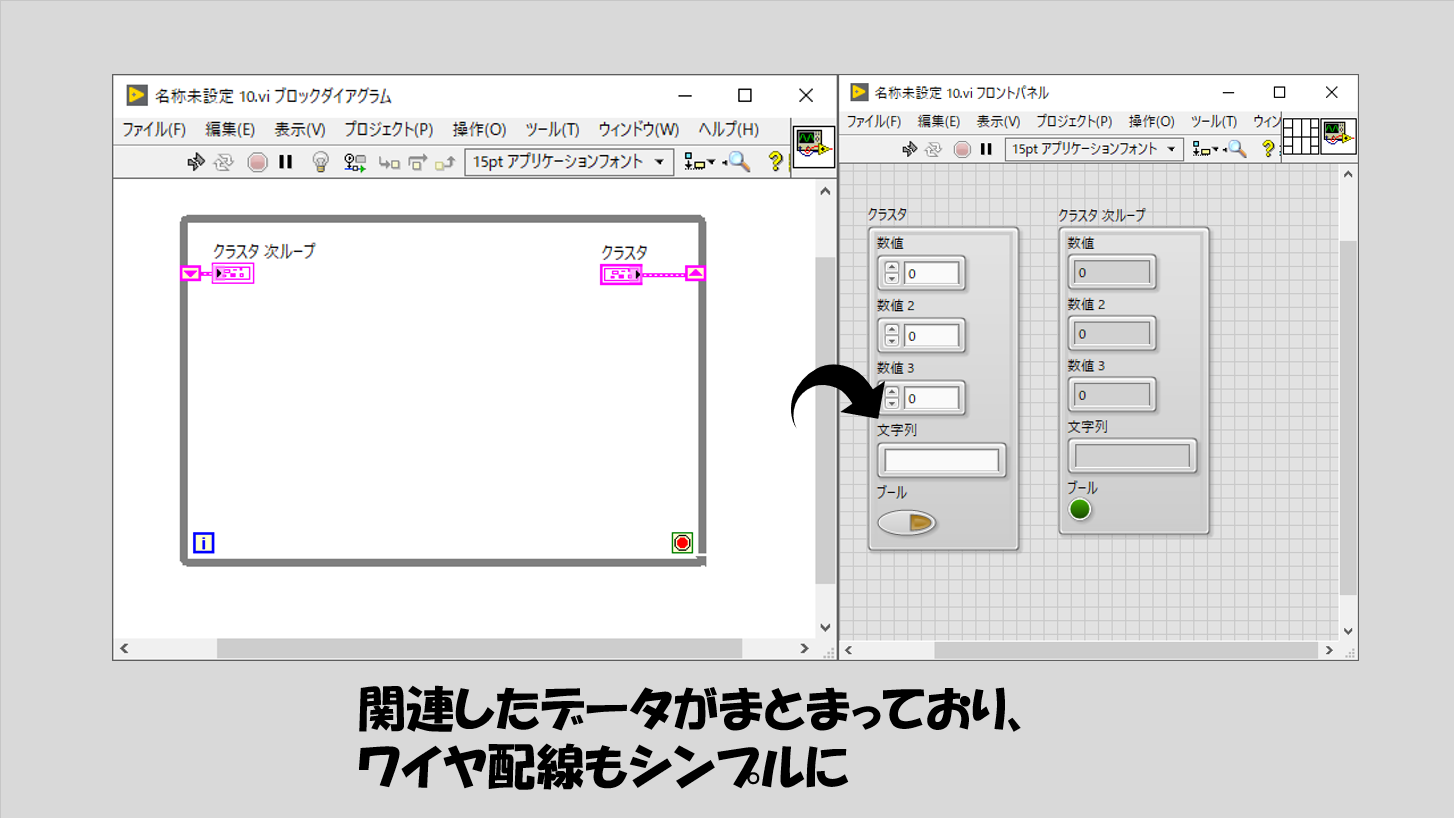
見やすさはけた違いにクラスタを使用したほうが良くなります。ワイヤが多くあるとそれだけ見にくくなりデータの流れも追いにくくなるのでこの工夫は大切です。
冒頭の方で、「新しいデータタイプを作り出すという感覚」と紹介しました。自分のプログラムで専用に使用する、見やすい制御器あるいは表示器としてクラスタを扱おうとする意識はLabVIEWでプログラムを書く上で意識しておいて損はありません。
さらに、「サブVI」を作る時にもクラスタは活躍します。サブVIとは自分でオリジナルの関数を作るといったイメージなのですが、これについては今後扱っていきますのでそのときにまた紹介します。
さて、見やすさを意識したプログラムが書けるようになったところで、プログラムの基本構造としてプログラムの構造でループと同じくらいよく使用する場面のある、条件分岐を学び、さらに作れるプログラムの幅を広げましょう!
と、言いたいところなのですが、ループに配列が相性が良かったように、条件分岐にも相性のいいデータタイプ、列挙体がありこれはまだほとんど扱っていませんでした。なので次回まずは列挙体を使えるようになってからその後に条件分岐に入ろうと思います。
もしよろしければ次の記事も見ていってもらえると嬉しいです。
ここまで読んでいただきありがとうございました。
コメント